
苹果的Camera Control,不止AI入口,要做人机“共生”
早起快速刷了一下苹果的发布会,发现大多数人的评论是:还好没看。其实一开始刷了一些资讯后,我也这么觉得,但是再仔细点一看,发现有些评论认为Camera Control是最重要的创新,但还没有一篇文章,完整的单独针对Camera Control,去好好的写一下思考,是的,翻遍了全网我都没找到,干脆自己快速码一篇。
我看到很有意思的一个讽刺贴是这样:
-May I take a picture of your dog?
-Sure.
-Siri, what kind of dog is this?
推特上有100万的阅读,对应的评论区还有一张图:

那这篇文章我会换个角度,经常尝试多从几个维度抛砖引玉:
-
Camera Control不是简单的按键 -
Visual intelligence整合后炸裂 -
和之前失败的TouchBar会不一样么? -
这些能力开放给第三方,加上App intent会怎样?
01 硬件设计

在上图中的C位,可以很明显的看到两个新iPhone里下面那台,在靠近左侧边框的位置有一个凹槽,这就是Camera Control的新按键,对于这个按键,其实拥有诸多的能力:
功能:
单击:打开相机应用或在已打开相机应用的情况下拍照。
点击并按住:开始录制视频。
轻按:这项功能将于2024年秋季晚些时候推出,可以锁定对焦和曝光在特定主体上。
双轻按:调出最小化相机预览菜单,用于选择不同的控制选项,如曝光或景深。
沿表面滑动:调节参数如缩放、曝光或景深。
设计和技术:相机控制按钮采用电容和压力感应技术,对基于触摸的手势反应灵敏。它被描述为一个触摸敏感按钮,甚至是一个微型触控板,允许进行各种交互,而不仅仅是按压。
也就是说,它的硬件设计是非常深度的,不是一个简单的按键。我们可以看一下:
这个按键的位置设计的还蛮好的,仿照的是数码单反相机上使用快门按钮的体验,它给人带来的惊喜可以看下面这个博主的评测:
02 整合Visual intelligence
这个按钮,更深层次是为了和视觉智能完成整合,达到人机“共生”。即:让手机摄像头最快捷的达到“所见即所得”,并让用户形成惯性。
发布会上苹果专门描述了Visual intelligence和Camera Control的整合,包含了这么几个场景:
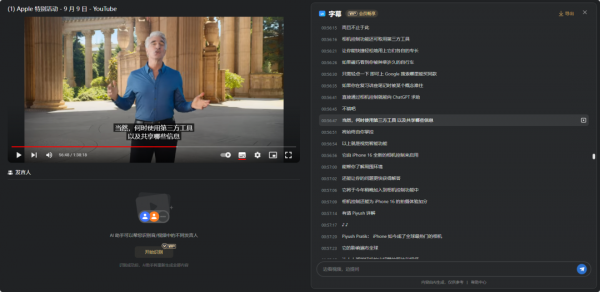
进一步,苹果会开放这两个能力,给到第三方应用去做创新,再结合未来放到端侧的多个模型,还是非常值得期待的:

03 会和TouchBar一样失败么?
也有人拿它和TouchBar来对比,认为Camera Control失败的风险很大,这个点也挺有意思的,值得研究一下。
首先看TouchBar是什么:

Touch Bar 最早出现在 2016 年 10 月发布的第四代 Macbook Pro 上,全称 Multi-Touch Bar,中文名为“触控栏”。你可以理解为这是一块长条形的 OLED 屏幕, 除了固定的功能按键,还能自定义相关按键:

Touch Bar,是苹果历史上比较失败的设计,从出现到退场,仅仅 7 年。
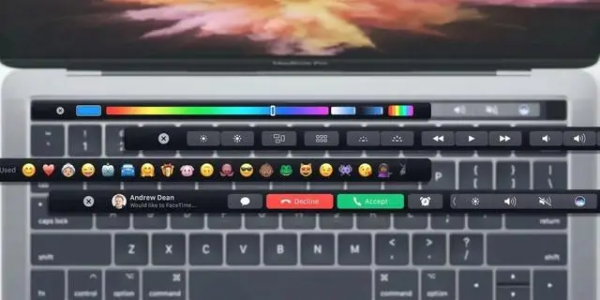
失败的原因,事后来看,就是价值不大,那么小一块屏幕,能显示的内容有限,对应能适配的应用也更多只能是显示按钮,另外就是还需要用户改变自己的操作习惯,同时这些操作大部分又可以用键盘和鼠标代替。
我买的MBP是2015年的版本,恰好早了一代,当时看到2016款的TouchBar时还挺羡慕,但仔细想了想,就觉得意义不大,后面也没再关注了,没想到去年把它下掉了。
OK,说了这么多,其实总结来看,黄叔对于Camera Control是偏向于乐观的,因为相机拍照是个高频刚需场景,一个实体按键(入口)能大幅提高通向这个场景的使用概率,再叠加Visual intelligence,进一步的使用Camera Control去交互,这一点很厉害。
所以,单纯把Camera Control当成通向相机的入口,只是第一层,而把它作为通向视觉智能的入口,才是更深一层!
04 未来构想
对于未来,黄叔感觉最重要的还是用户习惯+AI的融合,在X上看到这条推觉得说的不错:
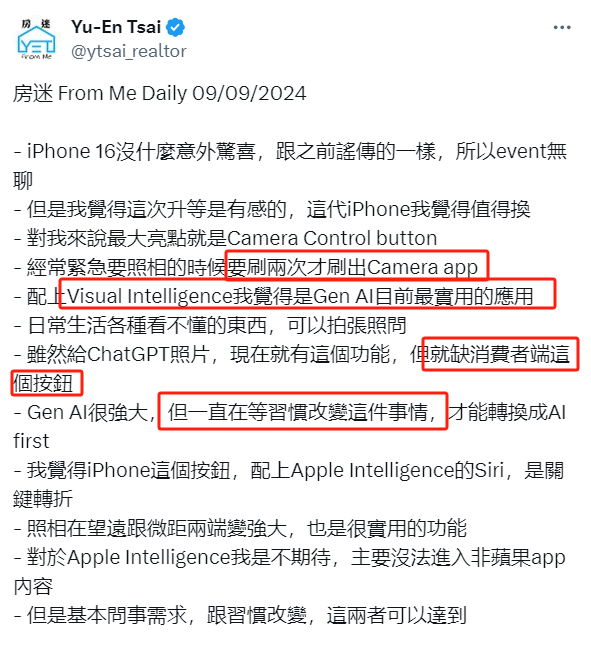
使用物理实体按键启动相机作为视觉多模态入口,一旦用户习惯之后,AI的整合会更加丝滑的嵌入到具体的场景里。
我们不要老指望着AGI,难道AGI没来之前就没法做AI落地了么?苹果在用户理解和场景结合,以及端云整个AI策略的思考上,非常值得我们关注。
结合之前发布会苹果说的“ App Intents”,以及“ Apple as they layer AI on top of the entire OS.”,对于明年AI在手机的落地,我比较乐观。
在新的硬件形态成熟之前,手机仍然会是用户的AI中心设备,以苹果对于生态的整合能力,以及较强的AI落地能力,厚积薄发是我形容它的一个关键词。
我也和一些AI从业者交流,部分朋友是非常兴奋的,更多信息就不放出来了,很期待和大家的更多私下交流呀!
好文章,需要你的鼓励

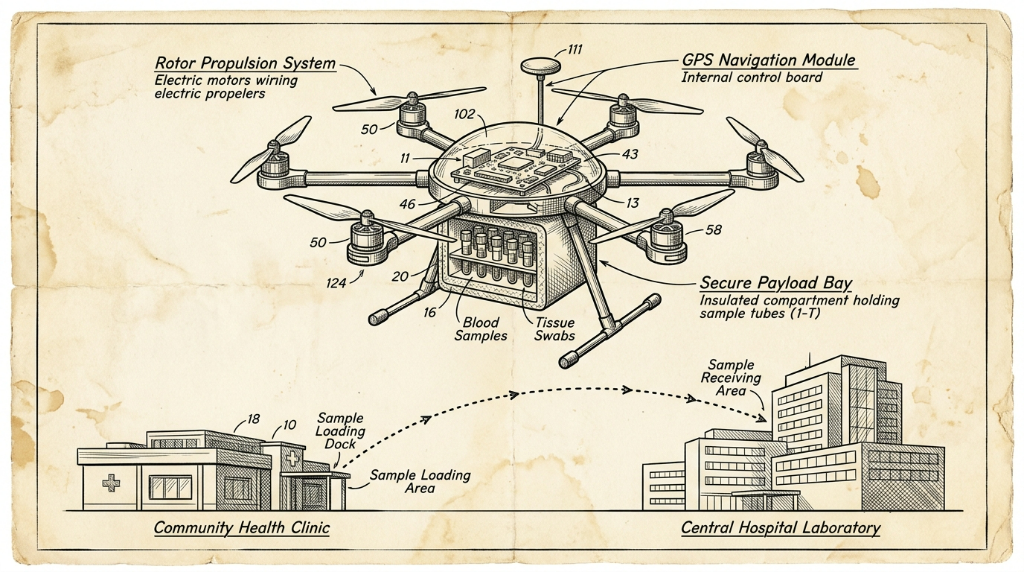
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2024
09/11
13:04
分享
点赞

