
重磅!又一国产GPU量产上市!
5月7日消息,武汉凌久微电子有限公司(以下简称凌久微)宣布,该公司自主设计的GP201图形处理芯片已实现批量上市。


-
核心频率为 1200MHz(支持动态调频) -
支持 PCI-E 3.0 × 16 总线接口 -
显存支持 DDR4、LPDDR4、LPDDR4X,最大支持 32GB 容量,数据传输速率最高支持 4266Mbps -
兼容 IBM VGA 标准、兼容 VESA 标准 -
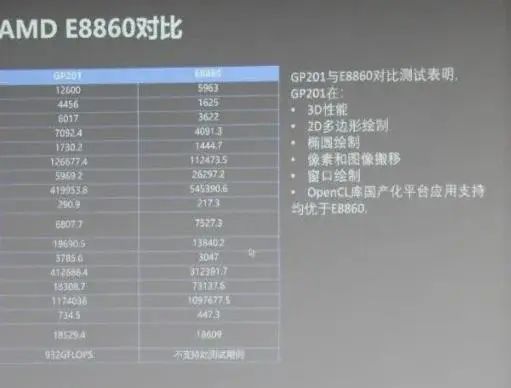
支持龙芯、飞腾、申威、海光和鲲鹏等国产处理器 -
支持麒麟、UOS、VxWorks、翼辉、天脉和锐华等操作系统 -
支持最高 32 位色 -
支持 OpenGL 4.0、OpenCL 1.2 / 3.0 及 OpenGL ES 3.2 标准 -
单精度浮点:1.2 Tflops -
支持 4 路 TMDS 显示接口,4 路 DP / eDP 显示接口,2 路 DVO 显示接口以及 1 路 VGA 显示接口 -
支持 4 路独立显示通道(HDMI、DVI、DP、eDP、VGA),最大分辨率 3840×2160@60Hz -
支持 H.265、H.264、MPEG2 / MPEG4、VC-1、VP6-9 等格式解码,最高可支持全高清 4K@60fps 解码 -
封装规格为 37.5mm×37.5mm,FCBGA2112 -
工作温度范围:-40℃~+85℃ -
功耗:10W~30W,可动态调整
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

2026-07-16
Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。

