Google全新发布AI视频Veo2、AI绘图Imagen3 - 何以凌越。
当今最先进的AI视频模型Veo 2,还有AI绘图模型Imagen 3改进版。AI视频Veo 2的效果,真的让我有点想欢呼,甚至,有点像2月16号那个宿命的一夜,看Sora的感觉。
大半夜的,OpenAI的垃圾直播没任何看头,就发了个个性化的AI搜索。
但是,Google没有预告、没有营销,默默的在X上发了两个大货。
当今最先进的AI视频模型Veo 2,还有AI绘图模型Imagen 3改进版。
我几乎从来不使用炸裂这个词,但是AI视频Veo 2的效果,真的让我有点想欢呼,甚至,有点像2月16号那个宿命的一夜,看Sora的感觉。
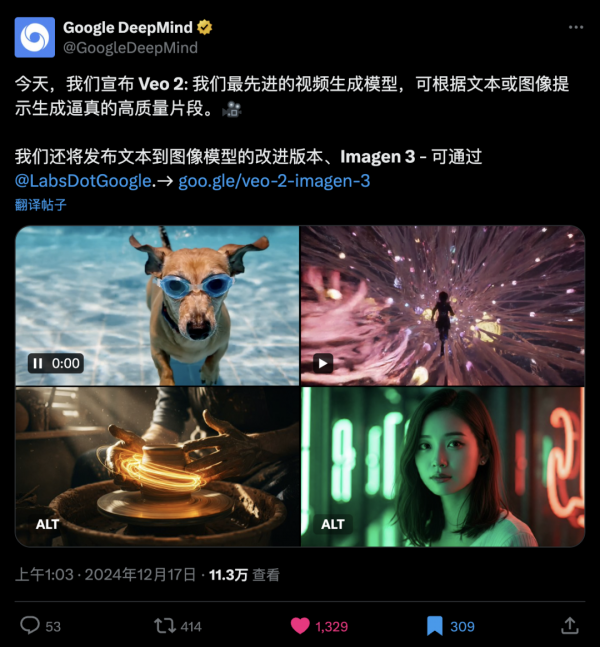
说实话,这些视频,我都不愿意转成gif,而是直接传视频上来给大家看。
这个审美、这个稳定性、这个真实质感、这个物理规律,当得起当今最强的称号。
真的,物理之神,特别是那个切番茄的视频,我一度真的怀疑是实拍的,太恐怖了。
而且,我看了一圈Prompt,发现对拍摄风格、角度、运动等等的语义理解,都极佳。
“低角度跟踪镜头,18mm 镜头。汽车漂移,留下光线和轮胎烟雾的轨迹,创造出视觉上引人注目且抽象的构图。相机低位跟踪,捕捉到流线型的橄榄绿色肌肉车驶向一个拐角。当汽车进行戏剧性的漂移时,镜头变得更加风格化。旋转的轮子和翻滚的轮胎烟雾,在周围城市灯光和镜头光晕的照射下,形成了在黑色沥青上划出的光线和色彩的条纹。城市景观--黄色出租车、霓虹灯和行人--变成了模糊的抽象背景。体积光照增加了深度和氛围,将场景转变为一个视觉上引人注目的运动、光线和城市能量的构图。”
有那么多的开车的AI视频镜头,而这,是我看过的最好的,没有之一。
还有,能直接对一个运动的物体,用Prompt来对其进行超级稳定的多轮材质变化。
稳定到起飞,这也是我第一次,能在AI视频里,见到如此稳定的特效变换的。
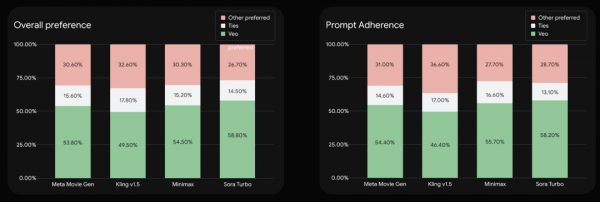
Google自己也做了一个人类观察者的评测,通过Meta发布的基准数据集 MovieGenBench,做了1003个数据,来让大家盲测,哪个效果更好。
这块我稍微解释一下,有两个表,分为Overall Preference(整体偏好度)和Prompt Adherence(提示匹配度)。
每个图表的横轴表示不同的被对比模型,分别是Meta、可灵v1.5、Minimax、Sora Turbo。
Google做的是把Veo 2跟这些模型做点对点的盲测。真的,国产模型居然也能作为对比基准了,突然有一股热血涌上心头。。。
绿色部分(Veo):评测者在对比中更偏好Veo输出的比例。
白色部分(Ties):评测者认为两者不分上下,即没有明显偏好的比例。
粉色部分(Other preferred):评测者更偏好另一模型(非Veo)的比例。
以Google DeepMind浓眉大眼的一贯作风,基本不会造假,所以能看到,Google的Veo 2在大多数情况下,取得了最优结果。
而在Google的评测里,除了Veo 2之外,另外四个模型里,最强的是可灵v1.5,这个结果也是挺有趣的。
而且,有一点是需要注意的,Veo 2,是可以直出4K视频的。
他们在Youtube上传的视频,也是原生4K,这个就非常的恐怖。
他们自己也说,目前最大的难点和限制,还是在运动上。
原话是:“创建真实、动态或复杂的视频,并在复杂场景或具有复杂运动的场景中保持完全一致性仍然是一项挑战。”
说是Badcase,但是我感觉他们发出来的时候估计脸上也都带着笑,那意思就是:
有瑕疵,但是对比Sora这种,这运动质量,已经吊炸天了。
Veo 2网址在此:https://labs.google/fx/tools/video-fx
按照Google的性格,排队肯定要不了多久,不是OpenAI那种纯粹耍猴的,绝不可能一等就是半年,应该很快就能用上。
OpenAI的这波12天直播,感觉彻底把路人缘败光了,之前Google一直被OpenAI恶心的头疼,而这次,直接彻底反击。
你喜欢狙我是吧,来来来,这次Gemini 2、Veo 2、Imagen 3我一个一个放,你不是喜欢抢热度吗?来啊,这次来抢啊,看谁抢谁啊小兔崽子。
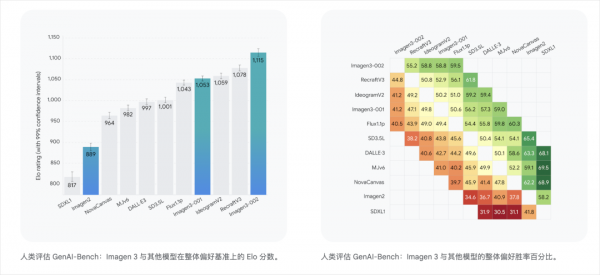
除了Veo 2之外,Google这波还直接发了他们改进版的AI绘图Imagen 3模型,其实严格来说,是Imagen 3-002模型,Imagen 3的第二代。
第一代Imagen 3是2024年5月14日,在谷歌的I/O开发者大会上发的。
半年过去,Google对Imagen 3进行了一次大幅的进化,推出了改进版的第二代,他们自己的评测上,直接屠榜。
网址在此:https://labs.google/fx/zh/tools/image-fx
他们这个Prompt的设计,也很有意思,你可以输入各种奇奇怪怪的一大串Prompt,他会自动给你拆解分词,有点像老罗当年那个胶囊大爆炸的感觉,把一些词分出来后,给你变成下拉框,自动联想几个其他的选项。
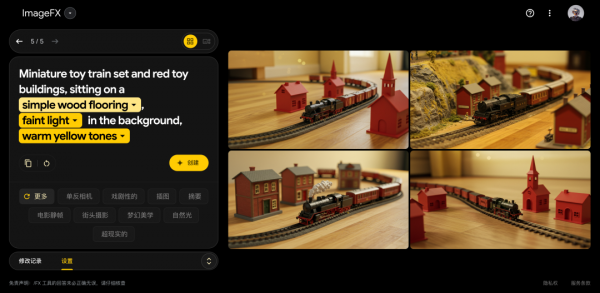
一个穿着巴斯光年服装的小黄人,身穿带翅膀的太空游侠套装,站在一个五彩缤纷的玩具店里,指着天空,仿佛准备起飞,背景是满满的玩具架,生动而富有活力的风格,中景。
一个非常简单的Prompt,我们翻译成英文后,扔到Imagen 3里。
可以自动替换成喷气背包、火箭助推器、滑板车等等,非常有意思。
我们按照它的联想,把背饰换成喷气背包、背景换成电子游戏机房、姿势改成挥手告别,再跑一张看看。
整体看下来,有一种感觉就是,下限贼低,很吃Prompt,要是Prompt写不好,那其实也会出不少很丑的图。
但是语义理解真的挺不错的,上限目前没太测出来,可能还不错。
再遥想今年2月16号,Google的Gemini1.5 Pro被OpenAI的Sora淹的彻底没了声量,而现在,整个局势,好像反了过来。
甚至,很多人都没发现,之前Sora的大功臣,都已经跳槽到Google DeepMind了。。。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标?~谢谢你看我的文章,我们,下次再见。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。
蚂蚁集团AI安全实验室开发的SingGuard是一套多模态内容安全审核系统,能同时理解图片与文字的组合意图,并支持运行时动态传入自定义规则,实现策略自适应的安全判断。
Upstage AI构建韩语宽度搜索基准KO-WIDESEARCH,测试20个AI系统填写完整结构化表格的能力,揭示AI善于找成员却难以填对每格的核心缺陷。