
我们花了10天时间,给CCTV6做了一部AI短片 - 5000字全流程复盘拆解
故事是这样的。
前段时间,我们花了10天时间,为CCTV6电影频道AI影像人才优选计划,做了一部AI短片,《玉覆荆楚》,在4.12号的电影频道M榜盛典上正式亮相,同时也算为后面的AI影像大赛打个样。


然后肉身去了一趟M榜盛典现场,走了一段秀亮了个像。
当你前排就是王迅、郑凯、刘浩存、周深、乌尔善、张艺谋、成龙这一种明星大佬时,那种感觉还是有点意外以及特殊的。
回到这个片子本身。
因为是荆楚文化命题作文,所以我将我一直很喜欢的游戏元素,跟给我震撼非常大的荆州博物馆中的文物做结合,有了这么一个故事。
这是一个关于游戏、文物、坚守、传承的故事。
我们肝了整整10天,这也是我第一个真正电影质感的AI短片,更是做的最开心的一个短片。
希望大家喜欢。
这也算,一种“传承”。
整体的AI影像制作工作流,其实一直都没有什么太大的变化,依然是:
1.写剧本 - 2.做分镜 - 3.AI生图 - 4.图生视频 - 5.剪辑 - 6.声音和音乐制作
这其实就是一个非常小型的影视工作流。
但是在每一大步的具体细节中,可以说有了翻天覆地的变化。
这也符合AI的特性:人间一天,AI一年。
我们一个一个来说吧。
一. 写剧本
坦率的讲,AI短片故事的剧本并不是很好写。
因为我们从一开始,就是荆楚文化的命题,以及我一开始就很想做关于穿越、救赎、传承这种思路的故事,再加上AI的呈现上限,最多只能做到3~5分钟,再长的时长,观众就一定会审美疲劳。
所以要在3~5分钟里,做到一个有反转、好看、还契合AI本身局限的故事,还是非常难的。
特别是对我这种完全对于编剧懵懵懂懂的门外汉来说,更是难上加难。
而且短片的剧本故事逻辑,跟电影级别的长片剧本还是有很大的不同,根本没有时间给你铺垫,上来就要直接开始,立刻要展现冲突、交代人物、反转、带入高潮,然后ending。
那几天,我刷了基本大部分的3~8分钟的历届得奖短片,比如《黑洞》、《无翼鸟》等等,还有一众新兴的UP主的短片故事,比如柳叶熙、白夜梦的摸鱼时间等等。
我深刻的感受到:写故事,写一个好故事,是有绝对的门槛的。
另一个感触是:对于短片来说,创意和点子,有时候比努力去写,更重要。
我记得《任天堂哲学》中,整个任天堂时代的奠基人山内溥有过一段著名的话:
“并非只要一味思考就能获得成果。和长年累月的冥思苦思相比,也许瞬间的灵感更重要,这种瞬间的思维火花可能燃起一场轰轰烈烈的燎原之火。”
但是,遗憾的是,在那几天中,我的脑中,现在并没有“创意”。或者说,我已经很久没有接受过一些刻意的“创意”的训练,更多的得到的是技法的训练。
以至于我对于该如何去寻找“灵感”,如果去激发“创意”,变得尤为陌生。
而写故事这事,我当然也尝试过交给AI,而是是从去年5月开始,直到这次剧本。
我的明确的结论是:
写一个大体的小说故事,写到80分,是OK的。但是写一个有明确特定主题、有限制的短片剧本,写到80分。
不行。
至少还远远达不到,我所认为的“创意”或“点子”,还有藕合性。
所以,这次的故事,几乎都是人写的。

很感谢尾鳍Vicky、筠姐还有电影频道对剧本的帮助,至少在有限的空间内,帮我完成了一个能看的过去的故事。
在有了剧本之后,就是做分镜。
二. 做分镜
在分镜的设计上,坦率的讲,非常的稚嫩。
因为在AI制作的时候,我跟@JessyJang、@郑伟是多人协同,所以我们使用了飞书进行管理。
因为已经有了明确的故事,所以分镜主要就是在有限的时间内,将想展示的画面,用一句话表达出来,最核心的东西就是景别。
我自己本身是非专业的,所以我自己也并没有什么太多的经验可以传授,都是野路子经验,比如不能远景直接切特写,而是要远景切中景再切近镜再切特写,这样有连续性。
比如人物的空间关系需要一致。用这一串举例子,老人走过来,说一句话,然后一掌将主角魂魄击飞。

我们有个中景的俯视镜头,老人在左边,主角在右边。后面我们遵从人物空间一致的观感,把后面的一些镜头语言都进行左右统一,老人永远在左边,主角永远在右边。这样观感会好很多。
而在分镜设计上,因为我们太过于了解AI生图的上限和AI视频动态的上限,所以基本上在开始做分镜设计的时候,就可以避开了一些关系镜头,除非是必要的,会用一些传统的PS和AE去做,其他的尽量就不在分镜里出现。
最后我们的分镜写完了,除了剧本逻辑顺序有调整,基本就没改过,每一张图和视频,都能完整的按照我们的想法,100%实现出来。
三. AI生图
在图片生成上,我们依然用的是Midjourney,原因依然单纯的很简单:
我要的电影感和审美,只有Midjourney可以做出来。
很多人问,画面的电影感到底怎么做出来,为什么我的图总是一股子AI感。
其实挺简单的,画面的电影感无非就是几个点:画幅,审美、色调、构图、光影、景深等等。
我最喜欢用的画幅比例就是,21:9。



画幅的比例是会影响生图的构图和光影的,21:9,是出电影感最好的比例。
同时在Prompt里,也可以加电影的专用摄影机,比如RED Helium 8K等等。
而我们的整体Prompt风格后缀:
________. Shot on Sony Venice 2, muted color tones, green and dark gray, award-winning composition, cinematic scene --ar 21:9
而在人物一致性上,在有了Midjourney的新功能Cref以后,其实就非常简单了。
我们直接先跑了一张主角的定妆照。

然后在需要出现主角人物的地方,扔进去Cref。保持发型、人脸、衣服。

坦率的讲,Midjourney对亚洲人脸的Cref一致性,要比对欧美的人脸的一致性效果差太多太多了,年轻人还好点,亚洲老人简直惨不忍睹。
而且Cref的效果,在画面的审美和构图上,其实是有一定的破坏性的,所以在原则上,是能不用Cref就不用Cref,比如只有背影的时候,写个短发男人黑卫衣就完事了。
这是人物一致性,而场景一致性,目前基本上还没有任何解决办法,纯粹随缘。roll的大差不差也就那样了。
而Midjourney的可控性上限问题,随着这次项目的进程,也越发的发现,纯粹的roll图或者用他们屎一样的局部重绘,会浪费太多太多无意义的时间,所以还是得用一些设计师的传统手段,节省时间。
毕竟,追求全流程AI,没有任何意义,观众不会在乎你是不是AI。
什么效果好用什么,什么成本低用什么,一切都是在成本和收益之间的求解。
所以,我们就直接掏出了PS,还有做动效的AE。
PS得益于PS AI的加持,在图片的修改阶段,有极其可怕的上限,而且是唯一一个,能跟的上Midjourney的质感和细节的。
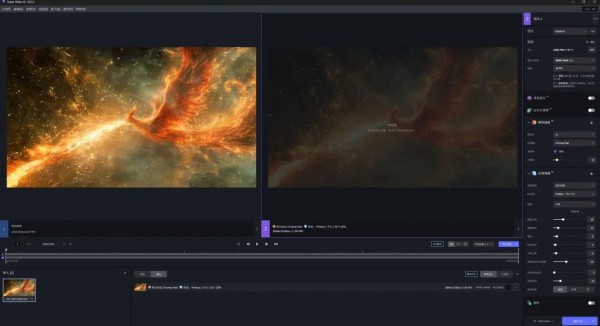
就比如说我们想的一张氛围图,是“中景,一盏只开着灯的办公楼”,我们希望突出这个办公楼只有一盏灯开着,体现深夜还在干活的感觉。
但是Midjourney死活就是不认识什么叫开着一盏灯。给的图是这样的使的:

这种反复的重roll,或者在Midjourney上用局部重绘没有任何意义,就是纯粹的浪费时间,容我再骂一句:Midjourney的局部重绘,实在太辣鸡了。
所以我们直接上PS AI了,每个亮着的都框选,然后写“熄灭的灯”,非常快的就改完了,再把中间想亮的那部分,再抠出来重画一下,一张图就OK了,也就不到5分钟:

再比如说,一个羽人的图,Midjourney大的框架出的还行,但是构图我不喜欢,也有很多细节BUG。

我就扔到PS AI里,手动拖构图,修手修脸修翅膀和背部的结构,再加闪电,5分钟搞定。
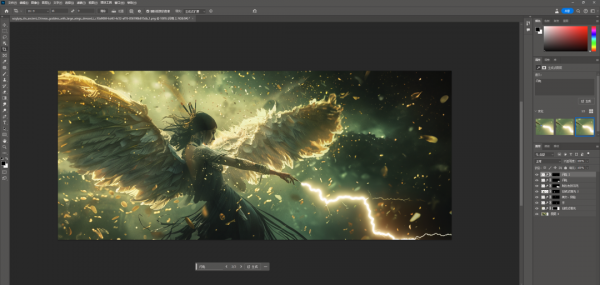
再比如,Midjourney出的凤凰还行,但是构图问题太大,火焰往头上喷,我就可以神经病式扩图法,来调整构图。
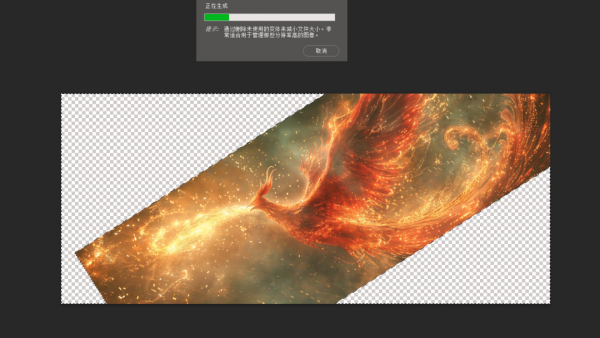
再比如,我生成了一张图,人物面部表情还可以,就是有太多乱七八糟的悬浮物,还有莫名其妙的伤口,一定会影响后续AI视频生成的。

再扔到PS里,直接传统的修补工具+PS AI,直接5分钟处理干净。

我讲了这么多,想表达的意思是,不要拘泥于所谓的AI,拘泥于所谓的特定工具。
工作流是流动的,要做的,就是用最快、最好的工具,来最低成本的解决某些特定问题。
既然很多东西Midjourney处理的不好或者效果不好,那为什么要在那Roll他1小时?我用PS,直接5分钟P一下,不就行了吗?
比如说,我们的鼓,在片子中是个很重要的道具,物体的一致性Midjourney处理的很差,但是我们又不希望鼓变形。
所以,直接让Midjourney生成一个空场景,传统的PS合成就行了,我们直接把鼓合成进去。



速度很快,效果也能看。
所以,我觉得,一定要要懂得变通。
四. 图生视频
在Sora没出来之前,我们玩的依然是4s。
4s时代,我目前用的最多的,分别是Runway、Dreamina、Pixverse。
三者在片子中的占比约是60%、30%、10%。
我们用AI视频生成工具,无非看的就是四点:
用户体验、可控性、细节丢失度、运动幅度。
Runway在用户体验、可控性、细节丢失度上,依然是目前最强的王者,功能上有镜头控制、运动笔刷,在做一些小幅度的运镜、空镜,以及一些特定运动轨迹的镜头,依然有无与伦比的优势。
Runway网址:https://app.runwayml.com/
比如这个凤凰睁眼的,直接运动笔刷轻轻松松就刷出来了,在别的平台上,即使你怎么调整你的prompt,你也大概率roll不出来。

其他的一些小幅度运镜,效果也很好。


而且Runway是现在为数不多,能给视频中的人物,直接对口型的,叫Generative-audio,而且对的效果非常好。
不过,Runway做小幅度和对口型的还行,但是真做一个物体的大幅度运动,直接躺。
而剪映的Dreamina在运动幅度这块,是属于碾压式的,一些大幅度的东西,只能用Dreamina能做出来。
Dreamina网址:https://dreamina.jianying.com/


而且Dreamina有一个很特殊的功能,首尾帧,定好首帧和尾帧,AI自动补全中间的运动轨迹。
这个是一个非常有商业价值且能玩出很多花活的功能。
但是同样的,Dreamina目前的缺陷也极其明显:
运动幅度过大导致极难控制、只有3s、帧率只有8帧、分辨率只有720P,传个21:9的图上去还自动给你裁成16:9。
问题太多了,但是你架不住人运动关系真的好,也必须得用。
首当其冲的就是我的21:9的图,自动给我剪裁成16:9。
所以我有两个选择:
1.要么Midjourney生成21:9的,我扩图成16:9,再去Dreamina里面跑视频,跑完以后再裁成21:9的。
2.要么Midjourney生成16:9的,直接去Dreamina里跑视频,跑完以后再裁成21:9的。
听着好像第二种更轻松一点,第一种挺蠢的。
但是我想说的是,因为尺寸原因,所以基于不同的尺寸,Midjourney的构图逻辑和审美是不一样的。
你生成16:9的再裁成21:9的,会发现,构图大概率直接崩了,主体被裁一半,直接没法用,所以,你只能用第一种方式去玩,累是累了点,但是为了效果,没有办法。
大概就是这样:

中间区域是原图,上下是我用PS AI扩成了16:9,然后为了让大家看清调了下透明度。再把这个图扔到Dreamina里跑视频。
我只能在此呼吁一下Dreamina:求求了,啥时候这个蠢问题,赶紧改了吧。。。
Dreamina对Prompt的语义理解非常好,强烈推荐大家把运动速度设为慢速,我经常喜欢慢速+Prompt里面写轻微XX。会有很不错的效果。
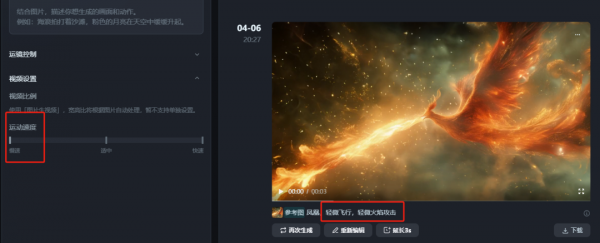
另一个Dreamina非常智障的一点是,只有8帧+720P,对比Runway这种24帧+4k的,基本约等于没法用。
所以还是需要Topaz Video AI去增强到24帧+4K的。
Topaz Video AI的教程我就不在这里细说了,给大家一个关键词:Topaz Video AI 4.2.1,拿着这个关键词,去B站搜教程,又好用又简单,非常方便。
增强完以后,再扔到剪映里,裁成21:9,这一套就算是齐活了。
AI视频的趴写了这么多,基本已经能处理大部分的效果了。但是,很多东西,依然是AI搞不定的。
比如人物在水中下沉的时候,不管你用哪家AI视频,脸必糊,跟恐怖片一样。

这种糊脸,在视频里,讲道理是无法接受的,太恐怖,也太让人出戏。
于是,就只能上传统AE,自己做,反正就是个普通的下沉位移动画。
跑了个静态图。

再把人抠出来,背景空缺的部分,用PS AI补上。然后把背景扔到Runway里跑一个动态,再把背景动态视频和人物的图片扔到AE里,给全身钉上锚点,做动画,最后就是不糊脸的效果。

同样的,AI视频这块,我也讲了这么多,想表达的意思依然是那句话:
不要拘泥于所谓的AI,拘泥于所谓的特定工具。一切都是在成本和收益之间的求解。
五. 剪辑&音效
这一次,在配音、音效、音乐、剪辑上,几乎没有用到任何AI流程。
除了李雪健老师的几句台词,是我用SVC跑的之外。
其他的,全是人。
道理很简单,现在的AI,在这些领域,完全达不到80分作品所需要的要求。
配音有各种TTS,比如11Labs等等,但是在影视中,需要强情绪的,达不到。
AI音效上,有11Labs,但是基本约等于无用,还早,需要进化。
AI音乐上,有Suno、Stable audio,效果能到60分,但是达不到80分,而且这一次的风格比较偏国风,乐器使用里有很多的鼓,特别是高潮的时候,我很坚持一定要唢呐。
所以这一次的片子,没法用。
而如果是一些普通的项目,我大概率会上Suno来做音乐了。
剪辑上,没有能用的AI。
所以综合下来看,这两趴,目前的领域,还是需要大量人工去参与,整个AI产品,还需要时间迭代。
不过问题不大,我有足够的信心,时间问题而已。
写在最后
坦率的讲,我们这次的片子,《玉覆荆楚》,还有太多可以优化的空间了。
他远远没有达到,所谓完美的地步。
但是朋友有一句话说的很好:
电影,都是遗憾的艺术。更何况一个AI短片。
泪目。
人生又何尝不是缺憾的艺术呢。
感谢JessyJang和郑伟,两个一起熬了N个日夜的小伙伴,每个人都顶起了属于自己那一趴;
感谢川影的两位老师,电视学院的董昊老师顶起来全片的声音制作,新媒体学院的陈秋雨老师撑起了全部的后期剪辑,帮我们撑起了故事的一切。
感谢筠姐、段院长,在整个过程中的倾力的帮忙和资源调配。
也谢谢尾鳍Vicky的剧本支持,还有海辛&阿文的技术支持。
最后,更要谢谢CCTV6电影频道给的照顾和机会。去年8月在AI视频起始之初,我的《流浪地球3》的AI预告片的爆火,登上了中国电影报道,跟CCTV6电影频道结下了一次不解之缘。
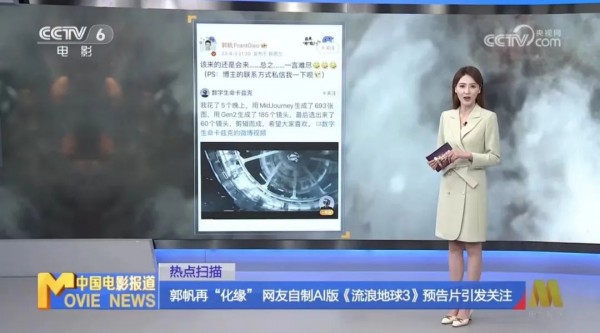
没想到,又成为了这一次的契机和源头。
热爱,方能抵御漫长岁月。
你的诸多过往,终将积累成你心中的锦绣。
我永远相信,流浪的路途,一定会有恒星指点。
你也要相信,你心中的那团锦绣,也终有盛开的那天。
风雨同舟,愿于诸君共勉。
完。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标?~谢谢你看我的文章。
好文章,需要你的鼓励


旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

三一学院与华为研究院联手出招:AI大模型“智能分诊“系统,省钱又省时
三一学院与华为联合提出两阶段AI模型调度框架:先按语义聚类分配最优模型,再用轻量分类器拦截低质回答升级处理,在保留97-99%最强模型准确率的同时显著降低推理延迟。

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
美国核管理委员会(NRC)近期提出对第61部分法规进行全面修订,首次为"超C类"(GTCC)低放射性核废料建立明确的许可处置路径。现有框架要求将其送入从未建成的深层地质处置库,形成"监管死胡同"。新规拟采用基于风险的分析方法,按废料实际放射性危害而非来源确定处置方式,约80%的GTCC废料或可适用近地表处置。这些废料目前分散存放于反应堆、医院及工业设施,新规将为其提供集中处置的可行路径。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

