体验完百度世界2024上的iRAG,我觉得AI绘图也可以没有幻觉了。
本质上,他是不是大模型按照自己的知识库回答,然后先通过一些工程化手段,比如联网搜索,比如文档搜索等等,先把相关信息给找出来,让大模型根据这些信息来进行回答。
作为受邀媒体,我现在人在2024百度世界大会现场。
这一小时里,他说了很多重要的东西,有智能体、有很好用的正式上线的自由画布,有一个无代码开发工具秒哒。
但是最让我眼前一亮,觉得有点东西的,可能是一个跟AI绘图有关的产品。
不过在说之前,我觉得还是先需要跟一些产业外的人,科普一下什么叫RAG,就是把百度这个iRAG去掉一个i。
RAG的出现,就是为了解决大模型本身的幻觉的,去年ChatGPT刚出来的时候,很多人都觉得他是万能的学者,无所不能的神。
直到对话对的越来越多,大家才发现,神其实并不是无所不能,神,甚至还会跟你一本正经的胡说八道。
本质上,他是不是大模型按照自己的知识库回答,然后先通过一些工程化手段,比如联网搜索,比如文档搜索等等,先把相关信息给找出来,让大模型根据这些信息来进行回答。
现在你能看到的绝大多数的AI搜索、知识库、AI客服等等,几乎都是RAG的延伸。
但是,这些RAG,你能看到,几乎都是文生文模态的,几乎没有跨模态的而。
而百度这个iRAG,有意思的点就是,他不是解决文字大模型生成的幻觉问题的,而是解决图片的。
没错,图片生成,其实很多时候,跟AI绘图一样,也是有幻觉问题的。
如果你不看实拍照片的对比,让你单看Midjourney生成的天坛照片,你可能还会觉得像模像样的。
但是当你看了实拍,你就会发现,细节的错误实在太多了。天坛的这个标志的祈年殿,是三层蓝瓦金顶,中间挂着祈年殿的牌子。
而AI呢,变成了两层,还把祈年殿的牌子丢了。这个就是幻觉问题,而且在一些实际项目中,危害很大,特别是一些跟甲方的合作项目,你们都懂的。
你但凡甲方的车换一下遭形,你看看他们会不会拿搬砖敲你。
而百度的这个iRAG,他们就是想解决这个问题,所以叫iRAG,image based RAG。
这是他们早上展示的一个case,爱因斯坦在天坛前面抽烟。
左边是iRAG加持后的效果,天坛极准,爱因斯坦也很像。
而右边的四兄弟基本就垮了,有的是天坛崩,有的是任务崩,不过我还真的挺好奇左下那一张是哪家模型的,在没有iRAG的加持下,天坛能那么稳定,还是有点东西的。
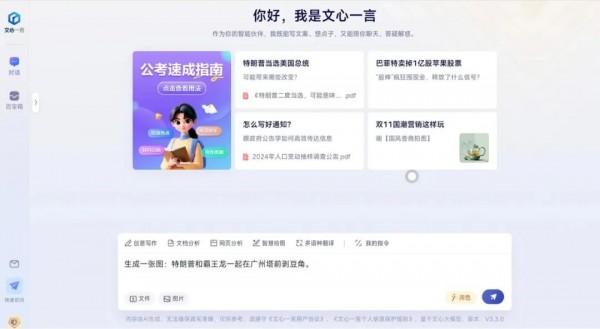
这个东西在早上李彦宏讲话的时候,就应该已经全量上线了,我也以最快的速度去文心一言上做了一波测试。
在李彦宏后面的发言几乎没听、错过了AI眼镜的发布,测了一早上之后。
我觉得这个iRAG确实有用,但是也会有很多它的局限。
对明确的物品、明确的人、明确的场景表现较好,但是对于一些抽象的比如logo之类的东西效果就不尽人意了。
我之前妄图想生成挂着百度logo的腾讯滨海大楼,就会非常的抽象。。。
我的上一部小米折叠屏就长这样,壁纸几乎一样,icon也有小米的影子,就是还有点bug,不是完全一样,但是百度iRAG能做到这个程度,我已经是佩服到底了,更别提,这还是一个甄嬛传的场景,甄嬛的元素,几乎也跟真人一样。
又或者,你可以让建筑,随便出现在任何地方,比如沙漠中的自由女神像。
iRAG的优势在此刻被展现的淋漓尽致,那就是,绝对精准。
整体技术路径虽然百度没说,但是我大概能猜到,就是根据用户要求,先去实时检索图片,然后把这部分图片做一些重绘和注入,加入一些其他的内容。但是肯定会有很多更为繁琐的工程细节。
比如我把我的照片传上去了,让他给我生成一张男人穿着花大袄子在打麻将。
非常坦率的讲,百度的AI绘图底模还不够好,在质量和审美上,跟Midjourney、Flux这种还有一些距离,但是瑕不掩瑜,iRAG作为一种基础能力手段,是可以复刻到所有的AI绘图产品中去的。
我也强烈建议,所有的AI绘图产品,把iRAG这种技术,用在自己的产品里面。
Midjourney如果加上iRAG,那想象空间是真的大。
希望后面,再度进化,能再给这个行业,一些小小的震撼。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
NVIDIA完整AI计算平台嵌入日本制造、科研、金融与消费市场。
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。