RTX5090震撼发布,一文带你看懂英伟达CES2025发布会。
5090只要1999刀,核算成人民币不提黄牛或者不能进国内这种事,只要不到1w5就能拿下,香到爆炸好吧。5070只要9,在老黄的口径上,性能直接与4090相当,关键是,价格只要4090的三分之一啊。
老黄身穿他一身bulingbuling的鳄鱼皮夹克,正式发布了英伟达的一系列新品。他上来第一句是:
说实话那一下我属实没绷住。而且还非常抽象的模仿了美队,直接拿GB200集群示意图搞了个盾牌。
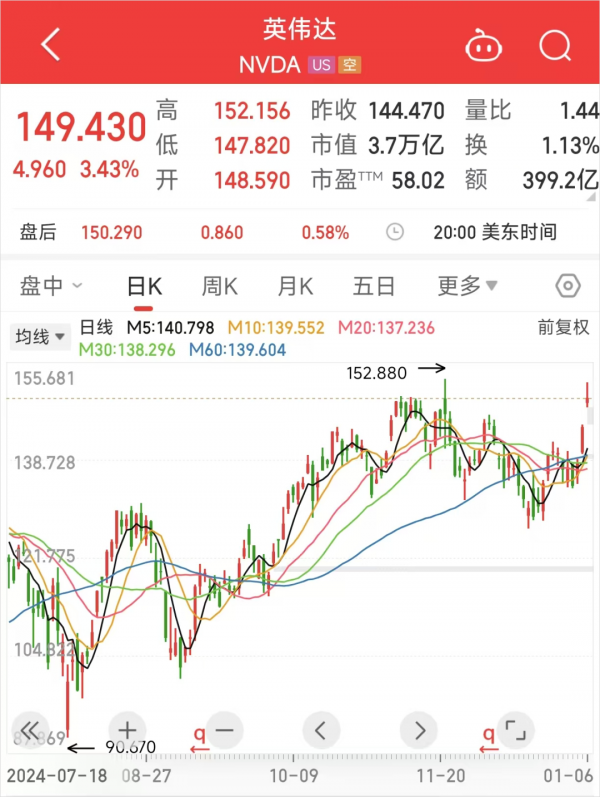
而昨晚,美股给今天发布会的预期也很足,英伟达也差点突破历史新高。
这次发布会的信息量也大到爆炸,基本等于OpenAI一年的直播。
有些不好玩的东西我就不说了,给大家总结一下我觉得有意思的几趴。
话不多说,一文来给大家总结一下,今天的英伟达CES2025发布会。
5090只要1999刀,核算成人民币不提黄牛或者不能进国内这种事,只要不到1w5就能拿下,香到爆炸好吧。
5070只要9,在老黄的口径上,性能直接与4090相当,关键是,价格只要4090的三分之一啊。
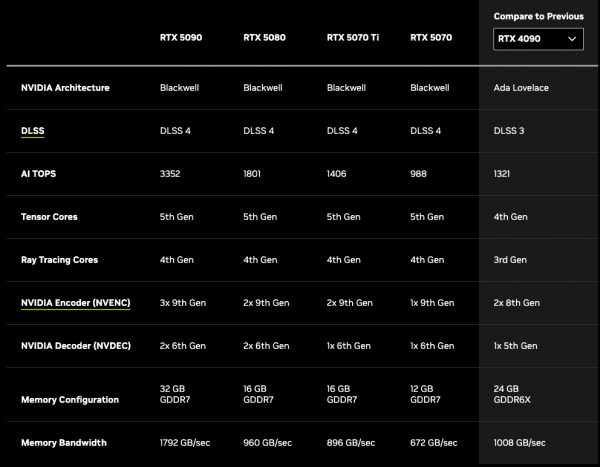
不过这毕竟是老黄的统计口径,整体参数5070跟4090还是有差距,这个说的性能相当大概率是比游戏帧数,毕竟有DLSS 4加持。
老黄这刀法是真的很狠,5090干到32G,但是5080显存还是16G,哎就是不给你升24G,难不难受?特意还给4090留了条活路...
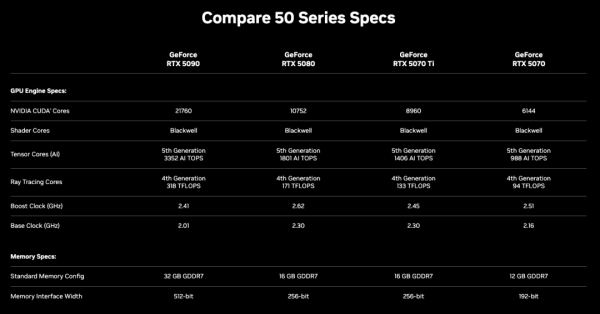
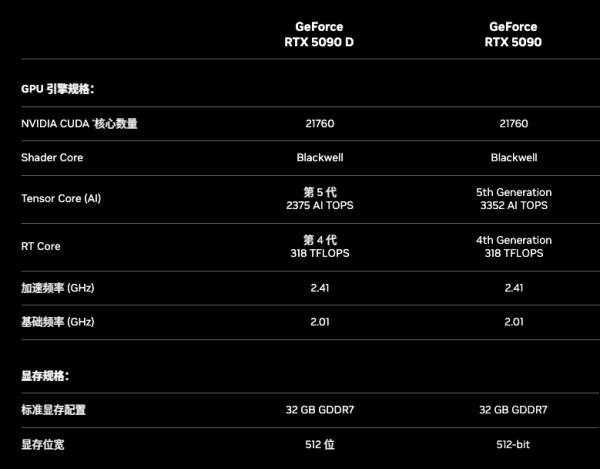
RTX 5090有32GB GDDR7、1792GB/秒的内存带宽和21760个CUDA 内核。得益于DLSS4和Blackwell架构,5090速度将是4090的两倍。
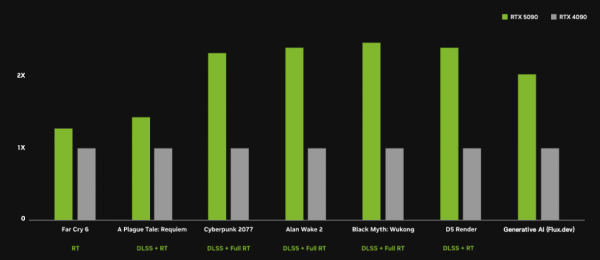
很多人最在意的游戏性能,从英伟达公布的官方对比图来看,5090在开启DLSS 4加全光线追踪的模式下,帧数比4090普遍提升了至少三成,有些项目甚至接近翻倍。
比如赛博朋克2077、心灵杀手2、黑神话悟空这种,绿色长条都高出一大截。
5090的Tensor Core升到第五代,大概3352 AI TOPS,在做张量计算或深度学习推理时,比4090猛特么多了。
过去很多开源模型想要塞进24GB显存常常捉襟见肘,现在有了32GB和更高带宽,就更能从容地跑大模型或更大batch size的推理任务。
功耗上跟之前爆料的600w差不多,5090最后定在了575w。
整机估计要去到1000w左右,又要特么换电源了。。。
- RTX 5080:10752 CUDA 核心,16GB GDDR7,256 位宽,1801 AI TOPS,171 TFLOPS 光追,Base 2.3GHz/Boost 2.62GHz,功耗 360W,官方建议电源 850W,售价 999 美元
- RTX 5070 Ti:8960 CUDA 核心,16GB GDDR7,256 位宽,1406 AI TOPS,133 TFLOPS 光追,Base 2.3GHz/Boost 2.45GHz,功耗 300W,官方建议电源 750W,售价 749 美元
- RTX 5070:6144 CUDA 核心,12GB GDDR7,192 位宽,988 AI TOPS,94 TFLOPS 光追,Base 2.16GHz/Boost 2.51GHz,功耗 250W,官方建议电源 650W,售价 549 美元
当然,因为一些制裁,不得不提的,就是中国特供版,5090D。
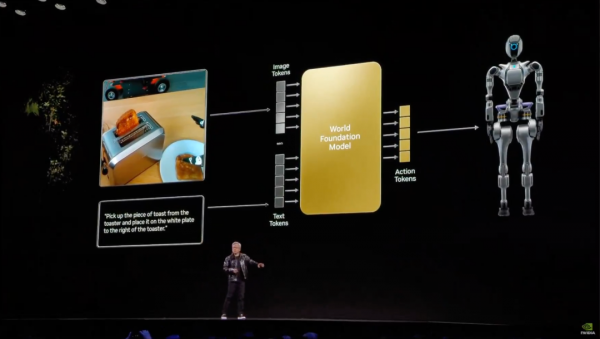
不止要让现在的AI会看图识字,还要能真正读懂物理世界。
Sora刚出来的时候,所有人都在争世界模型是个啥,虽然Sora最后拉了个大胯。
AI只能猜猜那是什么场景,但并不一定知道东西为什么掉下去、球滚动是怎么回事。
老黄拿出的这个世界模型,就是想告诉大家,AI 以后要能明白因果,理解空间和力学,让它见到一个杯子,就知道杯子是易碎的。
你从空中放手,撞到地上就会碎,而不是从地板上弹起来或者融化。
Cosmos是用2000万小时的物理场景视频来训的模型,这个数据量非常的恐怖。
这个数据量emmmm,其实之前英伟达就被爆过,把Youtube视频给扒了个遍。。。
Nano用于低延迟和实时应用,Super用于"高性能基线"模型,Ultra 用于最高质量和保真度输出。
参数数量从40 亿到140亿不等,Nano是最小的,Ultra是最大的。
除了Cosmos,还有一个叫Omniverse的数字孪生和物理仿真平台。
在Omniverse里,你能模拟出一个高度还原现实的三维世界,从工厂到马路,从仓库到城市,每个物体的受力、碰撞都贴近真实。
你可以直接在Omniverse中构建场景世界,再用Cosmos模型生成合成虚拟环境,最终用于人工智能训练,结合起来就像一套高度智能的元宇宙,可以让所有AI在里面练级。
这套组合拳,直接给具身智能、自动价值等等提供了无限可能。
“让一个机器人真正学会怎么移动身体、怎么和物体交互,最少得有三台计算机配合:
第一台是大规模训练系统,比如那些超级 GPU 集群,用来训练基础模型和算法。
第二台就是这个世界模型加数字孪生平台,给机器人提供各种模拟环境和虚拟数据,类似不停地做仿真测试、迭代动作。
第三台才是部署到机器人体内或车里那台小型计算机,负责实时决策和感知处理。”
说真的,现在只要跟数据有关的,英伟达基本全做了,手握算力和数据,英伟达宇宙真的要成了。
这也不难解释,为啥前段世界美国、欧盟、中国三大经济体同时对英伟达出手。。。。
老黄先展示了他家的传统大块头DG 超算,那种机柜式的 GPU 集群,动辄要好几吨重,里面上百张卡,用来训练大模型。
一台就够我们普通人一辈子都没法负担,光供电散热都得是专业数据中心级别。
但是今天,老黄要把这玩意,做成一个跟mac mini一样大小的东西。
里头搭载新款 GB10 Grace Blackwell 超级芯片,能直接本地跑2000亿参数的大模型。
还能把两个连一起,跑4000亿参数的大模型,笑拉了。
这意味着你在桌子上就能跑全套的深度学习训练或推理流程,无需去公有云烧钱。开箱即用。
明年5月上市,价格肯定不平民,目前看到的价格是,3000刀。
贵是真的贵,但是对于一些公司或者团队来说,能把大模型或自定义AI的微调、推理部分留在自己办公室里,数据和项目都更安全,2w真不叫钱。
从老黄秀盾牌的那一刻起,整个CES 2025就已经注定热闹非凡。
不止有老黄,还有各种AI眼镜、AI玩具、AI硬件,在CES 2025疯狂落地。
或许等到明年,再来回顾这个CES 2025,会觉得一切变革都来得太突然。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。
MUSEBENCH是一个专门测试AI理解视听艺术创作意图的评测基准,涵盖电影、视觉艺术、舞台表演和游戏四类,发现最强AI得分仅48%,远低于人类专家87%。
具身智能已经迈过了“能不能做”的门槛,到了需要思考产业化问题的时候。
不列颠哥伦比亚大学与微软研究院提出SEKV,通过熵引导语义分段和GPU-CPU分级存储,在12.8万字上下文下将显存降低53.3%,同时比最强语义压缩基准提升5.9%。