
现在的AI公司们,已经在把用户当"数据提款机"了。
最近,AI公司跟用户之间的冲突与矛盾,变的越来越多越来越大了。
因为一个大家可能从来不看的东西:
用户协议。
最近X(也就是以前的推特)和马斯克,就被这玩意,推上了风口浪尖。
原因是,X被发现“光明正大”的拿用户的帖子来训练Grok AI。
就是马斯克自己搞的那个大模型。
一些平台,拿用户的数据来训练自己的大模型,讲道理这是一件心照不宣的事情,没有谁能避免的。
但是一直以来,这都是一件悄悄的事情,大家也都是偷摸的打枪,从来不敢摆在台面上。
但是这一次,Grok和X,犯了众怒了。
他在没有任何公告、任何通知的情况下,偷偷的上线了一个协议,就是我要用你的帖子、你的数据来训练AI啦,而且这个条款,是默认选中状态,你是默认同意的。
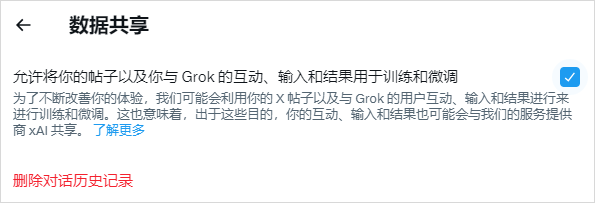
入口隐藏的还极深,你要是不刻意的去找,基本不可能会发现。
最骚的是,你还只能用电脑的网页版才能关,你在手机上,直接找不到这玩意的入口,想关还关不了。。。
直到有用户偶然发现这事,给它爆了出来,直接就把所有用户情绪点燃了,相关讨论的热度迅速飙升,直接在X上,破了千万浏览。
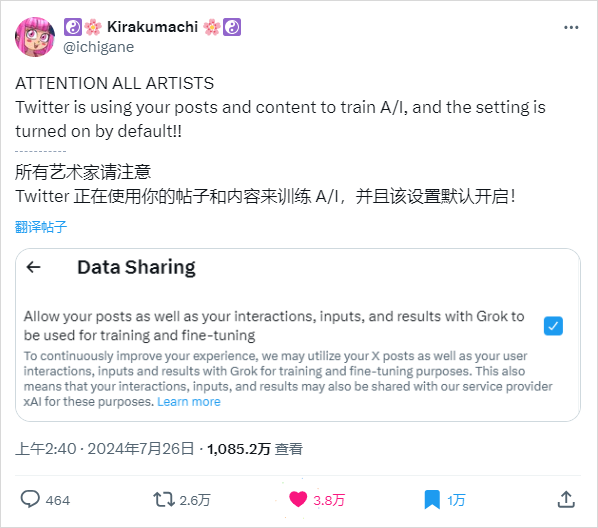
底下的评论,那是骂的要多难听有多难听。


评论只有两个事,要么骂,要么问怎么关闭。
因为你这玩意入口真的藏的太深了,我自己都点了半天。
它在:更多 - 设置和隐私 - 隐私和安全 - 数据分享和个性化 - Grok里面。
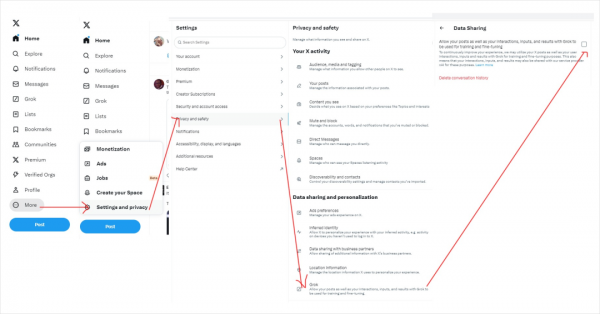
X绝逼是故意的。
热度越吵越高,没办法,把官方逼了出来,终于承认了一下。并且以官方的口吻,来告诉大家怎么关。
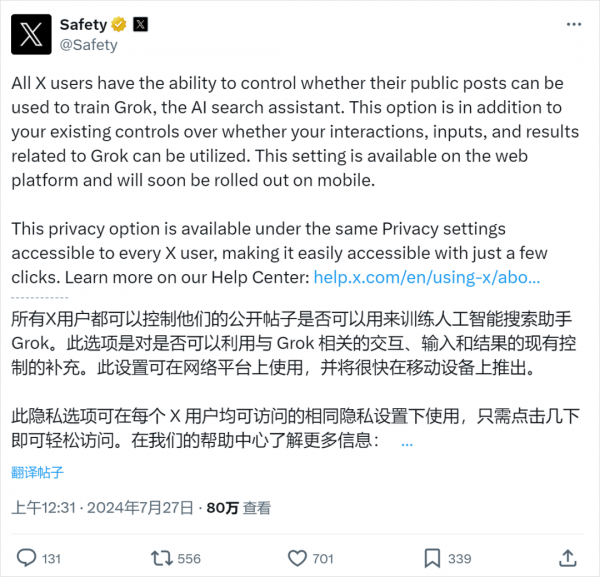
但是通篇读下来,就有一种感觉:给你们这帮子用户能关闭的入口,是给你们的赏赐你们知道吗?别的公司都不给你选项你懂吗?怎么给你们选项了,还在这逼逼赖赖。
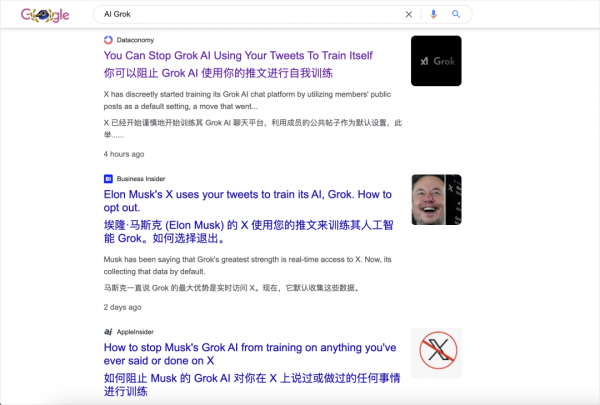
最搞笑的是,最近你去Google一下“AI”+“Grok”,出现的不再是Grok的研发进度,而是这件事,是拿用户数据训练AI的争议。
官方承认的当天不少媒体就迅速对这件事进行了报道。然后你要是往下继续翻,10条有7条是指导用户“如何避免被X用于AI训练”的教程,感觉大家都在疯狂给自己“打补丁”。。。
当然,X肯定不是第一个,只是他们侵犯的用户群体足够庞大,影响过于重大,这事才炒到比较高的热度。
而没有被大家所看到的,不再“尊重”用户的案例,有更多。
比如Meta,想用对个人数据管的比较严的欧洲用户的数据,拿来训模型。搞了个隐私修改,如果用户选择不同意该隐私权政策则应该主动停止使用 Facebook 和Instagram等产品,否则均为接受新政策。
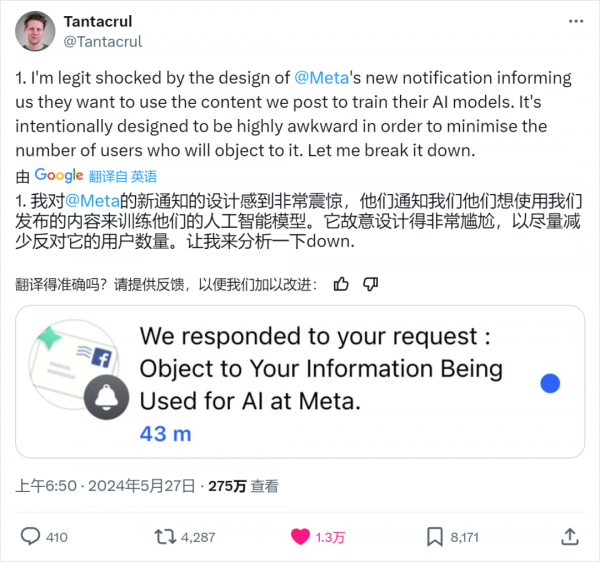
宣布在2024年6月26日生效,然后发出去没几天,就在欧洲掀起了舆论风格,欧盟直接出手,紧急叫停。
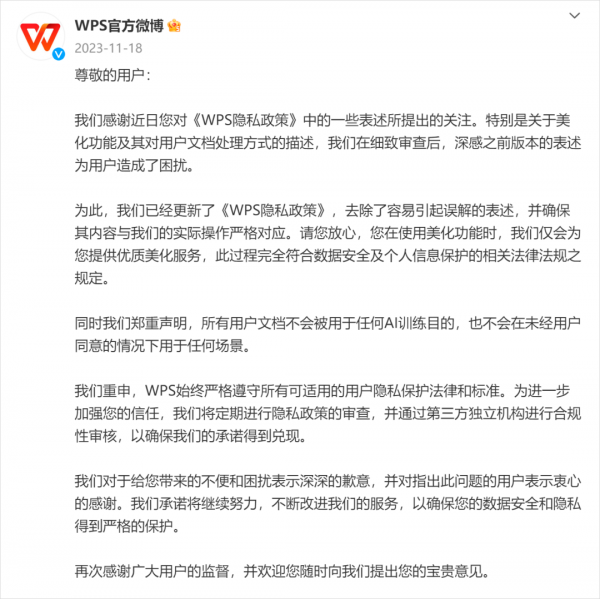
国内的WPS,去年11月,也把心思打到用户的文档上。偷偷摸摸在协议里加了一条:我们将对您主动上传的文档材料,在采取脱敏处理后作为AI训练的基础材料使用。

然后被喷到紧急发公告道歉改协议。
还有前段时间闹的沸沸扬扬的番茄小说AI事件。2024年6~7月,陆续有番茄小说上面的作家收到AI补充协议,要把作品喂给AI,通知你签个条款。
作家圈子直接就炸穿了,中下层作者纷纷加入战斗,一些万粉作家,在书内更新章节,直接写了离开番茄的声明,声泪俱下。

最终,引起了巨量的舆论海啸,几天后,番茄上线线解除相关条款的功能入口,此事才算告一段落。
以上的例子,都是被大规模爆出来的有舆情,且得以善终的例子。
你说大家抵制AI吗?其实在上述的例子中,大家一点都不抵制AI,X上的用户跟Grok聊的有来有回,WPS的用户还是很喜欢用WPS AI,还是有很多作者眼巴巴的期盼着番茄小说的AI润色功能。
大家抵制的从来不是AI,而是你不声不吭,夺我知识取我记忆的行为。
生成式AI发展到今天,互联网的普通数据已经快被挖掘殆尽。
各平台上的大量用户自己的内容,就成了放在面前,最大的宝藏。
这就像明明三体人也没打过来,一群“组织”自己在内斗,一个个疯狂的军备竞赛囤积粮食,他们把这世界上公开的粮食都囤完了,但是还是要更多,于是冲到我家来,抢我家的粮食。
五大三粗的老爷们有的是明抢,踹开你家的房门,跟你说你家的粮食全部上缴我征用了。
还有的是直接从你家厨房里偷摸的拉根运输管道,以后你有多少他偷你多少。直到有天你发现不对,你想找他理论,他说:
管子就在你自己家里啊,你不想给你拔了就行,又不是不让你拔。
这才是大家,愤怒的源泉。
对于创作者尤其是写手画师来说,自己的作品不仅是心血,更是赖以生存的饭碗。
你冲人家里去,抢人家粮食,不给钱就算了,还直接把人饭碗砸了。
前不久,还有一件事,不过不是AI圈的,但是我觉得它很像。
是拼多多下面的海外电商平台Temu。
7月29日,由于平台罚款和扣货款等一系列问题,将近800多名中小商家,直接冲到了广州的Temu公司,进行维权。

因为修改后的协议罚款,因为不透明的规则,因为重压。
但是到底怎么划分,没有一个商家能知道,一切都是不透明的。
包括在Temu上,你买东西,还可以享受90天"不满意全额退款但无需退货"的售后政策,因为是海外物流,成本极高,有时候还不如不退货。
但是不退货就算了,商家还要接受数倍赔付金的惩罚。
比如你卖一件衣服,单价50,一件衣服的利润大概6块钱,5倍支付罚款,也就是意外着50块一件的衣服,要被扣250块钱,而且衣服还不退给你。
关键很多时候,还不是商家的问题,比如客户尺寸不合适,或者漏发了腰带什么的,Temu就直接调货发给客户,还要罚店家两倍的罚款。
于是,在重压之下,商家们终于忍无可忍,选择肉身冲锋Temu总部。
想起了庆余年中邓子越的一段话:
“世间多不公,以血引雷霆”
技术进步不可避免,但是我们也无法忽视人类在这个过程中所失去的东西。
现在的好消息是,人们的反抗在这几个事件中占了上风。
但是坏消息是,只是我们看到的事件中。
如果说Temu的重压,是来自于生存压力,在你签约的那一刻,你会受到平台的压迫,会让你的利益受损,但是你至少,有反悔的余地,你还可以,断臂求生。
但是AI的条款,如果在神不知道鬼不觉的情况下,你被签了。
那你丢掉的,可能不是短期内所能看到的利益。
而是作为独立的人的价值。
你过往的独特的表达,也都成为了一个数据点,一些数字,一串向量,成为了大集体洪流中的一部分。
关键是,未来如果这些AI,产生了收益,那这些也都跟你都毫无关系。
你更像一个被榨干了汁水的甘蔗渣,成了对AI没啥用的废品。
未来如何,没有人能给出答案。
但是我只能说,尽可能的保护好自己。
保护好自己独特的一切。
在这个已经到来的。
黑暗森林。
好文章,需要你的鼓励


我如何整理散落在网络各处的数千张照片和视频
作者历经多年积累了大量照片和视频,分散存储在Google、Apple、Flickr、Dropbox、OneDrive五个云端及多个本地存储设备中。他通过"收集、整理、整合"三步法完成了清理:首先汇总所有存储位置的文件,然后删除模糊、重复及无意义的内容,最后统一迁移至Google Photos。借助去重工具大幅削减冗余文件,并遵循3-2-1备份原则,年订阅费用从近300美元降至60美元以下。

摩德纳大学团队揭秘:AI的“眼睛“和“大脑“为什么总是鸡同鸭讲,他们是怎么修好的?
这项研究提出HeRA方法,通过精准识别语言大模型中对齐最弱的注意力头并施加拓扑对比学习损失,有效提升多模态AI的视觉理解能力,同时抑制视觉幻觉,且不损害语言推理能力。

极端高温考验电网,电动校车“反向充电“成救星
上周北美热浪肆虐之际,电动汽车并未如批评者所担忧的那样加剧电网负担,反而通过V2G(车辆到电网)技术向电网反向输电。目前约230辆电动校车已可向电网提供8兆瓦时电力,足够约1600户家庭使用4小时。加州奥克兰统一学区的74辆电动校车每年可回馈约2.1吉瓦时清洁能源。随着规模扩大,V2G技术还有望降低用电峰值成本,并在自然灾害中为社区提供应急供电保障。

一个模型,随心切换延迟——英伟达与中研院联手打造的万能语音净化引擎
英伟达与台湾中研院提出一种实时通用语音增强框架,单模型支持30种延迟配置,通过并行卷积层和早退机制分别控制算法与计算延迟,性能接近专用模型。

