
OpenAI o1模型发布:人工智能迈入深度思考时代
AI,开始深度思考了

当我抛给他一个测试目前AI能力的经典问题:
9.11和9.9谁大?
丢给平时常用的大模型回答:
Kimi
Claude 3.5 Sonnet
ChatGLM
回答迅速,但都是错的
而这是GPT o1-preview的回答

有种我在期末数学考试里最后一道大题绞尽脑汁,结果响铃了要交卷时瞎meng了个错误答案,而隔壁的学霸却是游刃有余,写了多种解题方法还有空检查的感觉。

而这个会思考的AI模型,就是今天OpenAI刚发布的 GPT o1
的“抢先版”,GPT o1-preview
对,还只是个阉割版。
但是水平已经吊打目前市面上的最强模型GPT4o了。
水平如何?
我们可以看到,除了数学和代码方面o1模型“遥遥领先”,在最后的博士级科学问题测试中,o1的78分表现超过了人类博士专家的69.7分,也是世界上第一个在此基准上做到这一点的模型。
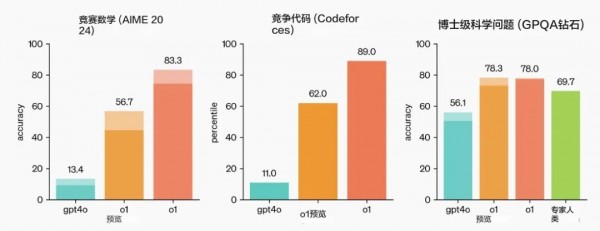
另外在启用视觉感知增强功能后,o1增强版模型在理化生这些大类科学中的得分也媲美该领域的博士专家,尤其是物理学领域可以说是碾压。
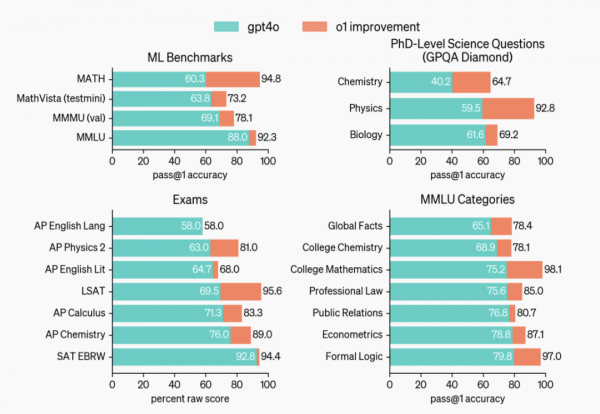
话说咱的老本行就是物理学,
难不成这是在暗示...以后不用读博了?
不过官方也细心的提醒:这些结果并不意味着 o1 在各方面都比博士更有能力——只是意味着该模型在解决一些博士需要解决的问题方面更熟练。
为什么强?
而要细说o1系列模型能力出众的原因,OpenAI官方也给予了解释:
o1系列模型是通过强化学习训练的新型大型语言模型,可以进行复杂的推理。在回答之前会思考,并且可以在响应用户之前生成内部思维链。
通俗点来说就是:“三思而后行”
“思维链”这个过程可以比作是给 AI 一个"思考框架",让它能够像人类专家那样,分步骤、有逻辑地分析问题,而不是简单地给出直接答案。
我找了个解释性的图帮大家更好地理解,多个专家智能体负责不同业务,专注于思考过程的不同方面,比如验证、知识运用、同理心等,以此来提高 AI 输出的质量和可靠性。
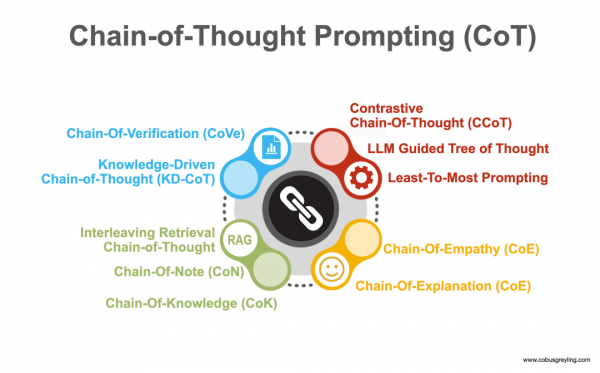
类似我们不同领域的专家组成小组,深度思考、头脑风暴、反复验证后再给出答案。
虽然之前的AutoGPT和其他团队也有过类似的尝试,不过效果貌似达不到这么好。
按照OpenAI的尿性,估计是有什么秘而不宣的方法吧,也欢迎业内技术大佬分享。
贵吗?
官方先放了两个版本的o1让大家玩玩,早鸟版和低配版。
o1-preview:旨在解决跨领域难题的推理模型。
o1-mini:更快、更便宜的推理模型,特别擅长编码、数学和科学。
订阅了Plus和Team的用户立马可以用上,免费用户还得等等

不过因为“思考成本过高”,o1-preview 限制网页和移动端的使用次数是 30 条/周 ,o1-mini是 50 条/周,T5 级别的开发者可以访问其 API,每分钟最多20并发。除此之外还有不少限制。

o1-preview目前的API价格是每百万Token输入/输出分别是15美金和60美金,是gpt-4o价格的4倍。
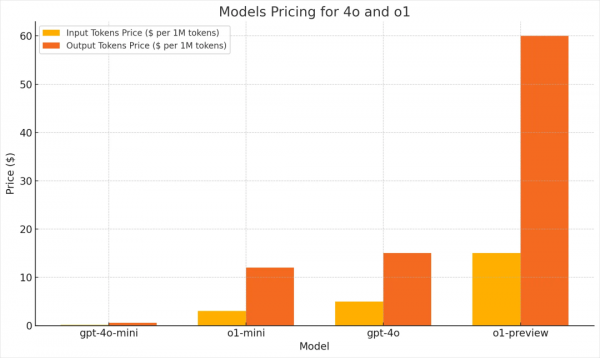
可以理解,毕竟咱和巴菲特吃顿午餐还要1900万美金..

既然o1这么强,
能用来做啥?
可能很多朋友已经用上了,在群里也看到了不少测评,发现o1没有预期的好,甚至有些还不如gpt-4o,
又慢又不好用

一个业内的朋友如是说道,
那这种深度思考的推理又可以用来做什么?
其他还有很多,这里就不一一列举了。
而这种深度的思考推理,正是AGI的起点

我们可以大胆地展开想象,不久的将来,借助借助o1或者o2、o3的力量去探索物理定律的奥秘,揭示材料深层的秘密,解开基因的密码,研发治疗癌症的药物,以及深入太空和宇宙的探索,去触及人类认知的边界...
回到 OpenAI 给这代模型起名叫 o1 的初衷:
For complex reasoning tasks this is a significant advancement and represents a new level of AI capability. Given this, we are resetting the counter back to 1 and naming this series OpenAI o1.
“在处理复杂推理任务方面,这标志着人工智能技术的一次重要进步,展现出了前所未有的能力水平。
因此,我们重置了计数器,使之回归原点,再次从一伊始,并将这一系列产品命名为OpenAI o1,以此纪念这一技术的新篇章。”
现在,AI不仅仅是一个聊天机器人
它更是我们探索未来的眼
最后,期待和大家一起在群里交流探索o1的更多应用场景。如果你觉得这篇文章有帮助,记得点赞、收藏、分享给朋友们哦!咱们下次见啦!
好文章,需要你的鼓励


Netgear推出AI驱动网络管理平台,助力中小企业与服务商
Netgear发布云端网络管理平台Insight 10.0,引入AI驱动能力,专为中小型企业(SME)和托管服务提供商(MSP)设计。新版本提供智能运维、统一可视化、简化管理及云原生架构四大核心升级,支持自动化故障排查、设备健康监控及多站点集中管理,帮助IT团队从被动响应转向主动运维,解决中小企业长期缺乏企业级网络管理工具的痛点。

北京航空航天大学研究团队揭秘:给AI代码助手加几行“路标注释“,导航效率提升了多少?
北京航空航天大学研究发现,向AI代码助手注入轻量级结构注释,可使Bug定位准确率提升2.2%,运行轮次减少1.6次,且运行结果方差减半。

旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

北京大学与DP Technology联手:用135M参数模型打败十亿参数级竞争者,像素级图像生成迎来新突破
北京大学与DP Technology提出PRA框架,通过16维低维中间状态与并行解码像素输入,同时解决像素空间自回归图像生成的高维预测误差和训练推断差距两大瓶颈,135M参数超越19亿参数模型。

