
Qwen2-VL:阿里巴巴云计算团队开发的多模态大型语言模型系列
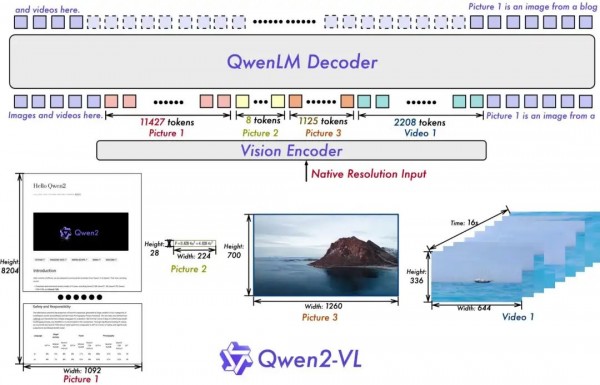
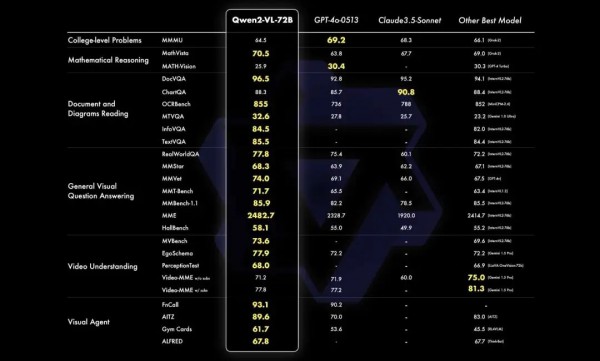
Qwen2-VL:阿里巴巴云计算团队开发的多模态大型语言模型系列,具备处理各种分辨率和比例的图像、理解超过20分钟视频、操作移动设备和机器人、以及支持多语言文本理解等多项先进功能。
参考文献:
[1] http://github.com/QwenLM/Qwen2-VL
[2] https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
[3] https://modelscope.cn/organization/qwen?tab=model
[4] https://qwenlm.github.io/blog/qwen2-vl/
[5] https://huggingface.co/spaces/Qwen/Qwen2-VL
[6] https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

华南理工大学与西湖大学联手破解3D场景生成难题:让AI真正“站在你的角度“看世界
CGGS是华南理工大学与西湖大学联合提出的以自我为中心三维场景生成框架,通过一致性增强多视角扩散模型、光流深度估计和互信息几何优化,实现高保真文本驱动3D场景生成。
2024
09/03
13:04
分享
点赞

