体操运动,是所有AI视频最残酷的图灵测试。
我们得聊聊体操运动有多难。一个标准的体操动作,比如后空翻加转体720度,看起来只有短短两秒钟,但这两秒钟里,有大概三重对于AI来说非常地狱的难点。
坦率的讲, 产品完成度很高,但是模型质量,真的有点不及预期。
而是,昨天白天测试Sora的时候,生成的一段让我发了很久的呆的体操视频。
在我这玩AI视频的一年里面,体操,好像永远都是所有AI视频的噩梦。
不管是Sora、Luma,还是可灵、Runway等等,在生成体操视频时都会翻车。
当年大家都在用威尔斯吃面来衡量AI视频时,但其实,体操才是真正的那个门神。
五个月前,DiT视频模型刚刚出来的时候,一段Luma生成的体操视频在X上就引发轩然大波。
视频里面,运动员的四肢在空中扭曲变形。这段由Luma生成的视频不仅让近百万网友围观,还让包括LeCun在内的AI大佬们吵得不可开交。
如今5个月过去,现在其实这个问题,几乎已经有了共识。
回到体操运动,为啥人的跑步、走路等动作现在几乎很好,很多动物的也很稳定,但一旦涉及到复杂动作,特别是体操这种,就直接炸了呢?
一个标准的体操动作,比如后空翻加转体720度,看起来只有短短两秒钟,但这两秒钟里,有大概三重对于AI来说非常地狱的难点。
体操运动,是要在一瞬间爆发出足够的力量起跳,在空中完成两周旋转,然后稳稳落地。
这个过程中涉及了重力、惯性、角动量守恒等多个物理定律。坦率的讲,起跳角度差1度、力量差一分,你可能最后都是落地不稳。
在现实世界中,一个体操运动员要经过至少十年的训练,才能这些刻在记忆里、刻在肌肉里。而AI要在短短的训练过程中领悟这些规律,难度可想而知。
人的身体结构极其复杂,206块骨头、超过600块肌肉。
对于人类来说,这种配合是与生俱来的本能。但对AI来说,理解这种复杂的生物力学系统却是一个巨大的挑战。
就像在AI绘画时经常会画出六根手指的人一样,AI在生成一些复杂动作时,也经常会在生物力学层面犯下很多致命错误。比如肘关节反向弯曲、膝盖过度旋转等等,还有最经典的,转身是真的只转身不转头。。。
这些错误之所以会发生,是因为AI并不真正理解人体的构造限制。它不知道人的关节只能在特定角度活动,不懂得肌肉群之间的协同关系,更不理解人体在高速运动时的生物力学特性。
更重要的是,AI不理解"疼痛"这个概念。在现实中,疼痛是人体对不合理动作的自然反馈,是保护机制的一部分。但AI生成的动作中,可不管你痛不痛,能动就行。
这就好比让一个对人体结构一无所知的画家,闭着眼睛画一个体操运动员的动作连续图。他可能会画出看似流畅,实则完全违背人体工程学的画面。
而这种生物力学上的局限性,恰恰是AI在生成体操视频时最难突破的瓶颈之一。
动作的优美程度、身体的线条感、整体的韵律美,都是体操比赛中的重要评分标准。一个动作即使完成了技术动作,如果缺乏美感,一样会被扣分。
有人说AI生成体操视频失败是因为训练数据不足,有人说是数据集模糊处理导致模型无法理解人体结构。
但更深层的问题我觉得还是在于:AI终究还是在完美模仿。
就像一只鹦鹉再怎么会模仿人类说话,它也不知道它所说的话是什么意思,哪怕它对答如流。
我觉得对现在的大模型如此、对AI绘图如此、对AI视频,更是如此。
当AI生成视频时,它实际上是在进行一场概率游戏,根据已经见过的画面去猜测下一帧最可能是什么样子。这就像是一个从没学过体操的人,在试图通过看过的视频去复现一个高难度动作。
一些比较前沿的学术届,也尝试引入物理引擎模拟(比如将动作生成与物理模拟器结合),或者在损失函数中加入物理规律约束,但还都在探索阶段,离所谓的世界模拟器,还差太远太远了。
就像图灵测试用人类对话来检验AI的智能水平,体操视频我觉得就是在考验AI对现实世界的理解深度。它需要AI不仅能“完美模仿”,更要理解背后的物理规律、生物力学原理和美学标准。
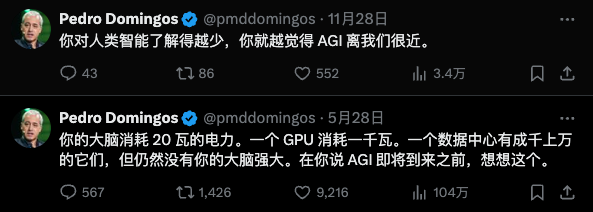
恰恰印证了Pedro Domingos教授的判断。通往AGI的路,也许比我们想象的还要远一些。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标?~谢谢你看我的文章,我们,下次再见。
>/ 作者:卡兹克
>/ 投稿或爆料,请联系邮箱:wzglyay@gmail.com
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。