
我们花了1000亿美金,却离AGI越来越远了?
01

在AI界,对于如何进一步推动AI的发展,存在两种主要观点。第一种观点认为,计算能力是AI进步的唯一瓶颈。这群人相信,只要我们不断增加计算资源的投入,就能不断提升AI的性能,甚至最终实现AGI(通用人工智能)。简单来说,就是有钱能使AI推磨。就像建造一座高楼大厦,只要有足够的钢筋水泥(计算能力),楼一定可以盖得越来越高。
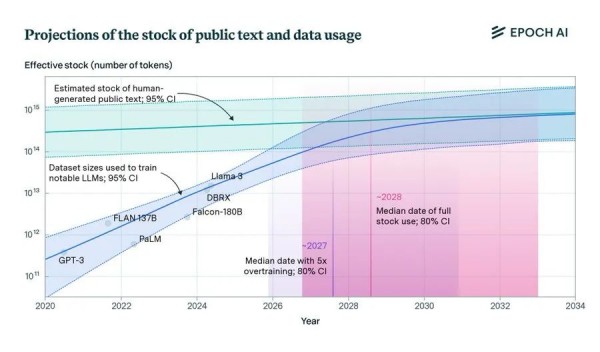
然而,另一种观点却认为,数据才是关键。他们认为我们正面临一个“数据墙”的瓶颈,无论我们拥有多少计算能力,如果没有足够的数据,AI的进展都会放缓。数据墙的存在让人们意识到,仅靠增加计算能力,已经不能带来显著的性能提升。我们必须同时扩展数据量,才能看到更好的结果。
那么,数据墙到底是什么呢?其实,数据墙就像是我们在玩一个游戏,不管你多厉害,如果没有新的关卡和资源,你就会停滞不前。AI也是一样,再多的计算能力,如果没有足够的新数据来训练,效果也会大打折扣。
02
突破数据墙的可能方法
面对数据墙,业界提出了几种潜在的解决方案,希望能够突破这个瓶颈:
首先是高端专家数据。这些数据比普通互联网数据更有价值,就像有经验的老师给你指点迷津,效率自然高很多。高端专家数据通常来自于专业领域的权威和前沿研究,能提供深度和广度兼备的信息。
其次是强化学习(RL)环境。在这种环境下,AI可以通过模拟和自我学习,不断生成新的数据。这类似于AI在一个虚拟世界中自我修炼,积累经验。例如,在一个虚拟驾驶环境中,AI可以无限次地模拟驾驶场景,从而不断优化自己的驾驶技能。
最后是合成数据。这是一种通过算法生成的数据,能够弥补实际数据的不足。就像电影中的特效,虽然是虚拟的,但看起来同样真实。合成数据可以模拟各种复杂场景和条件,帮助AI模型进行全面训练。
这些方法看起来很有前途,但能否真正突破数据墙仍是未知数。有些专家认为,数据墙只是暂时的技术障碍,可以通过工程设计来解决;另一些人则担心这会导致AI发展的长期停滞。我们可以把数据墙看作是马拉松比赛中的“极点”,有人认为熬过去就行,有人则认为可能跑不完。
分散的资源与未来的不确定性
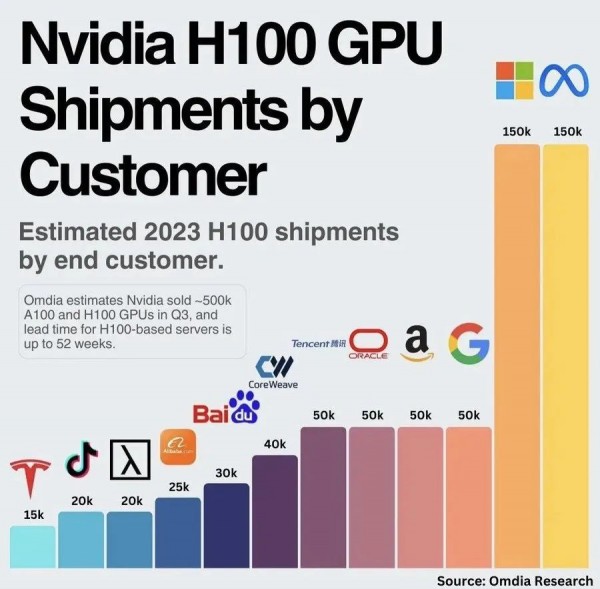
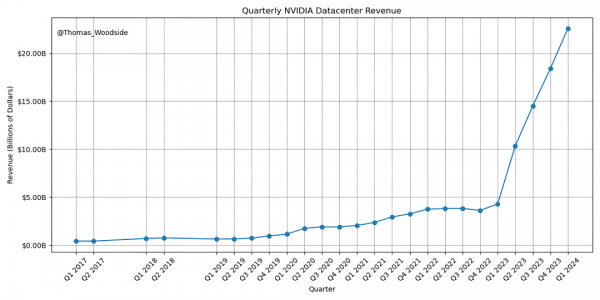
除了数据和计算能力的挑战,还有一个实际问题是:资源的分配。1000亿美元的GPU投入其实是分散在多个实验室中。像谷歌、OpenAI、Meta、Anthropic等大型实验室,各自占有的资源都不超过总供应量的10-20%。
这意味着,即使某个实验室投入巨资,也很难在短时间内看到单个模型上的巨大突破。这就像是几支足球队分散训练,每支队伍的资源有限,难以形成绝对的优势。
未来的进展或许还依赖于新的算法突破,能够超越当前的缩放定律范式。这也意味着,我们可能需要更大规模的投资,比如5000亿美元,才能真正看到AI的显著进步。
写在最后的话
AI的未来充满了不确定性,计算和数据的挑战依然存在。尽管如此,人工智能毫无疑问将继续改变我们的生活,成为人类历史上最伟大的项目之一。
你怎么看待这些挑战和未来的AI发展?欢迎在评论区分享你的观点,并转发这篇文章,让更多人一起探讨AI的未来吧!
好文章,需要你的鼓励


米拉·穆拉提重返公众视野,谨慎发声
穆拉蒂时隔18个月首次接受重大媒体采访,介绍其创立的Thinking Machines Lab正在开发的"交互模型"。该模型能以200毫秒间隔处理音频、文本和视频流,捕捉人类交流中的中断、修正和停顿。她还谈及OpenAI"政变周"经历,强调行业决策权过于集中的担忧,并回应了公司近期研究人员离职问题,表示这是初创实验室的正常波动。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

特斯拉疑似删除FSD证据,卡特彼勒加速电动化布局,高压系统技术培训刻不容缓
本期《Quick Charge》播客涵盖多个热点话题:特斯拉疑似试图删除FSD欺诈相关证据以规避巨额赔付;卡特彼勒持续推进建筑领域电气化布局;住宅太阳能30%税收抵免即将到期。此外,嘉宾Tom Pacheco就高压系统与电池技术培训展开探讨,强调电动车技术人才培养的紧迫性。节目同时提醒有意安装太阳能的用户尽快行动,可通过EnergySage平台比较多家安装商报价。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。

