
英特尔推出AI参考套件,推动构建AI触手可及的未来
最新动态:得益于英特尔与埃森哲的长期合作,英特尔现推出了一套共计34个的开源AI参考套件,帮助开发者和数据科学家更快、更轻松地部署人工智能(AI)。每个套件均包含面向AI优化的模型代码、训练数据、机器学习流水线、库以及oneAPI组件,让企业可以在采用不同架构的本地、云端和边缘环境下灵活应用。
“英特尔AI参考套件为数百万开发者和数据科学家在健康和生命科学、金融服务、制造业、零售业等诸多领域开发和扩展AI应用,提供了简便、高效且经济实惠的方式。英特尔致力于通过广泛的产品组合——基于AI加速的处理器和系统,加以对开放AI软件生态的投入,推动构建一个让AI触手可及的未来。该参考套件采用了英特尔AI软件产品组合的丰富组件并基于开放、基于标准的oneAPI多架构编程模型所打造。”
——李炜博士,英特尔副总裁兼人工智能和分析部门总经理
重要意义:英特尔AI参考套件采用oneAPI开放的、基于标准的异构编程模型和英特尔端到端的AI软件产品组合的组件共同构建,其中包括英特尔®AI分析工具包和英特尔®发行版OpenVINO™工具套件,让AI开发者能够简化运用AI编写应用程序的流程,增强现行智能解决方案并加速部署。结果证明,相较于传统的模型开发流程,英特尔AI参考套件带来了显著的性能提升,同时让工作流程更为省时且高效。
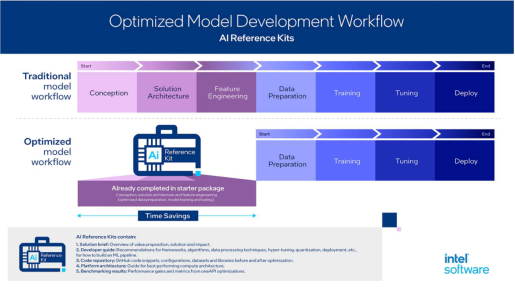
预配置的套件简化了横跨消费品、能源和公用事业、金融服务、健康和生命科学、制造业、零售业和电信业等行业的AI开发。其惠及各行各业的部分示例如下:
●使用专为企业对话式AI聊天机器人交互设置而设计的AI参考套件,用户可以通过oneAPI优化,在批处理模式下将推理速度提升高达45%。1
● 专为生命科学领域的视觉质量控制检测自动化而设计的AI参考套件,在经过oneAPI优化后,视觉缺陷检测的训练速度提升高达20%,推理速度提升高达55%。2
● 对于用于开发者预测公用事业资产的健康状况并提高服务可靠性的AI参考套件,能将预测准确度提升高达25%。3
AI参考套件可以将解决方案的时间从数周缩短到数天,帮助数据科学家和开发者以更快的速度和更低的成本进行模型训练,克服专有环境的限制。在oneAPI驱动下,AI工具和优化能够更大限度地提高开放式加速计算应用的可移植性。
埃森哲董事总经理John Giubileo表示:“与英特尔合作为开源社区开发AI参考套件,促使我们客户能够以更高效地方式运行AI工作负载。这些基于oneAPI构建的套件旨在为开发者提供便捷和高效的AI解决方案,从而降低项目复杂性,缩短其在各行各业的部署时间。”
未来展望:英特尔将基于社区反馈和贡献,持续更新参考套件。包括视觉质量检测、企业对话式AI聊天机器人设置、预测资产健康分析、医学成像诊断、文档自动化、以及AI结构化数据生成等。
参考资料:
1 https://github.com/oneapi-src/customer-chatbot
2 https://github.com/oneapi-src/visual-quality-inspection
3 https://github.com/oneapi-src/predictive-asset-health-analytics
注意事项和免责声明:
性能会因用途、配置和其他因素而异。更多信息请参见www.Intel.com/PerformanceIndex。结果可能会有所不同。
性能结果基于所示配置的测试日期,可能不反映所有公开可用的更新。
英特尔不控制或审计第三方数据。您可以参考其他来源以评估准确性。
来源:业界供稿
好文章,需要你的鼓励


SpaceX疑似向投资者展示AI手持设备原型,马斯克否认
据《华尔街日报》报道,SpaceX在IPO前曾向投资者展示一款手持AI设备原型,该设备比iPhone更纤薄,搭载高通骁龙芯片及基于xAI技术的专有操作系统。对此,马斯克在X平台发文称报道"完全失实",但未作进一步说明。报道指出,该项目仍处于早期阶段,设计可能调整,且不保证最终量产。若属实,这将是SpaceX在火箭与卫星互联网业务之外的最大跨界尝试。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

Meta计划对外出租AI基础设施,股价大涨近9%
据彭博社和CNBC报道,Meta计划将其内部未使用的AI基础设施租赁给其他公司,消息一出,Meta股价上涨8.8%,而AI云服务商CoreWeave和Nebius分别下跌13.9%和17%。Meta本财年数据中心资本支出预计高达1450亿美元,旗下正在路易斯安那州兴建代号"Hyperion"的超大数据中心,将消耗5吉瓦电力。Meta还可能通过该平台提供自研芯片及大语言模型Muse Spark的托管访问服务。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2023
07/27
13:42
分享
点赞

SpaceX疑似向投资者展示AI手持设备原型,马斯克否认
Meta计划对外出租AI基础设施,股价大涨近9%
Instagram算法定制功能升级,用户可更精准掌控内容偏好
AI时代Chiplet设计中不可或缺的可观测性层
从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
