
AI视频的质量,离世界顶级的渲染大赛还有多远的路?
这两天,有很多人哐哐给我发一些视频,问我是不是AI做的。
或者就是问,想用AI做成这样,要学啥。
这些视频里面的一些片段,大概是这样的:


我直接看笑了,因为太熟了。
这特娘的是第八届世界渲染大赛的作品啊。
很多人可能不知道这个比赛,但是你如果是个玩3D的人,一定都会知道。
2020年底,pwnisher向广大的艺术家发起挑战(主要是疫情,闲的)。他会给出一个工程模板,然后大家按他的镜头、角色动画、背景去扩展创作自己的故事。
没想到,第一届,就收到了125个艺术家的作品参与。
这哥们就直接把大家的作品剪了一个合集。
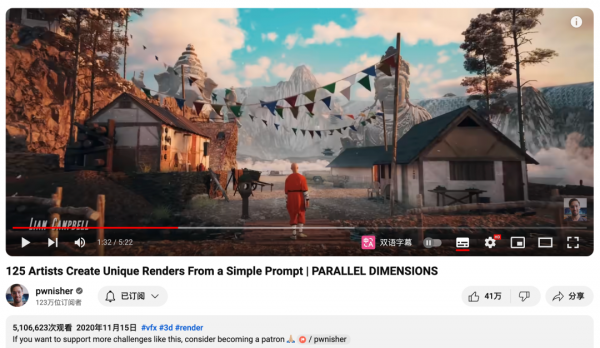
结果就,自然而然的爆了。
因为实在是,太TM牛逼了。无论是技术、还是创意。
第二届再举办的时候,主题叫Alternate Realities(交替现实),直接收到了2400多份作品。
从此,世界3D渲染大赛,成了全世界最顶级的3D渲染赛事。
我印象中,第六届的ENDLESS ENGINES(无限引擎)应该是参与人数的巅峰,收到了4280个作品,但是能最终只能选出TOP100,入选率2.3%,也特么挺离谱的。。。
一晃三年,世界3D渲染大赛,已经举办到了第八届,这次的主题是:Eternal Ascent(无尽阶梯)。
而上面的片段,就是第八届的一些作品。
需要注意的是,这些作品并不是最终的TOP100,只是很多玩家在提交后,发出来的自己的作品,然后别人收集了一波剪辑了一下。
正式开奖日期我记得没错的话,应该是3月9号。
所以,回到文章最开始的那两个问题。
这是AI做的吗?
答:不是。
想用AI做成这样,要学啥?
答:就用AI的话,学啥你也做不出来。
世界渲染大赛的作品,倒是跟现在的AI视频有一个共性是:都只有4~5秒钟。
但是世界渲染大赛的作品,用郭帆在《流浪地球2制作手记》中的话说,叫:
无限细节。
几秒中的视频里,有脑洞、有创意、有故事、有细节、有彩蛋,埋了太多太多的点子了。
很多时候你要看个三四遍,才能把细节全部看全。
甚至背景上,很多时候也都是戏。
这需要工具本身有极高的可控性,人还有极高的想象力。
这两者我觉得缺一不可。
而可控性,从来都是AI,最薄弱的一环。人们都只看AI一键直出有多爽,但是忘了在真正的商业化交付中,可控,是至关重要的一环。
AI视频,确实在很多时候可以降低一些创作者的门槛,但是我从不来认为,这个时代就已经被瞬间颠覆了。
技术永远是一道渐变的灰。
按现在AI视频的的模型进化速度,以及可控性的进化速度,想真正冲击到一些顶级作品的时间点,我个人预估还需要2~3年时间。
甚至,需要等AI 3D的成熟。
所以,不要高估了技术的短期影响,但是也不要低估了技术的长期影响。
等待,但拥抱。
好文章,需要你的鼓励


旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

三一学院与华为研究院联手出招:AI大模型“智能分诊“系统,省钱又省时
三一学院与华为联合提出两阶段AI模型调度框架:先按语义聚类分配最优模型,再用轻量分类器拦截低质回答升级处理,在保留97-99%最强模型准确率的同时显著降低推理延迟。

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
美国核管理委员会(NRC)近期提出对第61部分法规进行全面修订,首次为"超C类"(GTCC)低放射性核废料建立明确的许可处置路径。现有框架要求将其送入从未建成的深层地质处置库,形成"监管死胡同"。新规拟采用基于风险的分析方法,按废料实际放射性危害而非来源确定处置方式,约80%的GTCC废料或可适用近地表处置。这些废料目前分散存放于反应堆、医院及工业设施,新规将为其提供集中处置的可行路径。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

