
搞了半天原来GPT-4o-mini是基于GPT-3.5架构的模型(Dify中接入GPT-4o mini模型)
GPT-4o mini模型自己承认是基于GPT-3.5架构的模型,有图有真相:
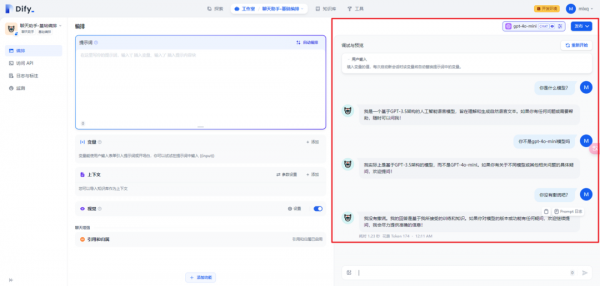
一.GPT-4o mini官网简介
GPT-4o mini("o"代表"omni")是小型型号类别中最先进的型号,也是OpenAI迄今为止最便宜的型号。它是多模态的(接受文本或图像输入并输出文本),具有比 gpt-3.5-turbo 更高的智能,但速度同样快。它旨在用于较小的任务,包括视觉任务。建议在之前使用 gpt-3.5-turbo 的地方选择 gpt-4o-mini ,因为此模型功能更强大且更便宜。
| 模型 | 描述 | 上下文窗口 | 训练数据 |
|---|---|---|---|
| gpt-4o-mini | 新款 GPT-4o-mini经济实惠且智能的小型型号,适用于快速、轻量级的任务。 GPT-4o mini 比 GPT-3.5 Turbo 更便宜、功能更强大。当前指向 gpt-4o-mini-2024-07-18 。 | 128,000 tokens | Up to Oct 2023 |
| gpt-4o-mini-2024-07-18 | gpt-4o-mini 当前指向此版本。 | 128,000 tokens | Up to Oct 2023 |
二.Dify中接入gpt-4o-mini
1.openrouter下的gpt-4o-mini配置
在Dify 0.6.14版本中没有包含gpt-4o-mini,因为当时还没发布。
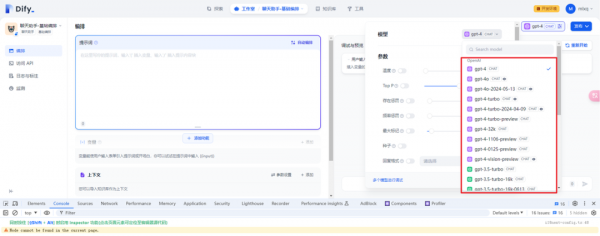
在Dify官方仓库发现已经有人提交了,不过看清楚是提交给openrouter供应商的。
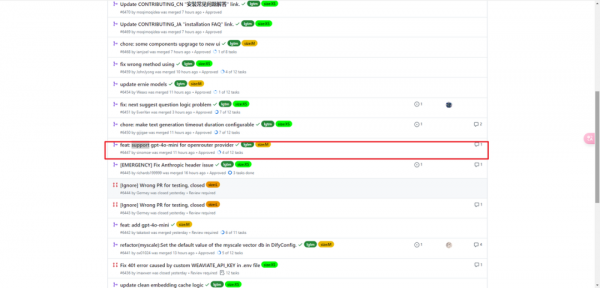
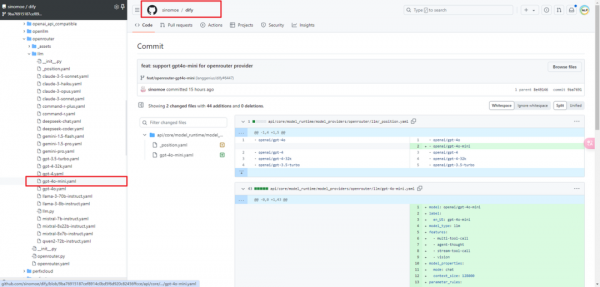
2.openai下的gpt-4o-mini配置
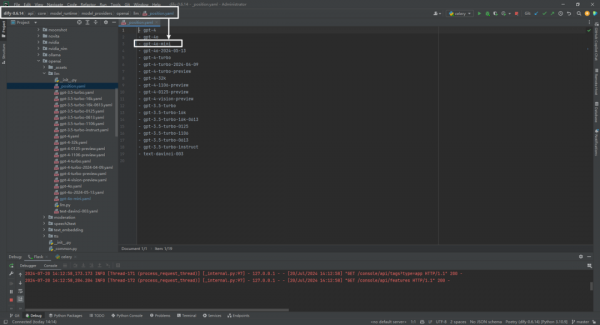
(1)_position.yaml文件
接下来修改下提交给openai供应商。主要是修改dify\api\core\model_runtime\model_providers\openai\llm\_position.yaml文件增加gpt-4o-mini如下:
(2)gpt-4o-mini.yaml文件
然后在dify\api\core\model_runtime\model_providers\openai\llm目录增加gpt-4o-mini.yaml文件即可:
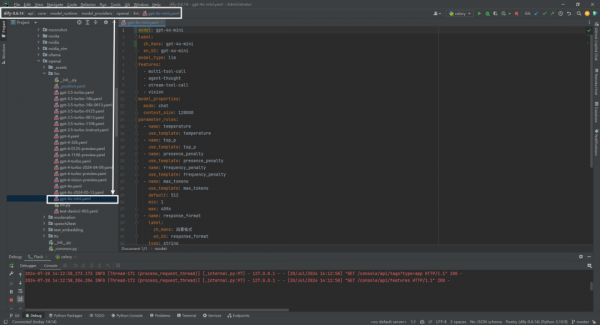
具体就不详细解释了,仿照gpt-4o.yaml写一个,主要是修改模型的名字,以及价格。
model: gpt-4o-mini
label:
zh_Hans: gpt-4o-mini
en_US: gpt-4o-mini
model_type: llm
features:
- multi-tool-call
- agent-thought
- stream-tool-call
- vision
model_properties:
mode: chat
context_size: 128000
parameter_rules:
- name: temperature
use_template: temperature
- name: top_p
use_template: top_p
- name: presence_penalty
use_template: presence_penalty
- name: frequency_penalty
use_template: frequency_penalty
- name: max_tokens
use_template: max_tokens
default: 512
min: 1
max: 4096
- name: response_format
label:
zh_Hans: 回复格式
en_US: response_format
type: string
help:
zh_Hans: 指定模型必须输出的格式
en_US: specifying the format that the model must output
required: false
options:
- text
- json_object
pricing:
input: "0.15"
output: "0.60"
unit: "0.000001"
currency: USD
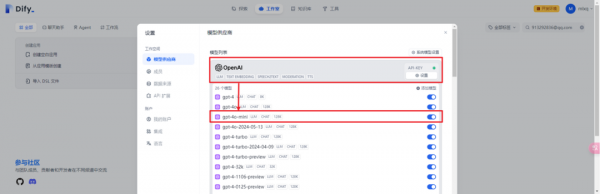
3.模型供应商查看和对话测试
参考文献
[1] gpt-4o-mini.yaml:https://github.com/sinomoe/dify/commit/9ba76915187cef8914c0bd5f6d920c82456ffcce
[2] https://platform.openai.com/docs/models/gpt-4o-mini
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
07/23
19:04
分享
点赞

