
Gartner 2024 ДкґжґўјјКхіЙКм¶ИЗъПЯ·ўІјЈ¬SDSІ»ФЩКЗОЁТ»±дёпРФјјКх

ЧоЅьЈ¬Gartner·ўІјБЛОТГЗґжґўИЛКї±ШїґµДТ»ёц±ЁёжЎ¶Hype Cycle for Storage Technologies, 2024Ў·Ј¬ОТЅсМмѕНєНґујТјтµҐ№эТ»ПВЎЈ
УўОД±ЁёжФОДЈ¬ґујТїЙТФЙЁГиЙПГжµД¶юО¬ВлФД¶БЈ¬їЙТФАыУГОўРЕµДИ«ОД·Т빦ДЬёЁЦъФД¶БЎЈ
ЅсДкµД±ЁёжЈ¬єНТФЗ°І»Н¬Ј¬°СКэѕЭ±Ј»¤µДјјКхіЙКм¶ИЗъПЯµҐБРБЛЈ¬Ц»КЈПВґжґўµДЈ¬ХвКЗЧоґуµДІ»Н¬ЎЈ
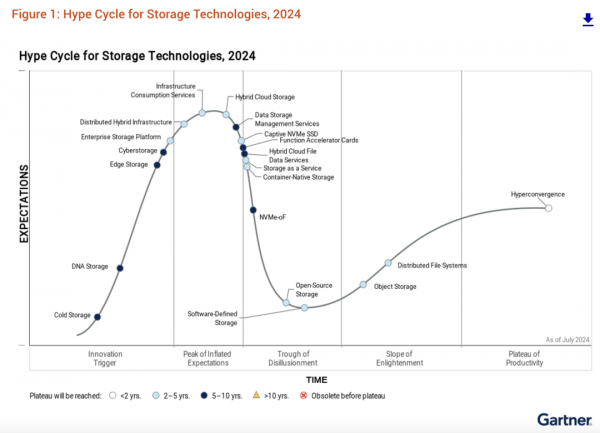
ХвёцКЗЧоЦХµДґжґўјјКхіЙКм¶ИЗъПЯЈ¬ОТГЗїґµЅЈ¬ОТФАґФ¤јЖі¬ИЪєПЧЯПтіЙКмЈ¬ЅсДк»бАлїЄХвёцЗъПЯЈ¬µ«КЗGartner»№КЗ±ЈБфБЛі¬ИЪєПЈ¬»№КЗФЪЧоУТ±ЯµДО»ЦГЎЈїЙДЬGartnerИПОЄHCI»№І»№»іЙКм°ЙЎЈ


ґУјјКхУЕПИј¶ѕШХуїґЈ¬ЅсДк±дёпРФµДјјКхЈ¬іэБЛИнјю¶ЁТеґжґўSDSНвЈ¬»№¶аБЛТ»ёц·ЦІјКЅ»мєП»щґЎЙиК©ЎЈХвКЗЅсДкРВТэИлµДТ»ёцјјКхЈ¬ОТГЗАґїґїґ·ЦОцК¦µД·ЦОцЎЈ


·ЦІјКЅ»мєП»щґЎЙиК©
·ЦОцИЛЈєJulia PalmerЎўPhilip DawsonЧчХЯЈєЦмАтж«-ЕБ¶ыД¬Ўў·ЖАыЖХ-µАЙ
Р§ТжЖАј¶Јє±дёпРФ
КРіЎЙшНёВКЈє5% ЦБ 20% µДДї±кКЬЦЪ
іЙКм¶ИФзЖЪЦчБч
¶ЁТе
Gartner Ѕ«·ЦІјКЅ»мєП»щґЎјЬ№№ (DHI) ¶ЁТеОЄїЙМṩФЖФЙъКфРФµДІъЖ·Ј¬ХвР©КфРФїЙёщѕЭїН»§µДЖ«єГЅшРРІїКрєНІЩЧч - ФЪДЪІїЎў±ЯФµ»т№«№ІФЖЦРЎЈDHI ОЄФЪ·ЦІјКЅ»·ѕіЦРІїКрУ¦УГЅЁБўБЛ»щґЎЙиК©їтјЬЈ¬Н¬К±јбіЦТФФЖОЄЦРРДµД·Ѕ·ЁЎЈХвФцЗїБЛ№¤ЧчёєФШФЪ№«№ІФЖ»щґЎЙиК©·¶О§Ц®НвµДГфЅЭРФєНБй»оРФЎЈ
ОЄєОЦШТЄ
DHI КРіЎµДіцПЦКЗОЄБЛВъЧг»щґЎЙиК©єНФЛУЄ (I&O) БмµјХЯµДРиЗуЈ¬ЛыГЗХэФЪС°ХТДЬ№»ККУ¦ёчЦЦІїКр·Ѕ°ёµД±кЧј»Ї»щґЎЙиК©ЖЅМЁЎЈDHI Ѕвѕц·Ѕ°ёОьТэБЛРиТЄФЖ»щґЎЙиК©јґ·юОсЈЁIaaSЈ©Ѕвѕц·Ѕ°ёµДїН»§Ј¬°ьАЁјЖЛгЧКФґЈЁРйДв»ъ [VM]ЎўВг»ъ»тИЭЖчЈ©ЎўґжґўєННшВз·юОсЈ¬¶шОЮРиЖЅМЁјґ·юОсЈЁPaaSЈ©ІъЖ·ЎЈ
ТµОсУ°Пм
DHI Ѕвѕц·Ѕ°ёОЄ»щґЎЙиК©µчЕдМṩБЛТ»Цֶ๦ДЬ·Ѕ·ЁЈ¬К№ЖуТµДЬ№»ід·ЦАыУГАаЛЖФЖ»щґЎЙиК©µДУЕКЖЈ¬Н¬К±±ЈіЦ¶ФІїКрО»ЦГµДїШЦЖЈ¬±ЬГвТААµМШ¶ЁµДФЖЖЅМЁ»т PaaS ІъЖ·ЎЈ
Зэ¶ЇТтЛШ
DHI Ѕвѕц·Ѕ°ёµДТ»ёцЦчТЄМШµгКЗЖдІїКрСЎПоµДБй»оРФЎЈїН»§їЙТФёщѕЭЧФјєµДПІєГЈ¬ФЪДЪІїЎў№«№ІФЖ»·ѕі»т±ЯФµКµК©ХвР©Ѕвѕц·Ѕ°ёЎЈХвЦЦБй»оРФК№ЖуТµДЬ№»¶ЁЦЖЖд»щґЎЙиК©ІїКрЈ¬ТФВъЧгМШ¶ЁТЄЗуЈ¬ОЮВЫКЗУлКэѕЭЦчИЁЎўСУіЩОКМв»№КЗєП№жРФПа№ШµДТЄЗуЎЈ
DHI НЁ№эМṩФЖФЛУЄДЈКЅµДУЕКЖЈ¬ТФј°ФЪІ»Н¬ІїКріЎѕ°єНК№УГ°ёАэЦРМṩёьёЯµДТ»ЦВРФєНїЙУГРФЈ¬ЅвѕцБЛґ«НіДЪІїІїКр»щґЎЙиК©µДПЮЦЖЎЈDHI ЧоН»іцµДК№УГ°ёАэ°ьАЁ»мєПФЖ»щґЎЙиК©Ўў¶аФЖЎўФЖФЙъУ¦УГЎў±ЯФµєН±ЈЦ¤№¤ЧчёєФШЎЈ
ХП°
ТЄУРР§АыУГ DHI µДУЕКЖЈ¬ЖуТµ±ШРлїЛ·юТ»Р©ХП°ЎЈХвР©ХП°°ьАЁЅвѕцјјДЬІоѕаµДёґФУРФЎў№ЬАн¶аСщ»Ї»·ѕіЎў»ҐІЩЧчРФМфХЅЎў°ІИ«ОКМвЎўіЙ±ѕ№ЬАнОКМвЎўРФДЬєНСУіЩїјВЗЎўЦОАнєНєП№жРФТЄЗуТФј°№©У¦ЙМЛш¶Ё·зПХЎЈ
ІЙУГ DHI µДБнТ»ёцХП°КЗЈ¬ИЛГЗЖХ±йЗгПтУЪІЙУГјЇіЙµД IaaS єН PaaS Ѕвѕц·Ѕ°ёЈ¬јґЛщУР·юОс¶јЧЭПтјЇіЙІўЕд±ё APIЎЈ
ТЄЅвѕцХвР©ХП°Ј¬ѕН±ШРлЅшРРХЅВФ№ж»®Ј¬КµК©ККµ±µДјјКхєН№¤ѕЯЈ¬ІўіЦРшјаїШєНУЕ»ЇЈ¬ТФУРР§№ЬАн DHIЎЈ
УГ»§ЅЁТй
ЖА№АКЧСЎµДјјКхНѕѕ¶--КЗЅ«№«№ІФЖґУФЖЦР·ЦАліцАґЈ¬»№КЗЅ«ЖуТµДЪІї»щґЎЙиК©ДЙИлФЖЦРЎЈОЄГїЦЦ·Ѕ°ёЦЖ¶ЁёЯј¶К№УГ°ёАэЈ¬ІўЖА№АЛьГЗУл№уЧйЦЇІЙУГФЖјјКхєНДЪІїІїКр IT »щґЎјЬ№№µДХЅВФДї±кµДТ»ЦВРФЎЈ
НЁ№эЦЖ¶ЁИ«ГжµДК№УГ°ёАэЈ¬БРіцЛщРиµД»щ±ѕ·юОсєНјжИЭРФ±кЧјЈ¬±аЦЖТ»·Э DHI МṩЙМ¶МГыµҐЎЈИ·±ЈХвР©ТЄЗуід·Ц·ґУі№уЧйЦЇµДРиЗуєНДї±кЎЈ
ёщѕЭПкПёµДК№УГ°ёАэЈ¬»®¶ЁТ»ПµБР№¦ДЬєН·З№¦ДЬТЄЗуЈ¬ЦґРР№¦ДЬКФµг»тёЕДоСйЦ¤ЈЁPOCЈ©ЎЈАыУГКФµг»т POC СйЦ¤У¦УГіМРтЅУїЪµДТ»ЦВРФЈ¬ІўИ·±Ј№©У¦ЙМ±ЈЦ¤О¬»¤УлПЦУРПµНіµДјжИЭРФЎЈ
№©У¦ЙМКѕАэ
°ўАп°Н°НФЖЎўСЗВнС·НшВз·юОсЎўІ©НЁЎў»ЄОЄЎўIBMЎўОўИнЎўNutanixЎўјЧ№ЗОДЎўМЪС¶
ХвёцјјКхЈ¬ґуІї·ЦКЗґУ№«УРФЖПтЖуТµСУЙмЈ¬ИзAWSЈ»ТІУРґУЖуТµПт№«УРФЖСУЙмµДЈ¬ИзNutanixЎЈОч№ПёзёРѕхєН»мєНФЖјјКхУРµгАаЛЖЎЈ
- Container backup
- Cloud infrastructure recovery assurance software
- Digital communications governance
- Data discovery
- Backup as a service
- Isolated recovery environment
- Immutable data vault
- Data classification
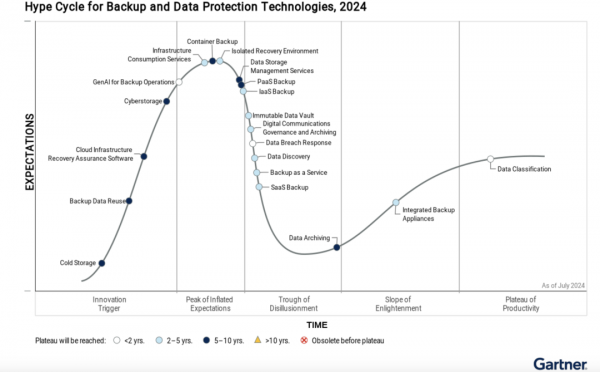
ХвёцѕНКЗGartner·ўІјµДКЧёц¶АБўµД±ё·ЭєНКэѕЭ±Ј»¤јјКхіЙКм¶ИЗъПЯЈ¬їЙП§Хвёц±ЁёжОТФЭК±»№Г»УРХТµЅФОДБґЅУЈ¬Из№ыґујТУРЈ¬їЙТФФЪБфСФАп·ўёшОТЈ¬·Ѕ±гЖдЛы¶БХЯС§П°ЎЈ
УЙУЪјЖЛгґжґўЈЁComputational storage Ј©µДёґФУРФЎўКµУГРФУРПЮТФј°ФЪРРТµЦРИ±·¦ІЙУГЈ¬ЛьТСґУјјКхіЙКм¶ИЗъПЯЦРМЮіэЎЈХвёц·ЗіЈїЙП§Ј¬І»ЦЄµА¶ФScaleFluxХвР©јЖЛгРНґжґўі§ЙМЈ¬КЗ·с»бУРЛщУ°ПмЈї
ґЛНвЈ¬Gartner ЅсДк»№НЖіцБЛОеЦЦРВµДЕдЦГОДјюЈє·ЦІјКЅ»мєП»щґЎјЬ№№ЎўАдґжґўЎў»щґЎјЬ№№Пы·С·юОсЎўЧФСР NVMe SSD єНЖуТµґжґўЖЅМЁЈЁdistributed hybrid infrastructure, cold storage, infrastructure consumption services, captive NVMe SSD and enterprise storage platforms).
±ЁёжЦР»№МбµЅЈ¬2024 ДкјјКхіЙКм¶ИЗъПЯЦРЖА№АµДјјКхЦРЈ¬і¬№эТ»°лЅ«ФЪОґАґОеДкДЪіЙКмЈ¬65%µДјјКхУРЗ±Б¦ґшАґѕЮґуКХТжЎЈ
2024 ДкЈ¬Gartner №ЫІмµЅДіР©јјКхФЪКРіЎЙП»сµГБЛј«ґуµД№ШЧўЎЈХвР©јјКхЅвѕцБЛ»мєПФЖЎўИЭЖчЦ§іЦЎўКэѕЭ№ЬАнєНјґ·юОсІъЖ·µИЦШТЄЗчКЖЎЈАПЕЖєНРВРЛјјКхМṩЙМ¶јНЁ№эТэИлґґРВјјКхЎў·юОсєНЙМТµДЈКЅФЪЛЬФмґжґўКРіЎ·ЅГж·ў»УБЛЧчУГЈ¬ХвР©ґґРВјјКхЎў·юОсєНЙМТµДЈКЅФКРнФЪ±ЯФµєН№«№ІФЖµИІ»Н¬О»ЦГКµПЦґжґў№¦ДЬЎЈЖдЦРТ»Р©ґґРВІаЦШУЪНшВз°ІИ«ЎўїЙіЦРшРФєНЦ§іЦЙъіЙКЅ AI µИРВ№¤ЧчёєФШЎЈ
ёГБмУтЦµµГЧўТвµДїмЛЩ·ўХ№µДјјКх°ьАЁНшВзґжґўЎўґжґўјґ·юОсєНКэѕЭґжґў№ЬАн·юОсЈЁcyberstorage, storage as a service and data storage management services Ј©ЎЈ
АґФґЈєёЯ¶ЛґжґўЦЄК¶
єГОДХВЈ¬РиТЄДгµД№ДАш


°ВФЛј¶±рµДЕ¬Б¦ЈєКЧПЇРЕПў№ЩОЄ2026ДкAIµЯёІЧцЧј±ё
AIµЯёІФ¤јЖЅ«ФЪ2026ДкіЦРшЈ¬НЖ¶ЇЖуТµККУ¦І»¶ПСЭЅшµДјјКхІўА©ґу№жДЈЎЈ№ъјК°ВОЇ»бЎўModernaєНSportradarµДБмµјХЯФЪЕ¦ФјВ·НёЙз·е»бЙП·ЦПнБЛЛыГЗµДAIІЯВФЎЈМЦВЫЅ№µг°ьАЁЧФЅЁAIУл№єВтµЪИэ·ЅЧКФґµДСЎФсЈ¬AIФЪДЪІїБчіМУЕ»ЇєННвІїІъЖ·їЄ·ўЦРµДУ¦УГЈ¬ТФј°РЎРНДЈРНФЪИХіЈУ¦УГЦРµДЗ±Б¦ЎЈЧЁјТЅЁТйЈ¬ЖуТµУ¦Ѕ«AIЅЁЙиИЪИлЖуТµОД»ЇЈ¬ТФґґРВ¶ш·ЗіЙ±ѕЅЪФјОЄЗэ¶ЇБ¦ЎЈ

ЧЦЅЪМш¶Ї·ўІјGARЈєИГAIДЬПсИЛАаТ»Сщѕ«ЧјАнЅвНјПсИОєОЗшУтµДН»ЖЖРФјјКх
ЧЦЅЪМш¶ЇµИ»ъ№№БЄєП·ўІјGARјјКхЈ¬ИГAIДЬН¬К±АнЅвНјПсµДИ«ѕЦєНѕЦІїРЕПўЈ¬КµПЦ¶Ф¶аёцЗшУтјдёґФУ№ШПµµДЧјИ··ЦОцЎЈёГјјКхНЁ№эRoI¶ФЖлМШХчЦШ·Е·Ѕ·ЁЈ¬ФЪ±ЈіЦИ«ѕЦКУТ°µДН¬К±МбИЎѕ«И·ПёЅЪЈ¬ФЪ¶аПоІвКФЦР±нПЦіцЙ«Ј¬ЙхЦБФЪДіР©Цё±кЙПі¬ФЅБЛМе»эёьґуµДДЈРНЈ¬ОЄAIКУѕхАнЅвДЬБ¦ґшАґЦШТЄН»ЖЖЎЈ

SpotifyНЖіцAIІҐ·ЕБР±н№¦ДЬИГУГ»§ХЖїШНЖјцЛг·Ё
SpotifyФЪРВОчАјІвКФНЖіцAIМбКѕІҐ·ЕБР±н№¦ДЬЈ¬УГ»§їЙНЁ№эОДЧЦГиКцРиЗуИГAIёщѕЭЦёБоєНМэёиАъК·ЙъіЙёцРФ»ЇІҐ·ЕБР±нЎЈёГ№¦ДЬФКРнУГ»§ЙиЦГ¶ЁЖЪЛўРВЈ¬Паµ±УЪґґЅЁїЙїШЦЖЛг·ЁµДГїЦЬ·ўПЦІҐ·ЕБР±нЎЈХвКЗSpotifyёіУиУГ»§ёь¶аїШЦЖИЁЕ¬Б¦µДТ»Ії·ЦЈ¬ґЛЗ°ЖдAI DJ№¦ДЬТІФцјУБЛУпТфМбКѕСЎПоЈ¬·ґУіБЛёчЖЅМЁИГУГ»§ёьєГїШЦЖЛг·ЁНЖјцµДЗчКЖЎЈ

Inclusion AIНЖіцНтТЪІОКэЛјО¬ДЈРНRing-1TЈєКЧёцїЄФґµДі¬ґу№жДЈНЖАнТэЗжИзєОЦШЛЬAIЛјїј±ЯЅз
Inclusion AIНЕ¶УНЖіцКЧёцїЄФґНтТЪІОКэЛјО¬ДЈРНRing-1TЈ¬НЁ№эIcePopЎўC3PO++єНASystemИэПоєЛРДјјКхН»ЖЖЈ¬ЅвѕцБЛі¬ґу№жДЈЗї»ЇС§П°СµБ·µДОИ¶ЁРФєНР§ВКДСМвЎЈёГДЈРНФЪAIME-2025»сµГ93.4·ЦЈ¬IMO-2025ґпµЅТшЕЖЛ®ЖЅЈ¬CodeForces»сµГ2088·ЦЈ¬Х№ПЦіцЧїФЅµДКэС§НЖАнєН±аіМДЬБ¦Ј¬ОЄAIНЖАнДЬБ¦·ўХ№КчБўБЛРВµДАпіМ±®ЎЈ
2024
08/30
20:04
·ЦПн
µгФЮ

