
国产AI视频重大突破!角色一致性,Vidu率先做到了
一觉起来,AI视频又双叕要变天了
之前一直困扰各位创作者的“人物一致性问题”,突然迎来了转机。
话不多说,我们先看效果
“一致性”要重点解决的,就是AI生成影视里的IP问题。
“毕竟没有观众想看自己喜欢的电影主角频频换脸吧”
而这一旦被解决,AI创作短剧、电影、绘本、广告等等等等方面的应用都将会有质的飞跃。

比如这里一个广告片的例子

可能上传的商品图片背景、角度都和要做的广告片不相干,但却能生成一些你想要的“高级”效果。

之前想生成同一人物在不同场景的分镜,通常会先用AI绘画的垫图(通常用Midjourney或者sd),或者局部重绘等方法先生成满意的画面,再通过另外的AI视频软件生成动态视频。

操作麻烦不说,保不齐垫图出来不像,还得加一层AI换脸。。。

而现在,只需上传一张参考图就搞定了,何不快哉!
官方的视频合集上面看了,这里我放点自己实测的效果。
先来个索大试试,我用Midjourney生成了个3D版的,有喜欢的朋友可以后台私信多送你几张。

提示词:索隆吃汉堡
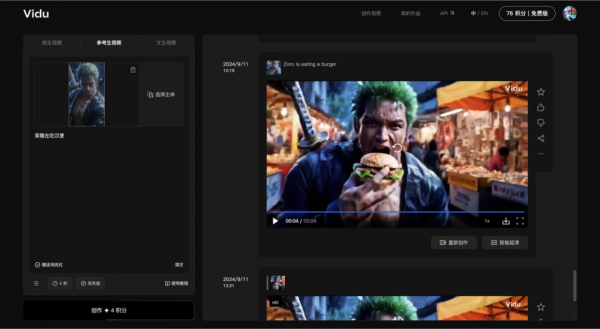
“这标志性绿藻头、胸口上的疤痕、佩刀...”
还原的有点到位!

就是这画质堪忧,Vidu啥时候给提升下。
最近正好在看咒术回战,索性再来个五条悟,也不知道后面复活了没,这次专门找了个2D动漫版的看看效果。

提示词:五条悟在看书

这画风,有一说一确实匹配的让我有些喜出望外,不过同样有点小瑕疵,动作连贯性有待进一步加强,另外,旁边这位女士是...
难道直接预测了五条老师的女友?
不过以上对于一致性问题来说都小问题,等待官方下一版本的优化了,你也可以立即在官网免费体验:https://www.vidu.studio/
日本的网友也玩得飞起,果然一上来就是小姐姐
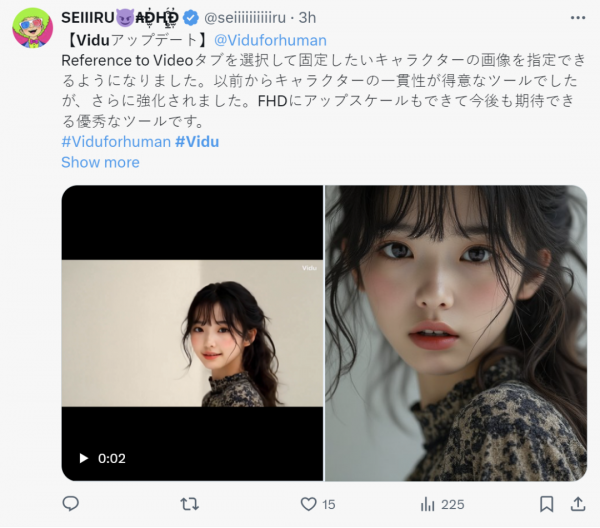
依稀记得半年前AI生成视频另一大Bug“4秒动态PPT效果,运动幅度太小”是咱国产的可灵AI率先开放给大家使用的,这次,是生数科技的Vidu。
而“角色一致性”这一功能,除了同样是我们国内的AI视频生成产品Pixverse有尝试,在Runway和其他软件还暂未看到。
乔老爷子曾经说过:“创新区分领袖和跟随者。”
也许之前,在AI生成视频方面,我们国内的AI厂家普遍都在扮演跟随者的角色。但这一次,不论是可灵AI、Pixverse 的大胆创新,还是Vidu的技术突破,国内的AI技术正在从追赶者转型为引领者,在国际舞台占有重要地位。
不但首发即开放给全球用户体验使用,更是在不断创新,探索AI视频领域的未来走向。
我们曾经在追随,但现在,我们正在引领新的变革。
好了,今天就聊到这里。如果你觉得这篇文章有帮助,记得点赞、收藏、分享给朋友们哦!咱们下次见啦!
附:
Vidu官网:https://www.vidu.studio/
可灵AI官网:https://klingai.kuaishou.com/
Pixverse官网:https://pixverse.ai/
好文章,需要你的鼓励


三祥科技拟1100万美元购入美国代顿厂房,汽车流体管路向液冷与悬架延伸
今天讲的出海案例是三祥科技,这家汽车流体管路厂商拟由北美子公司出资1100万美元,购买美国俄亥俄州代顿工业厂房。

英伟达让AI画图学会“改稿“——一种让图像生成模型懂得自我纠错的新技术
英伟达NLD-Image通过词条编辑机制和分组交叉熵目标,解决了掩码离散扩散模型无法自我纠错及大词典训练困难两大核心问题,实现了高分辨率图像生成的速度与质量双突破。

斯巴鲁新款电动SUV销量已超越Solterra
斯巴鲁今年推出了两款全新电动SUV——Trailseeker和Uncharted,上市仅数月便已超越老款Solterra的销量。2026款Solterra也经历大幅升级,续航提升至288英里,新增14英寸触控屏及电池预热系统,寒冷天气下可在35分钟内从10%充至80%。Trailseeker起售价39,995美元,功率达375马力,可拖拽3,500磅;Uncharted起售价34,995美元,定位更紧凑运动。三款车型均基于斯巴鲁与丰田的合作平台开发。

清华大学如何用“海量免费截图“训练出媲美顶尖AI的电脑操作助手?
清华大学提出GUICrafter,通过自动提取网页交互信号代替人工标注,用不到竞争对手千分之一的数据量,训练出性能相当甚至更优的GUI操作智能体。

