
奥地利立法标识符的实践处理:挑战与应对策略
为提升欧盟法律信息管理的效率、互联互通性、易获取性和标准化水平,欧盟于2012年12月建立了欧洲立法标识符(ELI)工作组,旨在构建一个一体化、高度互动的法律文档识别系统。通过采用通用资源标识符(URI)和标准化元数据等技术手段,使法律信息的检索与获取更为便捷,在不同国家和语言环境下实现互联互通。
奥地利作为欧盟成员国之一,积极响应ELI倡议,并将其融入国内法律平台。奥地利联邦数字与经济事务部(BMDW[1])运营的国家级法律信息服务平台,即奥地利法律信息系统(Rechtsinformationssystem des Bundes,简称RIS[2]),在ELI实施之前已收录了包括法律法规、法院裁判和地方性法规等来自奥地利联邦和地方的法律文件。并且通过REST API[3]提供数据的访问接口,使用户能够以JSON格式访问RIS的法律数据。同时,RIS支持多种文档格式,包括HTML、XML、RTF和PDF等,以便用户查看文档。然而,这些数据库各自独立运行,并未建立有效的连接,由此造成法律信息之间的交互受限、数据存在不一致性,以及法律数据之间缺乏有效关联等问题。
为应对这一挑战,奥地利通过实施ELI并优化本地标识符,构建法律知识图谱等一系列高效措施改善法律数据管理系统,实现数据之间的相互关联,提升数据交互和传播效率。本文将对Erwin Filtz、Sabrina Kirrane和Axel Polleres所作的《The linked legal data landscape: linking legal data across different countries》一文进行解析,探讨奥地利在实施ELI的首个阶段任务中所面临的挑战及其应对策略。
背景介绍
根据欧洲立法标识符任务组(ELI TF)发布的《The European Legislation Identifier Good Practices and Guidelines》实施指南,各法律信息提供者在实施ELI的过程中需要根据本国的具体情况确定需求、评估资源、制定相关的实施方案,并采用渐进迭代的方式推进ELI的落实。ELI的实施总共分成四个阶段,每个阶段都有需要实施的任务和要求。
第一阶段,该阶段的任务是为法律创建一个独特的标识符,使得人类和计算机都能够理解和阅读这些标识符,并且要确保这些标识符与现有的技术标准相兼容。第二阶段,这个阶段在符合ELI的本体论的基础上,设计描述法律信息的方法,其中包括了法律文件的结构、内容、语言等方面的元数据结构。第三阶段,该阶段的目标是通过使用RDFa或JSON-LD等标准语法,在互联网上传播第二阶段设计的元数据,以便更广泛地共享和利用这些数据。最后是第四阶段,任务是落实ELI的规范性要求,确保数据使用者可以从特定的ELI提供者那里检索到完整的ELI元数据集,并获得每日更新的信息,以提升数据使用者获取元数据的完整性、准确性和实时性。
任务组针对各国数字化程度的不同,为每个阶段所需要实施的任务和数据量提供了参考表,以便成员国根据本国情况自愿实施全部或部分阶段的任务。奥地利已经完成了第一个阶段的任务。在这个过程中,奥地利也面临多重困境。比如法律文件的信息缺失问题,数据孤岛,存储数据的冗余等。应对这一系列挑战,奥地利在推动ELI[4]和ECLI[5]的同时,根据国情细化了法律知识图谱。他们创建了特定的属性,如专有词汇表AustroVoc,并实现了跨语言对齐,以确保法律术语和概念在不同语言间的一致性。
奥地利存在的挑战
(一)非结构化/缺失信息
法律文件的信息通常分为结构化元数据和非结构化文本两部分。结构化元数据是指以明确定义的格式和结构存储的数据,例如文件的标题、日期、落款等。而非结构化文本则是指没有明确格式或结构的自然语言文本,例如法院判决中的具体内容。
在法律文件中,有些重要信息可能只存在于非结构化文本中,例如引用的法律条文。这些引用通常不会被提取到结构化元数据中,而是包含在文本内容中。此外,一些文件之间的连接关系可能仅在文本中隐含存在,如不同法律文件中的相互引用。虽然这些连接关系对于人类读者来说可能比较容易识别,但对于机器来说可能会遇到困难,因为机器需要通过自然语言处理技术来理解和提取这些关系。
此外,即使在结构化元数据中,也可能无法完全捕捉到法律文件中的所有重要信息。例如,在ELI本体[6]中定义了一些强制和可选的属性,用于描述法律文件的各个方面。然而,这些属性只能部分地从文档元数据中构建,有时可能无法覆盖所有的信息需求。所以,在处理法律文件时,需要综合考虑结构化元数据和非结构化文本,以确保获取到尽可能完整和准确的信息。
(二)数据孤岛
欧洲理事会认识到,为了促进法律信息的更广泛传播和访问,必须加强国家机构之间的法律信息交流[7]。然而,当前情况是各欧洲国家的法律信息系统仍然是相互独立的,这导致了数据孤岛的问题存在。数据孤岛指的是各系统之间缺乏互联互通,导致信息无法在不同系统之间流通和共享,从而限制了数据的利用和价值。为了解决这一问题,奥地利项目设定了首要目标,即建立国家内部法律数据之间的连接,使得数据库能够相互交流和共享信息,提高信息的可访问性和可利用性。
(三)冗余数据存储
由于法律文件之间常常存在相互引用的情况,想要对法律信息进行全面搜索往往需要跨越不同的数据库。当前的做法是将额外的信息存储在数据库的附加列中,以支持全文搜索。这意味着,除了存储法律文件的基本信息外,还需要在数据库中添加额外的列,以存储与其他文件的引用关系相关的信息。虽然这种做法在一定程度上可以实现全文搜索的需求,但同时也带来了一些问题。
首先,这种做法导致了数据的冗余存储。因为同一份法律文件可能被多次引用,而每次引用都需要在数据库中存储一份额外的信息。这样一来,相同的信息就会在数据库中重复出现,导致数据冗余,增加了数据库的存储成本和维护复杂度。
其次,在进行数据插入、更新和删除操作时,可能会产生异常情况。由于法律文件之间的引用关系复杂,当其中一个文件发生变化时,涉及该文件的所有引用关系都需要相应地进行更新。如果不加以妥善处理,可能会导致数据不一致或错误的情况发生,影响系统的准确性和可靠性。
面对上述三个挑战时,奥地利确立了三个核心需求使得数据互联互通。首先,必须能够从法律文档的文本中提取出元数据中缺失的信息。比如利用自然语言处理技术等工具,从法律文件中自动提取出主题、相关法律条款等内容,以填补元数据的不完整性,这样的提取过程有助于建立更加全面和准确的法律知识图谱[8]。其次,需要将来自各州的法律数据集成到一个统一的知识库中。用户可以通过统一的接口来访问和查询各种法律信息,而无需查阅多个不同的数据源。最后,使用唯一标识符而不是纯文本引用进行规范化是确保法律知识图谱数据的一致性和准确性的重要手段之一。通过分配唯一标识符,可以避免同一份法律文件在不同的数据源中重复出现,并减少由于引用文本的不一致性而导致的信息混乱和错误。
因此,通过满足这些核心需求,建立并完善法律知识图谱将为法律领域的研究和应用带来重要的进步和改善。这将使法律数据使用者和提供者能够更加有效地利用和管理法律信息资源,为法律决策和数据再开发提供更加可靠和全面的支持。
法律知识图谱建模过程
知识图谱是一种用于表示知识的图形化结构,其中包含实体(如事物、概念或事件)之间的关系。这些关系可以是实体之间的相关性、属性或者其他类型的连接。知识图谱通过图形化的方式展示了知识的结构和关联,使得计算机系统能够更好地理解和利用这些信息。其通常用于语义网、人工智能和自然语言处理等领域,可以帮助机器理解语言、推理和生成新的知识。
然而,法律信息通常以自然文本形式标识,其中包含在机器可读的格式中也不容易获取的信息。为此,ELI建议使用资源描述框架(RDF)来描述特定资源的元数据。通过RDF,可以为资源提供结构化的描述,包括其内容、关系和属性等信息。随后,为了唯一标识这些数据,ELI推荐分配唯一资源标识符(URI)。这些URI可以用于准确定位和引用数据,从而构建知识图谱结构,促进数据之间的联系和交互。
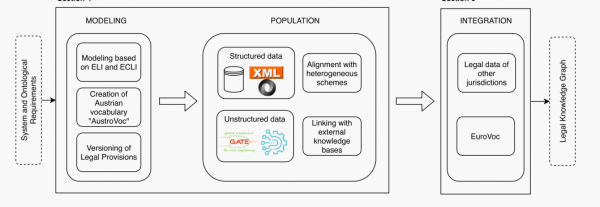
图1:奥地利建模流程图
奥地利建立法律知识图谱的过程中,他们并非从零开始,而是建立在ELI和ECLI的基础之上。这意味着他们利用了欧盟所制定的法律标准作为起点,但同时也根据奥地利国内的法律体系和需求进行了适当的调整和扩展。
首先,针对奥地利的法律体系,他们整合和扩展了ELI本体去构建特有的法律知识图谱。奥地利创建了一个名为AustroVoc的国家词表。这个词表主要包含了未被收录在EuroVoc[9]这样的欧盟术语表中属于奥地利特有的法律术语。ELI和ECLI所提供的是所有欧盟成员国最小的元数据集,因此各成员国需要根据各国法律体系为各国的法律知识图谱创建额外的类和属性,以满足该国具体的需求。
其次,为了确保法律知识图谱的准确性和完整性,他们采取了多种方法来获取来自RIS数据库的结构化和非结构化数据,并对法律文本的内容进行细化。这些步骤有助于确定所需的属性,并为法律知识图谱的构建提供了可靠的基础。
最后,他们整合了来自欧盟的法律数据并对不同语言的词汇进行对齐,例如EuroVoc,从而丰富法律知识图谱。这种跨领域、跨语言的整合为用户提供了更广泛的视野,有助于他们更全面地理解和利用法律知识图谱。
(一)奥地利法律知识图谱建模
1.在EIL和ECLI基础上细化模板体系
ELI和ECLI在设置过程中需要考虑各成员国不同的法律体系,因此对此仅提供了指导性的文件和整体框架为各实施该方案的国家进行参考。为此,奥地利在这个基础上需要根据本国的需求进行调整,比如需要考虑联邦法律以及司法分支的判决。下图2展示了一个奥地利的法律知识图谱模型。在图中,灰色标注的类别代表着特定的属性,而它们之间的箭头表示着各个属性之间的属性关系和相互关联。
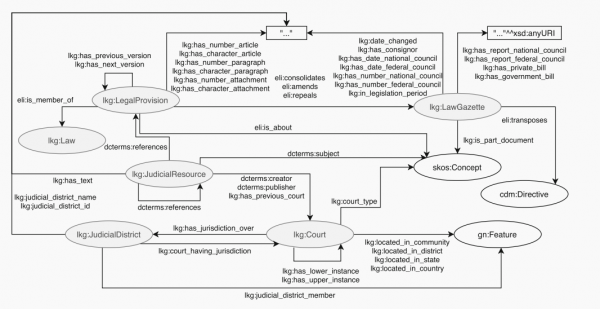
图2:法律知识图谱模型
上图中的Law Gazette指的是法律公报,该公报是用于发布新法律或对现行法律的修订并以一定的文档展示。在法律知识图谱使用 lkg:LawGazette 来表示法律公报,而这个类别是 eli:LegalResource(ELI本体所区分的三大类中指法律基础概念)的子类。同时,在该类别下再扩展新的属性信息比如立法过程的背景信息。举例来说,奥地利在这个部分扩展了法律的变更何时在议会中进行讨论的日期属性(lkg:has_date_national_council)、有关议会讨论的报告的属性( lkg:has_report_national_council),以及这些报告可以在网络上获取(如:lkg:has_report_national_council, lkg:has_report_federal_council)等等。
图中Legal Provision and Law代表法律的具体条款内容。在法律知识图谱中使用lkg:LegalProvision进行标识,并且该类别也属于eli:LegalResource 的子类。奥地利的每一个法律文件都在ELI的基础语法框架内对文本内容进行了更细节的划分。其为每一个条款都设置了编号,并分配了标识符,如下图3所示:
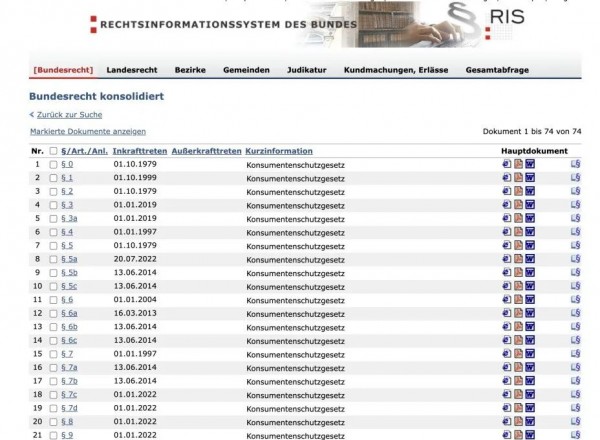
图3:奥地利消费者保护法检索显示图
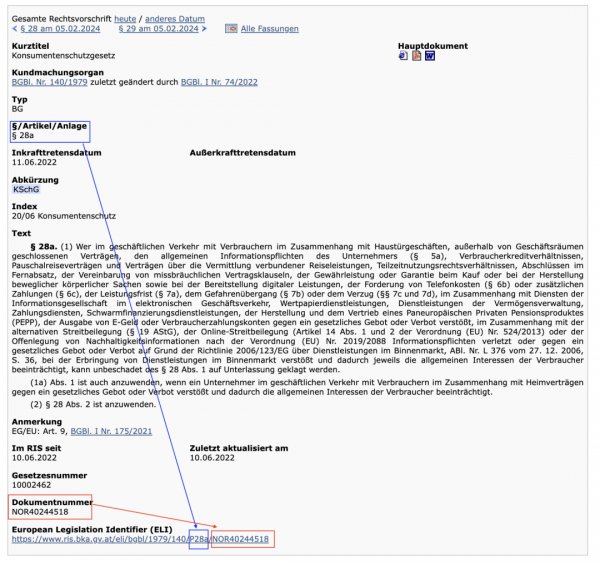
图4:消费者保护法第28a条(§ 28a KSchG)页面截图
图4所示是奥地利消费者保护法第28a条,该条的ELI为https://www.ris.bka.gv.at/eli/bgbl/1979/140/P28a/NOR40244518。在这个ELI的URI中元素中,奥地利将法律文本中的编号信息作为属性进行了扩展(P28),该属性在知识图谱中以lkg:has_number_paragraph进行标识;同时,奥地利在URI中扩展的“a”元素代表字符属性,知识图谱中以lkg:has_character_paragraph进行标识。
除此以外,考虑到法律文件存在历史版本,奥地利的知识普图中也进行了扩展,并以lkg:has_next_version 和 lkg:has_previous_version进行版本属性。而知识普图中的lkg:Law(也是历史版本属性的母项),代表法典属性,是指包含有关相同主题的法规的集合。lkg:LegalProvision和lkg:Law之间的关系通过 ELI 属性 eli:is_member_of 表示。
以中国的法律体系举例,lkg:Law代表的是某一相同类型的法律法规的集合,比如刑法相关主体的法律的集合,在这个母类下面,会区分具体的法律文本(lkg:LegalProvision),比如有中华人民共和国刑法,这两个不同的属性之间的关系用is_member_of来标识,代表刑法是属于法律的子项内容。刑法法律文本中会存在不同的版本信息,这个版本信息会采用lkg:has_next_version 和 lkg:has_previous_version进行标识以细化并建立各版本之间的联系。此外,奥地利在法律知识普图的建立过程中在ELI的基础上对司法判例、法律机构和司法区域等多个领域和部分都进行了细化和扩展,使得法律知识图谱更加完善。
(二)建立奥地利专用词汇表:AustroVoc
ELI任务组(ELI TF)不仅提供ELI和ECLI的统一框架,还鼓励各成员国根据其需求创建自己的分类架构。例如,在ELI提供的属性标识(如eli:type_document、dcterms:type、eli:is_about和dcterms:subject)的基础上,各国可以建立子项来更详细地描述文档类型、文档内容或对法律领域进行分类等。奥地利在这个过程中,基于SKOS(Simple Knowledge Organization System,简单知识组织系统)创建了名为AustroVoc的词汇库,其中包含了专门用于奥地利的术语集合。该词汇表区分三个类型:法院类型(Gericht-typ)、法律索引(Bundesrechtindex)和资源类型(Resource-typ)。
欧盟出版局提供的法院类型在其命名权威列表(NAL)[10]中仅包含欧盟法院,所以无法直接适用于奥地利的法院。因此,奥地利才创建了一个额外的法院类型方案,其中包含了不同类型的奥地利法院。在该文档中对法院类型进行了细化分类,包括公共法庭(例如宪法法院 av:vfgh)和普通法院(例如最高法院 av:ogh)。这些法院负责不同的法律领域,并以分层方式组织。通过添加这些信息,可以便于用户检索特定类型的法院,了解上级或下级法院关系,从而进行更深入的法律分析。
法律索引采用了分层方式组织法律条文,每个法规都被分配到索引中的一个特定条目,并通过属性 eli:is_about 进行关联。这种分层结构使得用户能够更轻松地搜索特定法律领域的法规。举例来说,用户可以通过 av:bri2006 的 §28a KSchG 来查找与消费者保护相关的法规。
为了实现跨司法管辖区的多语言搜索,该系统利用属性 rdfs:seeAlso 将国家法律索引项目与欧洲EuroVoc词表的相应项目进行关联。举例而言,AustroVoc法律索引 av:bri2006(Konsumentenschutz@de)与 EuroVoc 中的 ev:2836(Verbraucherschutz@de)相关联。av:bri2006(Konsumentenschutz@de)是奥地利的词汇表中消费者保护的德语表达,而ev:2836(Verbraucherschutz@de)也是代表着消费者保护的德语表达,但是ELI所提供的版本。同样是消费者保护的含义,在同一种语言下都存在不同的表达方式,为数据的使用者增加理解和建立法律文本关系的障碍。因此,奥地利通过将本国的词汇表与欧盟的词汇表建立联系,有利于数据使用者们能够在多种语言检索到相关的法规信息。
与法院类型类似,欧盟出版局提供的资源类型是也是在欧盟整体层面去设计的一个共同的框架。所以,奥地利使用过程中需要根据自身特定资源方面进行完善。对此,奥地利在其RIS平台中创建了一个专门的词汇表针对不同的文档类型。例如,司法文件可以分为“Entscheidungstext”(判决内容)或“Rechtssatz”(法律规则),后者是一个案例摘要,可以推导出一般法律规则,如下图所示:
图5:司法案例归类图
(三)法律数据图谱填充
一旦确认了本国特有的法律知识图谱的需求,并完成了相应的建模工作,接下来的关键步骤是将具体的法律文本信息填充到模板框架中,以建立法律数据之间的关系。这个过程涉及从结构化数据源中提取信息,并采用特殊技术(如自然语言处理技术)从非结构化文本中抽取信息。
在填充阶段,首先需要从各种结构化数据源中获取法律信息,这些数据源可能包括官方法律数据库、法律文档存档以及其他相关资源。通过提取这些数据源中的信息,可以将法律条文、法规解释、法院裁决等内容填充到法律知识图谱的相应部分中。同时,还需要使用自然语言处理技术来处理非结构化的法律文本,从中提取关键信息并将其与图谱中的相关实体和概念进行关联。
在该阶段需要确保法律知识图谱具有丰富的内容和完整的关联性,以满足用户的查询和分析需求。通过将法律数据填充到图谱中,并建立数据之间的关系,用户可以更轻松地访问和理解法律信息。例如,他们可以通过搜索特定法律条文或主题来获取相关的法律规定、案例法解释或其他相关信息。这种可查询和可分析的特性使得法律知识图谱成了一个强大的工具,能够帮助用户更深入地理解法律体系,并支持法律决策、研究和实践活动。
1.结构化数据
在处理结构化数据时,必须克服数据库架构不匹配的问题,并考虑到每个应用程序的独立性,以确保数据的完整性和准确性。为了满足这些要求,奥地利采用了三种主要方式进行填充:直接填充、间接填充和与外部源相互衔接。
直接填充方法适用于那些不需要经过复杂转换或处理的属性,只需将这些属性直接映射到图谱中的URL中。比如,对于日期属性,奥地利将原始的日期时间格式转换为标准的ISO 8601格式(YYYY-MM-DD),然后将其用于多个属性,包括文档的发布日期、生效日期等。类似地,对于包含文字信息的属性,如文档标题,也可以进行相应的转换,以保留原始数据的基本形式,并将其映射到图谱中相应的格式中。
间接填充方法用于处理那些虽然以结构化格式存在,但无法直接导入法律知识图谱的数据。这包括将数据库中的资源类型、法规的法律索引以及司法文件的分类映射到图谱中的相应位置。举例来说,对于资源类型,奥地利按照ELI本体的建议在AustroVoc中创建了一个名为av:resource-types的属性。如果法规文件在数据库中以“bg”(联邦法律)的形式存在,那么需要将其替换为av:leg_bg,同时将该属性对应的eli属性设置为eli:type_document。这样的映射和替换确保了法律知识图谱中的数据更加准确和语义丰富。
RIS数据库包含着各种法律信息,如法规和法院的裁决,但它并没有提供其他结构化的背景信息。这些背景信息对于改进法律搜索流程和进行高级法律体系分析同样至关重要。这些信息包括与法院裁决相关的地理实体或事件的时空信息,比如裁决的地点或相关日期。为了弥补这一不足,奥地利接入外部数据源,其中包括Nominatim(OpenStreetMap的搜索引擎[11])和Geonames[12]。通过查询Nominatim获取奥地利法院的地址信息,然后使用Geonames提供的RDF数据将这些数据信息导入到法律知识图谱中。这样做有助于为法院信息增加地理参考,例如所在社区、地区、州和国家等。同时,通过rdfs:seeAlso[13]属性,还将这些法院的信息与OpenStreetMap中的相应信息页面相互链接。通过接入外部源的信息,让法律知识图谱更加丰富和具有实用性。
2.非结构化数据
在非结构化文本中,信息往往不像元数据那样被清晰地记录下来,这就需要利用自然语言处理(NLP)工具和技术来从文档中提取所需的信息。特别是在法律领域,涉及大量的文本数据,其中包含了各种法律实体,如法院、法规和法律公告等。为了能够从这些文本中准确地识别和提取出相关信息,命名实体识别(NER)成为一种常用的技术手段。
在实际的法律实践中,经常会遇到法院的裁决或文件引用其他文档的情况。然而,这些被引用的文档通常并不具备完整的元数据信息,可能仅仅是以简单的文本形式存在,缺乏结构化的超链接或其他标识。这就带来了一个重要问题,即虽然人们可以通过简单的文本标签理解这些引用关系,但计算机系统却难以准确地识别和处理这些信息。
为了解决这个问题,需要将这些非结构化引用转换为计算机可理解的链接,从而实现信息的自动化处理和关联。这个转换过程包括了多个步骤:首先,需要从文本中提取出相关的实体,如法院名称、法规编号等;然后,通过特定的算法和技术,寻找被引用文档的相应ELI(European Legislation Identifier)或ECLI(European Case Law Identifier)标识符;最后,利用合适的元数据属性dcterms:references(法律资源引用关系)或eli:cited_by_case_law(法律案例引用关系),将这些文档链接在一起,形成一个完整的关联图谱。通过这样的方式,系统可以自动识别和理解文档之间的关联关系,从而提高信息的可访问性和可用性。
在当前阶段,奥地利进行了对比和评估更先进的信息提取方法,其中包括条件随机领域和深度学习方法。他们发现,深度学习方法具有更大的灵活性,能够更好地适应不同的文本情况,但是这种方法需要大量的工作来进行机器学习模型的训练和微调。这个过程涉及标注大量的训练文档,并且需要大量的计算资源来进行训练和优化。
考虑到这些成本和复杂性,他们认为从文本中提取法律实体并没有一种单一的最佳方法。相反,应该根据具体需求、可用数据和人力资源等多方面因素来选择合适的方法。这意味着在选择信息提取方法时,不仅要考虑技术的先进性和效果,还要综合考虑可行性、成本和资源投入等因素。因此,他们建议在实际应用中,应该根据具体情况综合权衡,选择最适合的信息提取方法。
3.跨语言的词汇对齐
在此前提到的案例中,奥地利发现AustroVoc词汇表和EuroVoc词汇表中有关消费者保护的德语术语并不完全相同。为了解决这一问题,他们采用了Filtz等人(2018年)所描述的方法。这种方法采用了简单的匹配策略,首先直接在EuroVoc中寻找奥地利术语。如果在EuroVoc中找不到匹配项,他们便会从外部知识库(如DBpedia、Wikidata和Standard Thesaurus Wirtschaft)中搜索该术语的其他语言版本。一旦找到匹配项,就会使用属性rdfs:seeAlso将AustroVoc术语与相应的EuroVoc术语进行链接。这样一来,就能够建立奥地利法律索引和EuroVoc概念之间的链接。举例来说,当找到“AustroVoc中的Konsumentenschutz”与“EuroVoc中的Verbraucherschutz”的匹配时,他们会使用三元组av:bri2006、rdfs:seeAlso、ev:2836进行链接。这种方法确保了不同语言版本之间概念的一致性,使用户能够进行跨语言的搜索,并且在提取和分析法律文件时获得更全面和准确的结果。
(四)衔接欧洲其他国家法律知识图谱
为了能够将奥地利法律知识图谱与其他国家的法律知识图谱整合起来,实现跨国的关联。奥地利分析了其他欧盟成员国提供的法律数据以及法律数据库的现状,并进行了比较分析,包括政府提供的法律信息以及非政府倡议。比如下图6中所示欧盟成员国实施ELI和ECLI的整体状态:
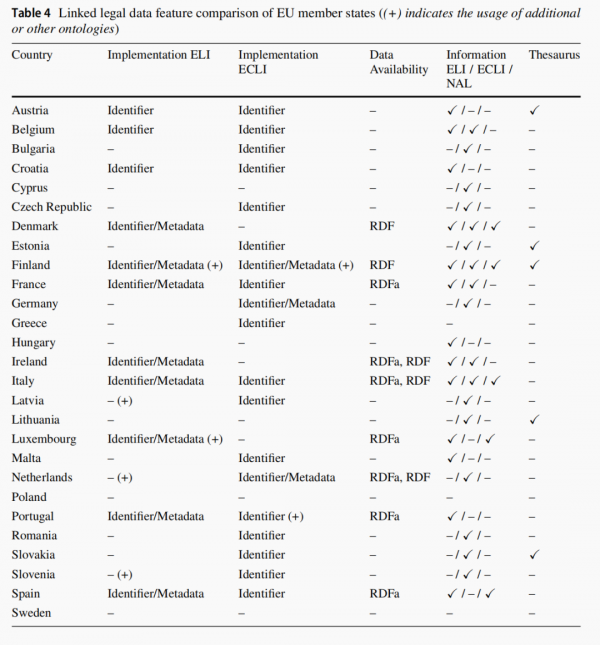
图6:欧盟成员国国家实施ELI和ECLI的状态图
在该图中,“Implementation ELI”和“Implementation ECLI”描述了实施状态,其中“Identifier”表示文档被赋予ELI标识符的情况,“Identifier/Metadata”表示该国还为文档提供元数据。
再如图7为欧洲多个非政府倡议的概况:

图7:非政府倡议概况
表格中的“Project”列显示了项目的标题。根据“Type”列中的分类,将项目分为两种类型:Linking代表该项目旨在将法律数据与其他法律数据或外部知识库链接,Extraction则表示该项目专注于提取法律文件中包含的特定信息。“Using ELI / ECLI”列指示该项目是否使用ELI、ECLI或两者。“Extension ELI / ECLI”列表示是否对ELI和ECLI本体进行了扩展。如果提供数据下载,则在“Data Availability”列中显示下载的格式。“Thesaurus”列指示是否使用了欧洲词表EuroVoc或其他词表(如国家词表)。在“Open Data Linking”列中,指示了项目中使用的数据是否与其他外部数据(如DBpedia或Geonames)链接。最后,“SPARQL”列显示是否提供了SPARQL端点以从该项目检索数据。
在实现与其他国家法律的交互连接方面,存在着各种挑战和障碍。首先,法律信息的发布和访问可能受到不同国家的许可和访问政策的限制,甚至可能存在缺乏统一的政策的情况。其次,各国的法律体系在结构上存在差异,这使得在数据交流和共享方面存在困难。再次,法律信息的提供方式可能存在混乱,大部分数据都是非格式化的,结构化的数据相对较少,因此各国提供的数据的结构质量也可能有所不同。最后,法律信息检索过程中的语言障碍也是一个重要因素,不同国家使用不同的语言,这给数据交流和共享带来了额外的困难。
因此,在建立跨国数据交流的过程,奥地利认为还需要推进各方利益相关者的程度。比如推进各国的专家、了解其他国家法律体系的专家以及来自负责的欧盟机构的专家之间的合作。通过这种协作,可以加强未来ELI和ECLI的建模标准,使其更加适用于各国的法律体系。同时,这种协作也有助于确保大多数国家都能够遵循统一的标准,从而促进法律信息的更好交流和共享,为国际合作提供更加坚实的基础。
总结
奥地利建立法律知识图谱带来了多方面的优势,这些优势对法律信息管理和应用领域都具有重要的意义。首先,通过建立知识图谱,可以实现法律信息搜索的高效性和便捷性。传统的法律信息检索往往需要用户进行多个步骤的查询,而知识图谱可以将这些步骤合并为一个单一的查询。用户可以通过一个查询获取到引用了所有文档的法院决定以及相关文档类型的信息,从而节省了时间和精力。
其次,知识图谱的建立使得法律信息系统的内容更加丰富和准确。通过集成外部数据源,特别是跨国法律信息,知识图谱提供了更全面和准确的信息视图。这有助于解决传统法律信息系统中信息碎片化的问题,为用户提供了更清晰和完整的信息。
另外,建立法律知识图谱还有助于解决语言障碍,支持多语言搜索。在欧盟,各成员国采用多种语言编写法律文件,传统的信息检索系统往往只能以一种语言进行搜索。而知识图谱则可以支持用户以自己的语言进行搜索,使得用户能够轻松地获取到以其他语言编写的法律文件,提高了信息获取的便捷性和透明度。
最重要的是,知识图谱的建立促进了跨司法辖区的数据共享和交互使用。法律知识图谱使得不同司法辖区的法律信息得以集成和交流,为法律信息提供者和数据使用者提供了更多可靠的信息资源。
[1] https://www.bmdw.gv.at/en.html.
[2] https://www.ris.bka.gv.at/.
[3] https://data.bka.gv.at/ris/api/v2.5/.
[4] 欧洲立法标识符(ELI)是一个以标准化的格式在线提供立法文件的框架或系统,其目的是便于跨越国界进行访问、交换和数据的再利用。该倡议由欧盟各成员国和机构共同发起,并载入了2017年11月6日欧盟理事会关于欧洲立法标识符的结论(2017/C 441/05)中,https://eur-lex.europa.eu/eli-register/about.html?locale=en.
[5] 欧洲案例法律标识符(ECLI)是欧洲法院决定的标识符。该标识符由五个由冒号分隔的元素组成——ECLI:[国家代码]:[法院标识符]:[决定年份]:[特定标识符]。关于该标识符的具体标准规定在《Council conclusions inviting the introduction of the European Case Law Identifier (ECLI) and a minimum set of uniform metadata for case law》文件中,访问链接:https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=uriserv%3AOJ.C_.2011.127.01.0001.01.ENG&toc=OJ%3AC%3A2011%3A127%3ATOC
[6] 欧洲立法标识符(ELI)的本体,它是一种通用的数据模型,用于在互联网上交换法律文件的元数据。ELI的本体设计遵循了FRBR(Functional Requirements for Bibliographic Records)原则,这是一种用于描述和管理文献信息的标准。FRBR 是 "Functional Requirements for Bibliographic Records" 的缩写,翻译为《书目记录的功能性要求》。它是由国际图书馆协会(International Federation of Library Associations and Institutions,缩写为 IFLA)制定的一组关于书目记录(bibliographic records)的标准,旨在提供一种框架,以更好地理解、组织和展示图书馆资源。FRBR 引入了一种层次化的、实体-关系模型,以代替传统的平面书目记录。该模型定义了四个主要实体,分别是work、expression、format以及Item。ELI引入中不体现item。
[7] 2011/C127/01, 2012/C325/02: Identification of needs.
[8] 法律知识图谱(legal knowledge graph)是一种以图形结构组织和表示法律领域相关信息的方法。它将法律实体(如法律文件、案例、条款等)以及它们之间的关系(如引用、相关性、层级等)呈现为一个网络,使得人们能够更清晰地理解法律概念之间的连接和影响。法律知识图谱旨在帮助人们更有效地浏览、理解和利用法律信息,提供了一种直观、结构化的方式来探索法律体系的复杂性。
[9] EuroVoc是欧盟提供的多领域多语言词汇库,其中包含了欧盟成员国官方语言中各种领域的术语。
[10]https://op.europa.eu/en/web/eu-vocabularies/at-dataset/-/resource/dataset/court-type.
[11] OpenStreetMap(OSM)是一个开源的在线地图服务,由社区驱动,用户可以编辑和贡献地理信息。
[12] Geonames是另一个地理数据库,提供有关地理实体(如城市、国家、地区等)的信息。
[13] rdfs:seeAlso是RDF模型中的属性,用于指定与当前资源相关的其他资源。在这种情况下,它被用于包括指向 OpenStreetMap 中法院信息页面的链接,以便法律信息系统的用户能够检索有关相应法院机构位置和联系信息。

好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2024
03/04
15:04
分享
点赞

