
Figma也开始卷AI了,设计师又要完蛋了?
作为一个曾经干了快10年的老设计狗,现在听到最多的就是:
设计师要完蛋啦~
今天是视觉完蛋了,明天是原画完蛋了,后天是平面完蛋了。
反正听那意思,管你是个啥,但凡粘个设计两字,在AI时代,那你就都得完蛋。
不过在这反反复复听了一年多的完蛋的历史中,啥设计分支职业都听到要完蛋了,唯独有一个分支,却很少听到有朋友跟我说。
那个职业,叫UI设计师。
嗯,恰好就是我的职业。至于UI这玩意具体是设计啥的,我贴个百度百科的截图吧。

注意这句话:

就怎么说呢,大家开心就好。
狭义的UI设计,就是画你我手上的各种APP、网页等等的视觉界面的;至于广义的UI设计,就是得会UI、交互、用研、产品,最好还能手撸个前端代码,别问为啥广义的UI要会这么多,问就是时代变了。
然后昨天,好几个UI朋友跑来疯狂的跟我说:
卧槽,UI设计完球了。
我说你慌个球,什么情况,淡定的说。
“你去看一眼Figma”
于是我就去看了一下Figma的更新。
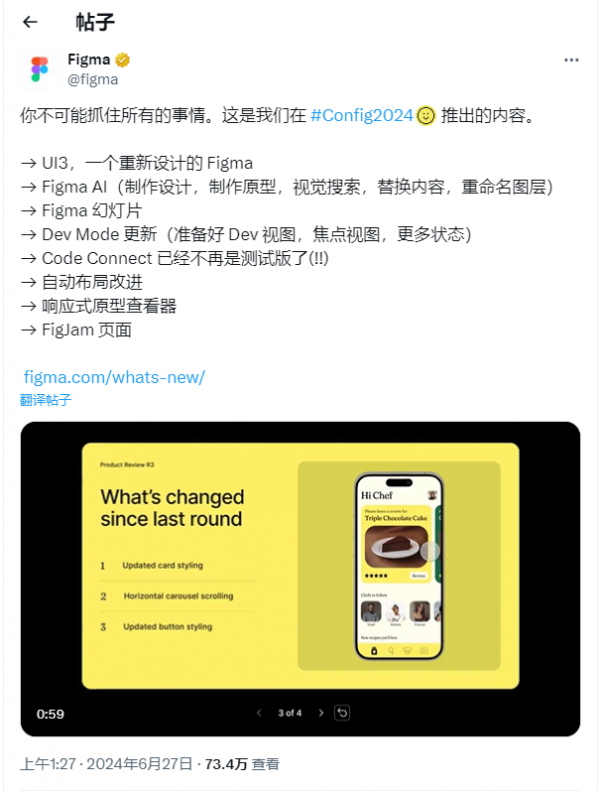
淦。
Figma在UI设计界是啥地位呢,大概就等于平面设计的PS、大雄的哆啦A梦、金融人的冰美式,简单的说,就是没他干不了活的程度。曾经还有个Sketch能跟他掰掰手腕,现在已经不知道飞哪去了。
现在,憋了一整年,Figma终于把他们的AI给憋出来了。
在没AI之前,UI设计们是怎么干活的呢?
用一个词描述就是工匠,每一个按钮,每一条线,每一个图标,都需要设计师亲自动手去画,活脱脱一个数字时代的打铁匠人。
大一点的UED团队,会有一个设计规范和组件库的东西,在画一些界面的时候,直接挨个拖组件,在画布上搭乐高。
在视觉、插画这些工种被AI武装了一年丢失了50%的兄弟的情况下,Figma终于带着他们的AI来了,要来武装我们的UI设计兄弟了。
难怪我的朋友们说,UI设计要完蛋了。行业完不完我不知道,但是时代的一粒灰,落在个人头上就是一座山,谁也不知道自己是不是那被丢失了50%的兄弟中的一员。
Figma的AI这次最拿得出手的功能,可能就是用一句话生成UI界面。

生成好以后,是带有图层的,设计师都懂这意味着什么,你可以进行后续的二次编辑和修改了!同时你也可以再选中某些特定元素,再用嘴,进行一些修改。
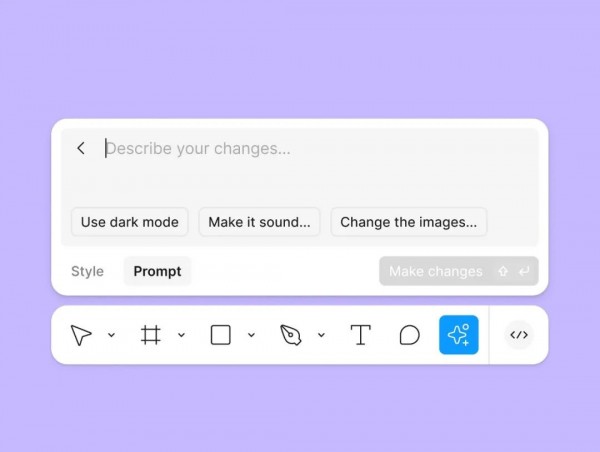
正儿八经的实现了很多老板们梦寐以求的,用嘴做设计。
除了用嘴生成UI设计稿,Figma AI还给你造了一个视觉搜索。
以前我经常拿着一个界面问同事:这你画的不?同事瞄了几眼,说:是啊。
我说你把源文件发我下,他说行,你等我一会,我找找。
然后就是a long long ago,半小时以后,终于给我发了个链接,哥们欣喜的喊着,找到了找到了。感觉他不是从仓库里淘出来了源文件,是从屎山里掏出了一公斤重的大金砖。
现在好了,找到那个设计的截图,往Figma里一丢,嘭!它立马就能帮你找到那个文件。

虽然看着有点像淘宝“找同款”。。。
除了这两个,Figma AI还整了几个花里胡哨的小功能:
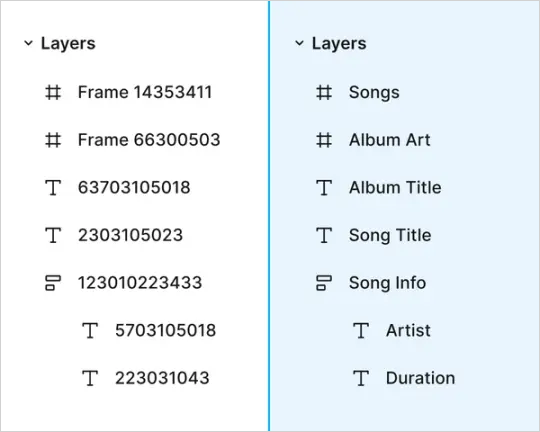
自动命名图层:还记得那些命名混乱的图层吗?
以前设计师们纠结得要死,要不要给每个破图层都起个名字,起了吧累死人,不起吧找起来跟瞎子摸象似的。
“图层1”、“图层2”...简直就像是给多胞胎起名叫熊大、熊二、熊三一样。
现在好了,Figma AI直接给这些图层用AI结合上下文和图层内容,自动起个像样的名字,让你的设计文件不再像个名字大杂烩。
以上这些,就是Figma AI的所有内容了。
你没听错,没了。
只能说,如果Figma早发布半年,甚至是早三个月,没准都能引起一场轰动。
从去年6月的Config大会上,宣布收购Jordan Singer的Diagram团队开始表明全力进军AI。经过一年时间整出来的这些功能,说实话,我觉得有点敷衍了事。
并不是不实用,只是,没有任何想象力和惊喜可言,都是所有人都能预期到的存在,就是四处缝,要是都能做得特别牛逼也行,就正式版一发布怕做成个四不像。
Figma找到了自己的AI创新之路吗?我觉得还远没有,现在感觉还是在被动防御。
那架势就是你们都做了我不能不做啊,然后捣鼓半天,终于掏出个玩意,到处给大家看,说,你看你看,我真的有,还挺大的,赶紧来试试啊。
但是我们又不得不承认,他们也确实在努力拓展自己的版图。这次除了AI,还搞出来个Figma Slides,Slide如果不熟悉,那他还有个中文名,叫PPT。
Figma的首席产品官Yuhki Yamashita说,用户们一直想在Figma里搞PPT,去年一年,用户们硬是在Figma里整出了将近350万个PPT。
现在,我们看不下去了,我们直接给你们整了个标准的PPT制作流程。从设计到演示,你都不用离开Figma这个地方了。
说没有冲击,那是不可能的,因为Figma+AI这玩意儿一出来,UI设计的下限,现在被远远拉高了。
同时对设计师的专业素养和创意脑洞的要求又拉高了一个档次。
好文章,需要你的鼓励


大众汽车推进平价电动车战略,两款新车率先下线
大众汽车旗下ID. Polo与Cupra Raval已在西班牙马托雷尔工厂正式下线投产。两款车型起售价分别为24,995欧元和26,000欧元,均基于MEB+平台打造,搭载37kWh或52kWh电池组,续航里程最高可达454公里。这是大众"电动城市车家族"系列的首批产品,预计今年夏末秋初开始交付。大众集团通过跨品牌资源整合,实现约6亿欧元的成本节约,后续还将推出ID. Cross等新成员。

当AI机器人“自信地“撞向墙壁:STATE16研究院揭示物理AI系统中那些无声无息的致命错误
STATE16研究院这篇综述发现,物理AI系统存在"静默失效"风险——AI以高度自信执行基于错误世界信息的动作,却不触发任何报警,并提出在AI输出与物理执行之间建立独立授权层的框架。

三星Health应用迎来AI升级,Galaxy Watch 9发布前夕更新提前揭晓
三星宣布将于6月8日起为Samsung Health应用推出重磅功能更新,赶在Galaxy Watch 9传闻发布之前落地。新版本将引入多项AI驱动的生物特征分析功能,包括:综合心率、血氧、皮肤温度等数据的每日活力评分(Vitals)、结合体成分数据评估长期心脏健康的心脏健康评分、优化训练强度的每日有氧负荷追踪,以及横向对比用户群体的健身指数。此外,应用界面将重新划分为睡眠、营养、活动、正念和体征五大板块,并新增抗氧化指数、年龄指数和听力保护等个性化功能。

当AI学会“边干边学“:UIUC与微软联合打造的网页智能体训练新范式
UIUC与微软联合研发的OpenWebRL框架让4B小模型仅凭400条初始数据,通过在真实网站上边做边学的强化学习方式,在网页智能体基准上超越了用27万条数据训练的竞争对手。

