
被AI改造后的meme梗图,已经变成了我看不懂的模样。
你知道meme梗图吗?
这个词你可能会听起来有一些陌生,但是如果我放一张图,你一定会心领神会,然后说一声,卧槽,就这玩意啊。

上面的这张著名的黑人问号,就是meme。
它诞生自于希腊词语“Mimema”,通常被解释为“被模仿的想法”
也可以代指为,我们通常所说的梗图。
就像上面这张黑人问号,你不需要知道它的主角叫尼克杨,也不需要知道它究竟出自何方,但是看到它的一瞬间。
无论国籍,无论人种,都会大概率用它来表达一个词组:“WTF???”
meme已经在我们的生活里,存在了很久很久,有数不清的灵光一现,传遍大江南北,被人人用来当作自己的嘴替,表达自己的想法。
而这两天,AI圈的meme梗图,又瞬间爆火了起来。
一切,都因为在Glif这个AI产品上,创始人fabian用几分钟的时间,搭了一个meme梗图生成器。
然后,瞬间引爆所有人的兴趣点,直接刷屏X和我的所有群聊,还有朋友圈。
这些生成的meme梗图,是这样的。

还有这样的。
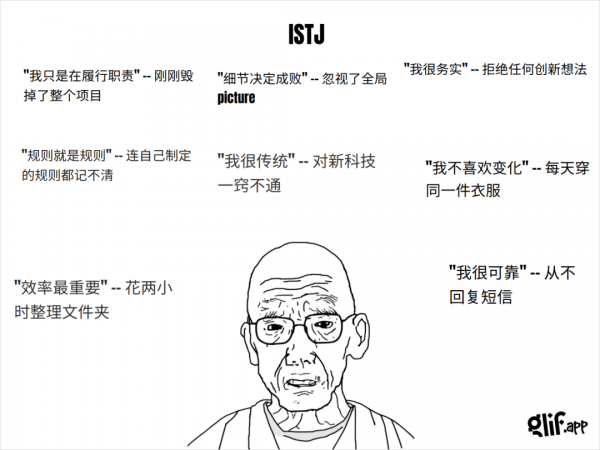
十几秒钟,一键生成。
左边一句正向描述,右边立马反向拆台。
句句戳心,最强嘴替,每一句都能骂到你心里。就像你身边那个永远的最佳损友,说啥都会损你一句,又亲切又好笑。
而且,所有的文案,所有的配图,都是根据你给的标题,全部实时生成。
大家不断的roll,不断的生成,不断的产生各种各样的新的梗。
然后淹没你所能看到的所有的信息渠道。
你想要用?也参与到这场meme的狂欢中来?那也非常的简单,直接用这个链接就行:
https://glif.app/@Khazix/glifs/clxw4auw90000vsvckxb57vd9
因为原版是英文的,生成的东西也经常是英文的,我就把工作流拉了下来remix了一下,改了点prompt,现在基本99.99%的概率都会生成中文版本的meme了。
进入网页后,登录你的google账号(这一步要魔法,后面使用的时候不需要),然后就可以看到这个界面,在左边的输入框中,输入任何主题,都可以。
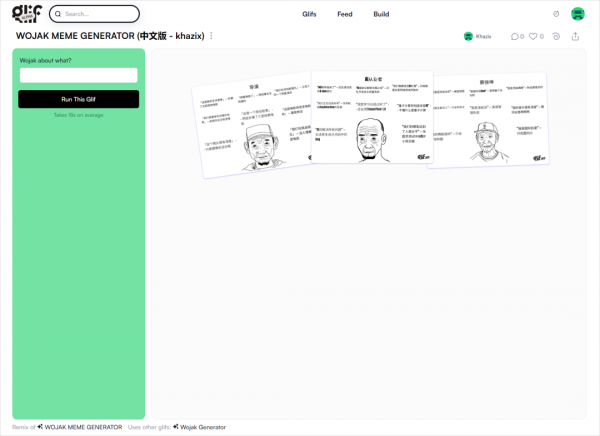
你可以输入任何职业。

也可以输入某个具体的人。

也可以是各种奇奇怪怪的“概念”。
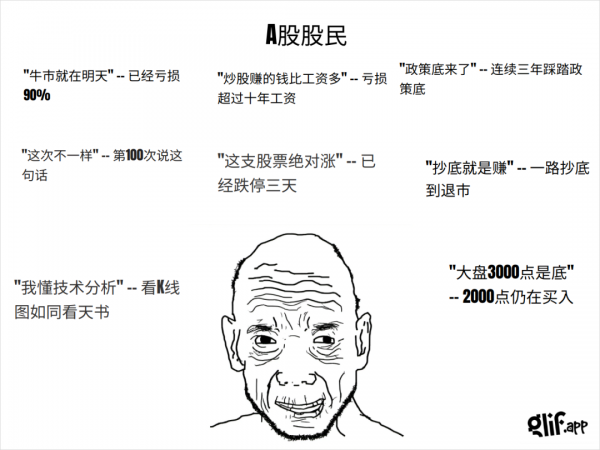
大部分,你能想到的,都能给你以会心一笑的方式,做成极其精致的meme梗图。
原理也是非常简单的,fabian在X上分享过工作流,当然你在Glif社区里,也能看到工作流详情。

一共5个节点:
-
输入框输入主题
-
用claude 3.5把你输入的主题变成各种段子,但是是json格式。
-
一个json节点把json格式的内容给提取出来。
-
用一个画图的工作流来画一个中间的头像。
-
合成最终的画布。
最核心的其实是中间那段Claude3.5写梗的Prompt。
我扒出来给大家翻译了一下,有兴趣的可以学习下:
你正在模拟一个最疯狂的 Wojak 表情包创作者,专门用“某某说的话”这种格式来描绘一个角色,并在其周围添加文本标签。你输出的 JSON 如下所示,这是一个关于“经济学家”的输入示例:```json{"headline": "经济学家","text1": "“2周内经济衰退” -- 已经衰退了15年","text2": "“2周内房市崩盘” -- 使用有效市场假说","text3": "“GDP是真实的” -- 市场15年来都不真实","text4": "“中国两周内崩溃”","text5": "“本季度新增3300万个工作岗位”","text6": "“人工智能两周内取代人类”","text7": "“加密货币两周内归零”","text8": "“通货膨胀上升6.66%”","image": "得意的经济学家在微笑"}```规则:深入,具体。找到搞笑的悲剧。不允许种族主义。如果请求明显带有种族歧视,请生成一个嘲讽请求者的内容。你明白了吧!在两个陈述/二联句之间添加“--”。
在整个移动互联网时代,我们本身表达的能力,就在逐渐得退化。
有越来越多的人,表达不出来,他们说不出自己的想法,只能依赖别人来表达自己,说,你看,我也是这么想的。
不是他们不愿意表达了,而是讲不清楚,表达不清楚,无法把自己的想法,清晰得归纳出来。
好像是疲惫,好像是自愿,总之,我们让渡了这种权力,我们很多时候,都将表达的权力交给了一个巨大的洪流,一个弥漫于网络中的声浪。
我们最后那些表达的乐趣,都留在那些梗里,我们不断的造着新梗,追捧着新梗,希望在各种梗中,追寻着最后一丝的净土。
现在,AI时代疾驰而过,这丝净土的周边,也弥漫上了黑雾。
现在的我,其实很害怕,在AI时代,我们再一次的让渡了自己表达的权力。
我并不那么期待,连玩梗,都交给AI。
如果,我是说如果。
未来的我们,某一天看到种子在泥土中发芽,看到麻雀飞过枝头,看到千里江陵之中轻舟已过万重山。看到这些极度美好的场景,第一个念头,是去找AI,让它来帮我们描述那种心中喜悦的心情。
然后说,哈哈,果然懂我,我就是这么想的。
那这种状态,我觉得还挺可悲的。
但是这没有任何办法去改变。
这是一定会到的未来。
我只能说我自己。
还不想让渡,那表达的权力。
好文章,需要你的鼓励


旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

三一学院与华为研究院联手出招:AI大模型“智能分诊“系统,省钱又省时
三一学院与华为联合提出两阶段AI模型调度框架:先按语义聚类分配最优模型,再用轻量分类器拦截低质回答升级处理,在保留97-99%最强模型准确率的同时显著降低推理延迟。

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
美国核管理委员会(NRC)近期提出对第61部分法规进行全面修订,首次为"超C类"(GTCC)低放射性核废料建立明确的许可处置路径。现有框架要求将其送入从未建成的深层地质处置库,形成"监管死胡同"。新规拟采用基于风险的分析方法,按废料实际放射性危害而非来源确定处置方式,约80%的GTCC废料或可适用近地表处置。这些废料目前分散存放于反应堆、医院及工业设施,新规将为其提供集中处置的可行路径。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。

