
第一个开源的具有实时对话能力的多模态模型:Mini-Omni
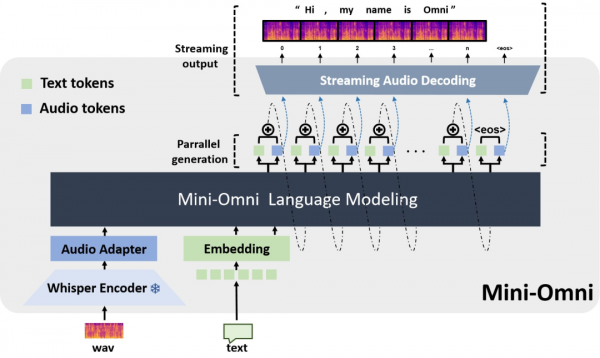
第一个开源的具有实时对话能力的多模态模型:Mini-Omni ,支持端到端的语音输入、输出。Mini-Omni是清华大学启元实验室开源的项目,能听、能说也能实时思考,在实时语音交互上媲美GPT-4o。特点:
- 实时语音到语音的对话能力: 无需额外的ASR或TTS模型
- 边思考边说话: 能够同时生成文本和音频
- 流式音频输出: 支持流式音频输出
- "Any Model Can Talk" 方法: Mini-Omni 可以将语音交互能力添加到其他模型中,为其他模型赋能
参考文献:
[1] github:https://github.com/gpt-omni/mini-omni
[2] 论文:https://arxiv.org/abs/2408.16725
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2024
09/03
20:04
分享
点赞

