成本大降, OpenAI小型模型GPT-4o mini
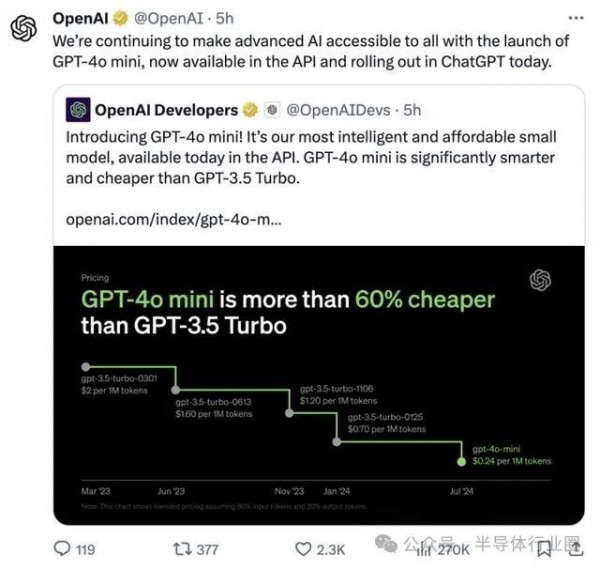
GPT-4o mini输入价格为15美分/百万Tokens,输出价格为60美分/百万Tokens。而曾被视为OpenAI内部最轻量级且高性价比的GPT-3.5 Turbo,其输入价格为50美分/百万Tokens,输出价格为150美分/百万Tokens。
7月19日消息, OpenAI宣布推出GPT-4o mini模型,并称其为最智能、最实惠的模型,其性能和价格均已赶超GPT-3.5 Turbo。
作为直观对比,GPT-4o mini输入价格为15美分/百万Tokens,输出价格为60美分/百万Tokens。而曾被视为OpenAI内部最轻量级且高性价比的GPT-3.5 Turbo,其输入价格为50美分/百万Tokens,输出价格为150美分/百万Tokens。
最新的“GPT-4o mini”比GPT-4o便宜了96%~97%,比起GPT-3.5 Turbo也要便宜60%~70%。正因如此,随着GPT-4o mini上架,GPT-3.5 Turbo的历史使命到此结束。OpenAI还表示,GPT-4o mini是首个使用其全新安全策略“指令层级”的AI模型。
此前,一些没有足够资金的开发者可能对GPT高昂的价格望而却步,转而选择更便宜的模型,例如谷歌的 Gemini 1.5 Flash 或 Anthropic 的 Claude 3 Haiku来构建应用程序。而现在,OpenAI 也正式进入了轻量级模型的市场。
性能方面,目前GPT-4o Mini支持文本和视觉输入,未来将扩展至音视频。它拥有128K上下文窗口,每次请求最多可输出16K标记,知识库更新至2023年10月。而且由于与GPT-4o共享改进的分词器,使其处理非英语文本的成本效益更高。
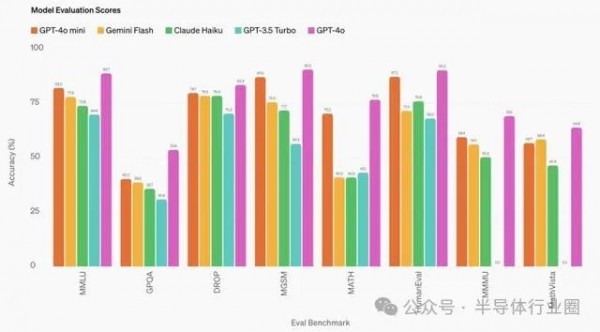
根据OpenAI官方介绍,GPT-4o mini在学术测试中表现优异,超越了GPT-3.5 Turbo等小型模型。它在文本智能、多模态推理和语言支持方面水平与GPT-4o相当。在函数调用方面表现突出,有助于开发者创建能与外部系统交互的应用。此外还显著提升了长上下文处理能力,优于GPT-3.5 Turbo。
GPT-4o mini的高性能来源于GPT-4o,这是OpenAI目前最快、最强大的旗舰大模型。OpenAI在5月的一次直播活动中发布了GPT-4o,“o”代表omni(全能的),寓意了该模型对多模态的注重。彼时,团队表示GPT-4o对音频、视频和文本等多模态理解与生成功能进行了改进,能够以更高的速度和质量处理50种不同的语言。
目前,GPT-4o mini API接口已开放,支持文本和视觉,未来还将融入文本、图像、视频和音频的输入和输出。它将于当地时间周四向ChatGPT的免费用户、ChatGPT Plus和团队订阅者开放,ChatGPT企业用户将于下周开放。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
NVIDIA完整AI计算平台嵌入日本制造、科研、金融与消费市场。
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。