商汤推出“日日新”融合大模型,勇夺“双冠王”
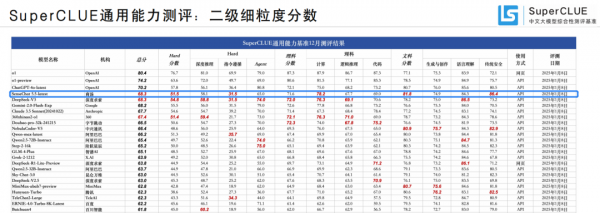
商汤“日日新”融合大模型性能上文理兼修,在SuperCLUE年度评测中,文科成绩以81.8分位列全球第一,超越OpenAI的o1模型;理科成绩夺得金牌,其中计算维度以78.2分位列国内第一。
今年大模型还要如何进化,还有怎样的想象空间?
刚刚,商汤正式推出“日日新”融合大模型,领先实现原生融合模态,深度推理能力与多模态信息处理能力均大幅提升,并在两大权威评测榜单夺得第一,成为“双冠王”。

国内权威大模型测评机构SuperCLUE最新发布的《中文大模型基准测评2024年度报告》:商汤“日日新”融合大模型以总分68.3的优异成绩,与 DeepSeek V3 一起并列国内榜首,成为年度第一。
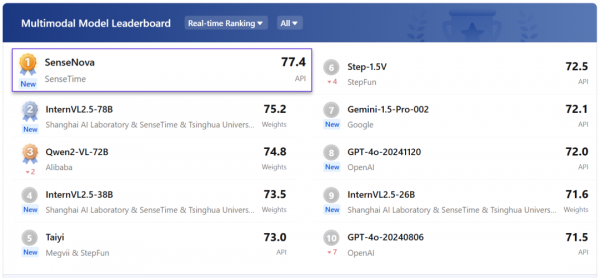
在近期另一个权威综合评测机构OpenCompass的多模态评测中,商汤以同一款模型同样取得了榜单第一,分数大幅领先GPT-4o。
“一个模型、双料冠军”,意味着商汤科技率先在原生融合模态训练取得实质性突破,这将引领业界从大语言模型和多模态大模型分立的普遍现状,走向真正意义的模型一统。
商汤“日日新”突破了模态融合的技术,跨越了模态之间的鸿沟,就为深度推理能力和多模态信息的结合铺平了道路。
商汤“日日新”融合大模型性能上文理兼修,在SuperCLUE年度评测中,文科成绩以81.8分位列全球第一,超越OpenAI的o1模型;理科成绩夺得金牌,其中计算维度以78.2分位列国内第一。
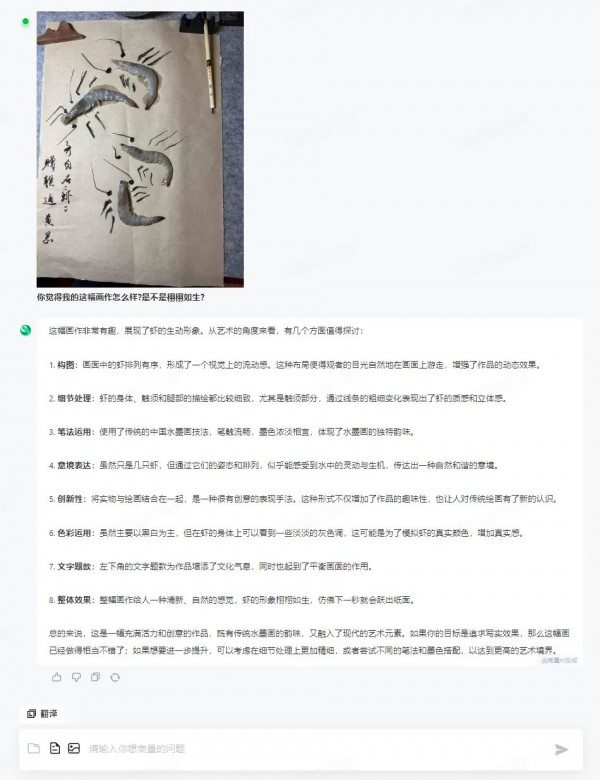
实现原生模态融合后,“日日新”融合大模型不止能达到人类“看”和“想”的水平,还可以帮助你解决更多复杂问题,看不清的字体、数据图表里的信息、文学创作与撰写……这些都可以实现。
英文“草书”难辨认,“日日新”融合大模型识别快速精准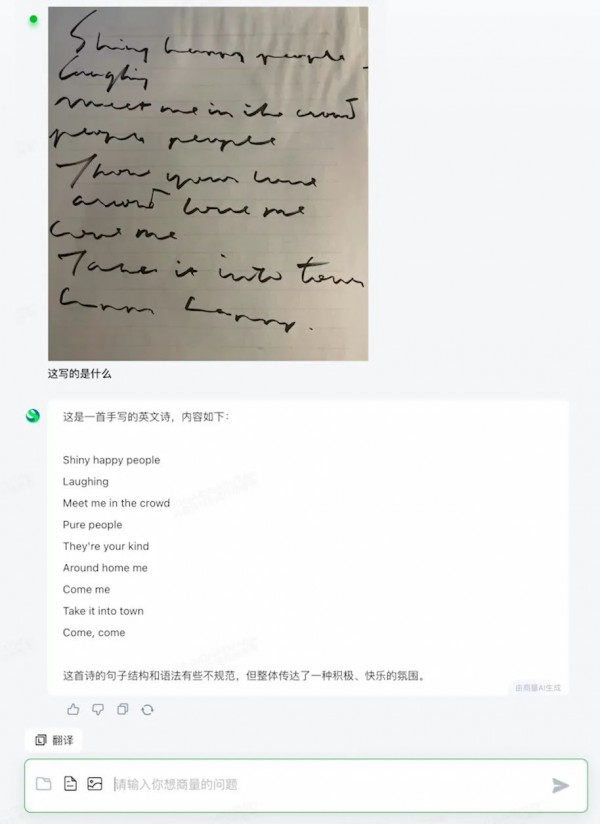 图表分析,关键要素提取、信息分析、给出结论,几个步骤合一迅速完成,省时省力
图表分析,关键要素提取、信息分析、给出结论,几个步骤合一迅速完成,省时省力 解数学题↓↓
解数学题↓↓
解物理题↓↓
创意冷幽默没人懂?“日日新”懂你的奇奇怪怪
文末点击阅读原文,来与“日日新”互动!
在实际应用场景中,相较于传统大语言模型仅支持单一文本输入的模式,"日日新"融合大模型展现出显著优势,尤其是在自动驾驶、视频交互、办公教育、金融、园区管理、工业制造等天然拥有丰富模态信息的场景中。
“日日新"融合大模型能够有效满足用户对图像、视频、语音、文本等多源异构信息的综合处理与识别需求。
例如,在办公、金融领域,其行业属性拥有很多复杂的富模态文档:表格、文本、图片、视频,以及融合上述形式的丰富信息,基于“日日新”融合大模型的商汤应用——办公小浣熊就可以高效地完成处理分析相关的复杂任务。
与此同时,基于融合大模型的优势,商汤“日日新”在视觉交互上也有丰富的应用场景,例如,在线上教育、语音客服等场景,均可以结合语音和自然语言来提升交互体验。
去年年底开始,原生多模态大模型就逐渐成为业内探讨的重要方向。然而由于数据和训练方法的局限,业内很多机构的尝试并不成功——多模态训练过程往往会导致纯语言任务尤其是指令跟随和推理任务的性能严重下降。
得益于在计算机视觉领域十年深耕以及人工智能赋能场景的丰富经验,商汤一直坚信多模态模型是 AI 2.0 进行场景落地的必由之路,对于多模态大模型的研发也有自己的独特见解。在推动语言模型和多模态模型融合的过程中,发展出两项关键的创新技术:融合模态数据合成与融合任务增强训练,进而完成“日日新”融合大模型的训练,推向市场。
在预训练阶段,商汤不仅采用了天然存在的海量图文交错数据,还通过逆渲染、基于混合语义的图像生成等方法合成了大量融合模态数据,在图文模态之间建立起大量交互桥梁,使得模型基座对于模态之间的丰富关系有更扎实的掌握,也为更好地完成跨模态任务打下坚实的基础,从而实现整体性能的提升。
在后训练阶段,商汤基于对广泛业务场景的认知,构建了大量的跨模态任务,包括视频交互、多模态文档分析、城市场景理解、车载场景理解等。通过把这些任务融入到增强训练的过程,商汤的融合模态模型不仅被激发出强大的对多模态信息进行整合理解分析的能力,而且还形成了对业务场景有效的响应能力,走通了应用落地反哺基础模型迭代的闭环。
实现多模态交互与深度融合、走向真正意义的模型一统,是走向世界模型的必经之路,商汤科技已在该赛道实现领跑优势。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。