
让AI实现举一反三 NVIDIA推出全新TAO工具套件3.0版本 原创
如今AI应用已经无处不在,如何更好更快地开发出AI应用便成为日益重要的挑战。众所周知,不管是机器学习还是深度学习都需要训练样本进行模型构建,而在许多实际应用中,重新收集所需的训练数据并重建模型的代价是非常昂贵。
近日,NVIDIA发布了多个可直接用于生产的预训练模型和TAO工具套件3.0开发者测试版,以及DeepStream SDK 5.1。此次发布包括一系列新型预训练模型。它使开发人员能够使用NVIDIA预先训练好的模型,这些模型具有支持对话式AI应用的创新功能,提高了深度学习训练工作流程的效率和准确性,可提供更加强大的解决方案来加速开发者从训练到部署的整个过程。

举一反三的学习能力
目前,智能视觉和语音功能服务已经成为主流,几乎影响了我们日常生活的方方面面。AI 视频和音频分析正在增强从消费类产品到企业服务等各种应用,包括家用智能音箱、零售店中的智能自助服务终端或聊天机器人、工厂车间的交互式机器人、医院的智能患者监测系统以及智慧城市的自主交通解决方案。不过构建和部署这些解决方案需要完成大量技术工作,例如收集和采集相关数据集,以及为实现高精度、大规模部署时的实时性能和可管理性而对AI模型进行大量训练等。
在这种情况下,我们需要在任务域之间进行知识迁移(Knowledge Transfer)或迁移学习 (Transfer Learning),避免高代价的数据训练与标注工作。而迁移学习把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。
作为一种机器学习方法,迁移学习把为任务A开发的模型作为初始点,重新使用在为任务B开发模型的过程中。由于被赋予了人类特有的举一反三的智慧,深度学习中在计算机视觉任务和自然语言处理任务中将预训练的模型作为新模型的起点是一种常用的方法。
利用第三方预先训练好的模型的好处是非常多的,比如不用自己构建训练数据进行模型旋律,节省IT建设投入,同时也不用团队成员学习众多的开源深度学习框架。虽然选择预先训练好的模型会带来诸多好处,但是这些模型经常存在一些问题:现成的模型在特定的应用领域中精度较低或者没有针对GPU进行优化等。
针对这些问题,NVIDIA TAO工具套件提供各种预训练AI模型和内置功能(例如迁移学习、裁剪、微调和量化感知训练)帮助AI应用开发者和软件开发者加速AI训练。开发者可以使用PeopleNet、VehicleMakeNet、TrafficCamNet、DashCamNet等专用模型为几种流行用例构建高精度AI。
加速端到端AI工作流程
如今,AI已不再仅仅只停留在研究阶段,而是已经被应用于各企业机构中,帮助它们解决实际问题。但是,开发和部署AI应用程序是一项具有挑战性的工作。对于开发者、初创公司和企业而言,从头开始创建一个模型不但耗时耗力,而且成本高昂。NVIDIA TAO工具套件是一个能够消除AI/DL框架复杂性,无需编码就能更快构建生产级预训练模型的AI工具包。TAO工具套件通过NVIDIA为常见AI任务开发的多用途生产级模型或者ResNet、VGG、FasterRCNN、RetinaNet和YOLOv3/v4等100多种神经网络架构组合,使用自己的数据对特定用例的模型进行微调。所有模型均可从NVIDIA NGC获得。
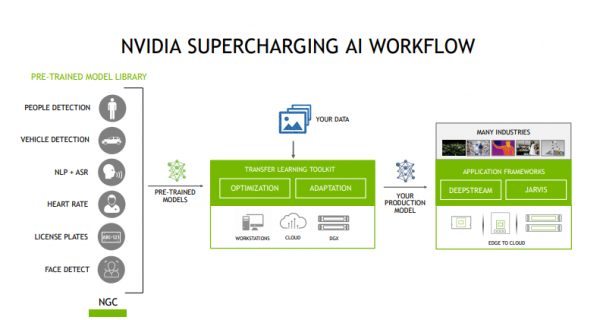
预训练模型加速了开发人员的深度学习训练过程,并且减少了大规模数据收集、标记和从零开始训练模型相关的成本。开发者选择NVIDIA提供的预先训练好的模型,然后结合自己场景或者用例的数据,就可以得到输出模型。迁移学习后得到的模型可以直接进入到深度学习应用/项目的部署阶段。
预训练模型和TAO工具套件 3.0(开发者测试版)提供了全新视觉AI预训练模型:车牌检测与识别、心率监测、手势识别、视线估计、情绪识别、人脸检测、面部特征点估计;通过自动语音识别(ASR)和自然语言处理(NLP)的预训练模型支持对话式AI用例;选择流行的网络架构进行训练,如EfficientNet、YoloV4和UNET;经过改进的PeopleNet模型可以检测困难场景,比如坐着的人和旋转/扭曲的物体等。
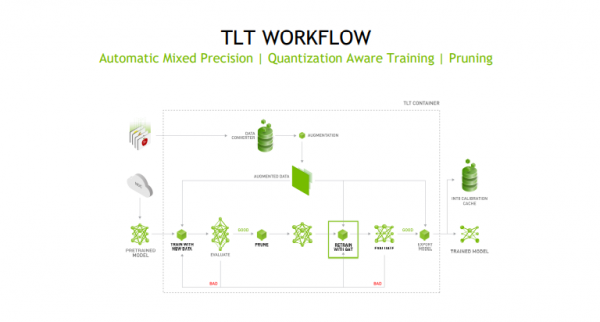
TAO工具套件包提供了端到端的深度学习工作流,与NVIDIA的产品实现了深度集成,在异构多GPU环境下模型训练或调整效果非常好,并且训练处的模型可以直接部署到Tesla、Jetson等产品上面,加速深度学习训练,更好地帮助企业快速上线AI应用。特别是其支持具有第三代张量核心的NVIDIA Ampere GPU,更好地确保性能表现。
结语
从自动驾驶汽车到药物发现,人工智能正成为主流,并迅速渗透到每个行业。为了加速端到端的AI工作流程,企业需要一个统一的平台来使更快地投入生产。NVIDIA一直致力于打造一个AI加速平台,这除了我们熟知的GPU硬件产品,也包括AI软件堆栈例如CUDA、NVIDIA深度学习库和人工智能软件等。如今,TAO工具套件新版本的推出可以更好地帮助AI开发者创造高性能产品、加快产品的上市速度。
来源:至顶网人工智能频道
好文章,需要你的鼓励


Decart发布Oasis 3世界模型,为机器人训练注入真实感
前沿AI研究机构Decart发布最新世界模型Oasis 3,旨在弥合虚拟仿真与物理AI之间的鸿沟。该模型将超写实交互图形能力与强大物理引擎相结合,可生成动作驱动的视频流,支持多视角环境模拟,延迟低于200毫秒。开发者能够借助自然语言提示,快速构建多样化极端场景,有效解决机器人和自动驾驶领域长期存在的"仿真到现实"差距问题,大幅降低物理AI训练成本。

当AI学会“自学成才“:无需人类喂养的智能代理如何在真实世界中越战越强——来自理海大学等机构的最新突破
OpenSkill是一套让AI代理无需人工监督即可自主成长的框架,通过从互联网获取知识、自建虚拟考题反复练习,实现真正的开放世界自我演化。

Visual Components 5.1发布:工厂仿真软件新版本支持大规模自主生产环境验证
Visual Components正式发布5.1版本工厂仿真软件,重点引入高精度物理仿真与可扩展机器人协同调度能力,支持在同一环境中同时模拟数百台自主移动机器人、自动导引车及人员的运行状态。新版本还将仿真性能提升至前代的10倍,新增Allen-Bradley PLC支持及Nachi、Epson机器人虚拟调试插件,并将脚本环境升级至Python 3。该软件旨在帮助制造商在实际部署前完成系统验证,降低调试风险,缩短投产周期。

当AI评委同时打多份分时,它的判断力会崩溃吗?——来自IIT焦特布尔与亚马逊的联合研究
论文研究了AI评委同时优化多个评判维度时的两大失败原因:梯度稀释与指令干扰,为多目标提示词优化提供了系统性诊断框架。
2021
03/01
09:55
分享
点赞

Decart发布Oasis 3世界模型,为机器人训练注入真实感
AI既令人兴奋又让人焦虑,企业究竟该如何面对?
芬兰与瑞典联手推进6G韧性联合研究计划
微软公布智能体AI系统七大新型安全漏洞
GitHub Copilot推出桌面应用与画布功能,同步启用按量计费模式
谷歌DeepMind分拆公司如何追踪隐藏的药物靶点
Snowflake峰会观察:智能体浪潮下平台的核心竞争力之争
亚马逊"故事回顾"功能正式向美国Kindle设备及iPhone应用推出
Anthropic推出聚焦生命科学的全新大语言模型
Motive AI Coach智能驾驶辅导系统正式进军英国市场
联想世界杯嘉年华盛大启幕!AI+体育引领中国足球产业升级
Google Cloud深度解析AI智能体治理难题
NVIDIA Blackwell 现已在云端全面可用
为“代理式AI”装上“护栏” NVIDIA打造“三重防线”
黄仁勋现身北京致辞:60年后,计算机正被重新定义
CES 2025 | NVIDIA Isaac GR00T Blueprint 让人形机器人“加速进化”
未来,就在我们手中
CES 2025 | 代理式AI崛起:NVIDIA定义下一代“代理式 AI Blueprint”
深度学习最佳 GPU,知多少?
NVIDIA推出用于多语言生成式人工智能的NeMo Retriever微服务
NVIDIA 初创加速计划 | 2024 NVIDIA 创业企业展示完美收官!
老黄掏出“迷你版AI超算”,每秒67万亿次运算,仅售2070元人民币
