
清华大模型报告发布:文心一言最懂“人话”
最近,由清华大学基础模型研究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。评测共包含了14个海内外具有代表性的模型,结果显示:文心一言4.0表现亮眼,与国际一流模型水平接近,且差距已经逐渐缩小,名副其实为国内头部模型。
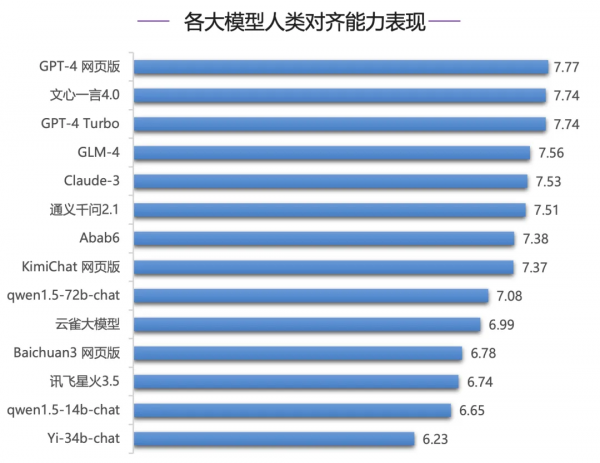
例如在人类对齐能力评测中,文心一言4.0表现优异,位居国内第一,其中在中文推理、中文语言等评测上,文心一言遥遥领先,和其他模型拉开明显差距,中文理解上,文心一言4.0领先优势明显,领先第二名GLM-4 0.41分,GPT-4系列模型表现较差,排在中下游,并且和第一名文心一言4.0分差超过1分。
在语义理解中的数学能力上,文心一言4.0与Claude-3并列全球第一; GPT-4系列模型位列第四五,其他模型得分在55分附近较为集中,明显落后第一梯队;而在语义理解中的阅读理解能力上,文心一言4.0超过GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。
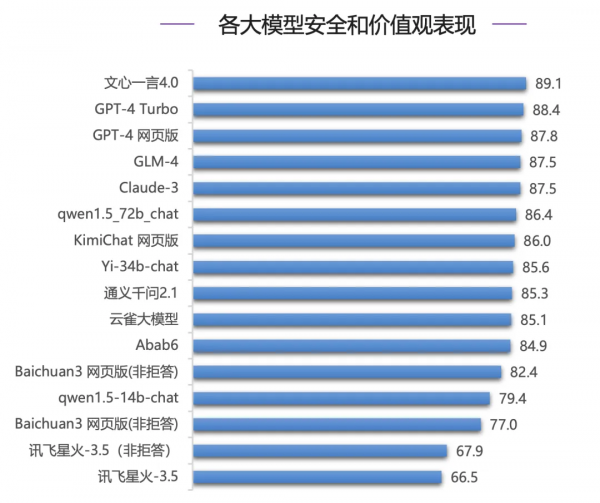
而在企业选择大模型最看重的安全性评测上,国内模型文心一言4.0表现亮眼,力压国际一流模型GPT-4系列模型和Claude-3拿下最高分(89.1分),Claude-3仅列第四。
值得注意的是,文心一言不仅在技术能力上过硬,在应用落地上也是一路领先。自去年3月16日文心一言首发至今,用户数已突破2亿,每天API调用量也突破了2亿。
2023年「百模大战」,国产大模型厮杀猛烈,谁是真正的领头羊?尽管国内外存在多个模型能力评测榜单,但它们的质量参差不齐,排名差异显著。我们在看榜单参考的时候一定要多看权威机构、权威高校的评测,为选择大模型提供科学研判。
来源:大模型之家
好文章,需要你的鼓励


埃森哲与Anthropic合作引领AI集成商崛起之路
埃森哲与Anthropic扩大合作,计划培训3万名员工使用Claude,标志着企业AI战略新方向。面对复杂模型生态、治理要求和人才短缺,咨询公司正成为关键的AI系统集成商。研究显示95%的企业AI试点项目零回报,尽管投资300-400亿美元。集成商能填补技术能力与实际应用间的鸿沟,但也带来新的依赖风险。CIO需要在利用外部合作伙伴的同时保持内部能力建设和架构自主权。

字节跳动发布GAR:让AI能像人类一样精准理解图像任何区域的突破性技术
字节跳动等机构联合发布GAR技术,让AI能同时理解图像的全局和局部信息,实现对多个区域间复杂关系的准确分析。该技术通过RoI对齐特征重放方法,在保持全局视野的同时提取精确细节,在多项测试中表现出色,甚至在某些指标上超越了体积更大的模型,为AI视觉理解能力带来重要突破。

Pure Storage和华为存储增长最快,IDC第三季度报告显示
IDC发布2025年第三季度全球企业级存储系统市场追踪报告,显示存储市场同比增长2.1%至近80亿美元。戴尔以22.7%市场份额居首,华为以12%份额位列第二且增长9.5%。全闪存阵列表现突出增长17.6%,中端存储系统增长8.1%。地域方面,日本、加拿大和欧洲表现最佳,而美国市场下降9.9%。IDC预计随着AI应用渗透,企业对闪存存储需求将持续增长。

Inclusion AI推出万亿参数思维模型Ring-1T:首个开源的超大规模推理引擎如何重塑AI思考边界
Inclusion AI团队推出首个开源万亿参数思维模型Ring-1T,通过IcePop、C3PO++和ASystem三项核心技术突破,解决了超大规模强化学习训练的稳定性和效率难题。该模型在AIME-2025获得93.4分,IMO-2025达到银牌水平,CodeForces获得2088分,展现出卓越的数学推理和编程能力,为AI推理能力发展树立了新的里程碑。
2024
04/24
23:04
分享
点赞

