
LangChain - RAG: 老板说我们的 RAG 既要支持多文档、又要超长上下文、准确性好还要超低成本!我 X...
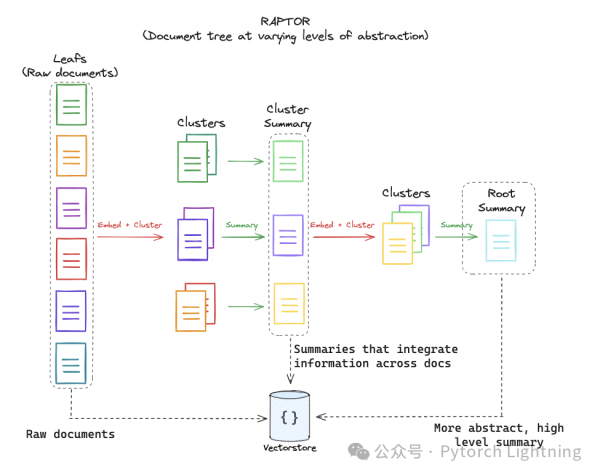
图一: RAPTOR 结构示意图, from langchain
老规矩先说结论:我们要讨论的 RAPTOR 方法在针对内容检索的「海底捞针」(Needle-in-a-Haystack, 由 @GregKamradt 想到的一种测试 LLM 检索能力的方法,Claude 3 Opus 前几天发布的结果里面最引人注目的就是那张「几乎全绿」的测试结果图:Introducing the next generation of Claude。更多详情:1. https://twitter.com/GregKamradt/status/1722386725635580292 ;2. https://www.youtube.com/watch?v=KwRRuiCCdmc)测试结果中大幅度领先(QuALITY测试上比 GPT4 优秀 20%:QuALITY: Question Answering with Long Input Texts, Yes!),准确性、召回率提升,且可以支持更多的文档和更长的上下文,是不是很惊喜?看起来可以满足老板的既要支持多文档,又要支持超长上下文,还要成本超级低的伟大(BT)要求。QuALITY: Question Answering with Long Input Texts, Yes!老规矩先说结论:我们要讨论的 RAPTOR 方法在针对内容检索的「海底捞针」(Needle-in-a-Haystack, 由 @GregKamradt 想到的一种测试 LLM 检索能力的方法,Claude 3 Opus 前几天发布的结果里面最引人注目的就是那张「几乎全绿」的测试结果图:Introducing the next generation of Claude。更多详情:1. https://twitter.com/GregKamradt/status/1722386725635580292 ;2. https://www.youtube.com/watch?v=KwRRuiCCdmc)测试结果中大幅度领先(Qu),准确性、召回率提升,且可以支持更多的文档和更长的上下文,是不是很惊喜?看起来可以满足老板的既要支持多文档,又要支持超长上下文,还要成本超级低的伟大(BT)要求。这也难怪 LangChain 和 LLama-Index 都争先恐后的支持了(https://github.com/langchain-ai/langchain/blob/master/cookbook/RAPTOR.ipynb | https://github.com/run-llama/llama_index/tree/main/llama-index-packs/llama-index-packs-raptor)。
RAG(Retrieval-Augmented Generation, aka RAG)在经历了接近一年的疯狂发展之后,各种优化方法从文档提取、文本切割、embedding 优化、召回率准确率优化、查询结果理解、最终结果合成... 等等等等各个方面都得到了极大的提升,甚至可能是过于细节的提升。正因为这个点上各种琐碎的东西实在太多,整得我好久都提不起兴趣写新的分享,幸好,近来老将出马,来了这篇 RAPTOR。稍微跑个题,之前大家给自己的工作起名字好像都喜欢跟蛇扯上关系(调戏 Python?),比如 mamba(Mamba: Linear-Time Sequence Modeling with Selective State Spaces),但最近好像风向改了?比如 Raptor、比如 griffin(Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models),以后难道都要走鸟吃蛇的路子了?
RAPTOR(https://arxiv.org/abs/2401.18059) 是上个月的论文,被 ICLR 2024(ICLR 2024) 收了,一作是 @parthsarthi03, 指导老师是 stanford 大名鼎鼎的曼宁教授(@chrmanning ,学过 CS224N 的都了解吧),提这位大佬有两个意思:一个是这个工作名门出品,可能有点东西;另一个是内容肯定相对比较「传统 NLP」,不会像类似 Prompt 层面的 PUA 一样的思路:
说 ta 是「传统 NLP」一点也不委屈,RAPTOR 的主要思想不难理解:
文本分割作 emb 这部分没什么太多好说的,需要注意的是 chunk size 设置成了 100 个 token,太长了LLM 容易忘掉中间的内容(Lost in the Middle: Lost in the Middle: How Language Models Use Long Contexts)
把所有内容按照语义做聚类,这是本工作的重点,相较于其他很多工作来讲(当然也很优秀),本工作在把内容预处理之后(到 emb 之前的内容,chunk 选的尽量小、sbert 来做 emb,这里感觉换成性能更好的模型还可以再挖掘一下,比如 bge 、 jina、uae... ),没有拘泥于原来的文章的行文结构来决定内容的前后关联度,而是引入了一个聚类的方法重新把内容通过「语义逻辑」重新组合,这里的方法用的是高斯混合模型 Gaussian Mixture Models (GMMs)来做软聚类,细节没细看(水平不够...)感兴趣的同学自行学习。总之通过这个操作之后,可以理解为把整个文档按照 100 token 的粒度打散了,然后让 llm 理解意思之后重新编排内容,编排的方式自然而然就是树状结构(其实就是更好的目录)。
之后做递归总结也值得一提,要让 llm 处理长文本,如果不能无限制的提升 llm 的 context 的话,就只能掉过头来先把长文本「压缩」成短文本而尽量不要减少信息量,类似 RNN 的隐层(当然 ta 压缩的损失过于大了),类似 langchain 里面的 「refine」机制(关于这点,langchain 的 js 版 doc 写的更好些,图文并茂:https://js.langchain.com/docs/modules/chains/document/refine)。并且,当聚类之后的 chunk 数量超过了预定的值之后,递归总结的过程还会在内部再次进行递归总结,一直优化到需要的长度,真棒!
按照树形结构(也就是更好的目录)来做信息整合,基于上面几步优化,文本信息被重新组织、优化成一棵树(计算机这种呆头呆脑的最喜欢的就是各种「树」了,二叉、红黑、平衡... 人类看到名字就头痛的东西对机器来说却很亲切)。不要小看了这个「小想法」,正因为树状结构在处理长距离依赖问题和扩展性上的优势,才能在解决万恶老板的多文档、超长上下文上有所突破。
总结一下就是,针对:
大部分文章写的逻辑上不够结构化,并不是所有文章都是相关的内容都「挨在一起」
LLM 即便是有了注意力机制加持,也存在一个 context 长度毕竟有限的问题
引入聚类的想法,把内容打散重组,然后以机器喜闻乐见的方式给过去,皆大欢喜!
看下 langchain 的具体实现(不再献丑贴 code 了,在这里:https://github.com/langchain-ai/langchain/blob/master/cookbook/RAPTOR.ipynb),逻辑如下:
这个例子里面主要抓取了 LCEL 相关的内容
LCEL 的简介、quickstart 和其中的一个 retriever 方法三个页面
基于这三个内容,应用 RAPTOR 方法,注意魔法就在这里!通过「聚类」这个平白无奇的小招数,llm 「refine」了内容,找到了如何定位到所需内容的方法(树叶子),由此推广,就可以支持多文档、超长文本!
针对最后一个伟大(BT)的需求,超低成本,这里用的是 claude-3-opus-20240229 模型自然是成本过于昂贵,但得益于 langchain 自身强大的生态整合能力,把 Claude 3 Opus 换成 gpt4、mistral-large、mixtral 自部署或者先去薅一下 Groq 的免费羊毛(https://console.groq.com/playground)也是分分钟搞定的事,不再啰嗦。
值得一提的是这个 demo 用到了 langsmith ,把执行的过程、结果详细的记录下来了,啥意思明白不?以后自己的项目也尽量接入 langsmith 方便做 debug、monitor、record(感觉 Harrison 同学 @hwchase17 可以给我打广告费了)...
好文章,需要你的鼓励


OpenClaw 智能体正式登陆 iOS 与 Android 平台
开源AI智能体OpenClaw今日宣布正式推出iOS和Android应用。用户可通过手机连接OpenClaw Gateway路由层,调用AI智能体及其工具完成各类任务,涵盖编程、餐饮规划等场景。OpenClaw此前因MoltBook社交媒体实验走红,其创始人Peter Steinberger已于今年2月加入OpenAI。尽管MoltBook事件后来被揭露部分由真人假扮智能体,此次移动端上线标志着AI智能体正加速渗透日常生活。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。
2024
03/08
17:04
分享
点赞

