
Open-Sora Plan项目:旨在重现 OpenAI 的视频生成模型Sora
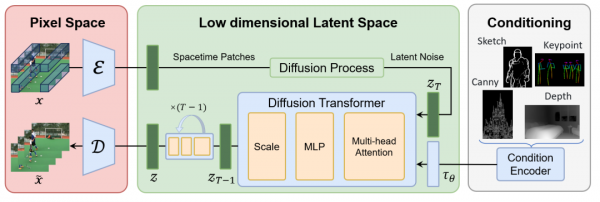
国内一个由北大和Rabbitpre AI发起的Open-Sora Plan的项目,旨在重现 OpenAI 的视频生成模型Sora。技术框架,如下所示:
Video VQ-VAE,这将视频压缩成潜在的时间和空间维度。
Denoising Diffusion Transformer。
Condition Encoder(条件编码器),这支持多个条件输入。
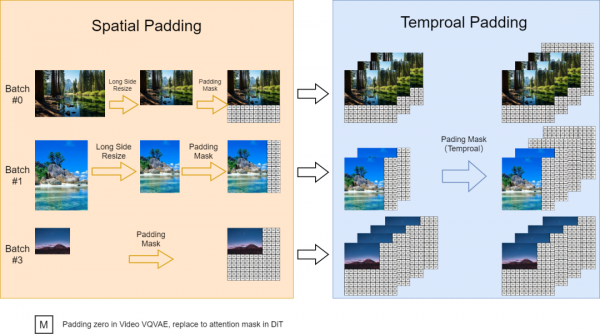
支持可变长宽比、可变分辨率和可变时长,如下所示:
可变长宽比,实现了并行批量训练的动态掩蔽策略,同时参考FIT保持灵活的纵横比。具体来说,调整高分辨率视频的大小,使其最长边为 256 像素,保持宽高比,然后在右侧和底部填充零,以实现一致的 256x256 分辨率。这有助于 videovae 批量编码视频,并方便扩散模型使用自己的注意力掩模对批量潜伏进行去噪。
可变分辨率,在推理过程中,使用位置插值来启用可变分辨率采样,尽管是在固定的 256x256 分辨率上进行训练。将可变分辨率噪声潜伏的位置索引从 [0, seq_length-1] 缩小到 [0, 255],以使它们与预训练范围对齐。这种调整使得基于注意力的扩散模型能够处理更高分辨率的序列。
可变时长,在VideoGPT中使用视频 VQ-VAE将视频压缩为潜在视频,从而实现多持续时间生成。将空间位置插值扩展到时空版本,以处理可变持续时间的视频。
参考文献:
[1] 项目地址:https://pku-yuangroup.github.io/Open-Sora-Plan/
[2] 代码:https://github.com/PKU-YuanGroup/Open-Sora-Plan
来源:NLP工程化
好文章,需要你的鼓励


什么是 Agentic AI?关于人工智能代理的一切须知
本文介绍了 Agentic AI 的概念、特点及应用,强调其自主决策、分解任务与执行复杂目标的能力,并探讨了应用场景与潜在风险。

词汇偏向技术:通过词汇偏向为自回归图像生成模型打造抗重生成攻击的水印方案
这项研究提出了一种名为"词汇偏向水印"(LBW)的新方法,专为自回归图像生成模型设计,能够抵抗传统水印技术容易被删除的重生成攻击。研究团队将代币库分为绿色和红色列表,通过软硬两种偏向策略鼓励模型在生成过程中选择绿色列表中的代币,并采用多绿色列表策略增强安全性。实验表明,LBW在多种攻击下展现出卓越的稳健性,尤其是在面对重生成攻击时表现突出,为AI生成内容的可追溯性提供了更可靠的技术保障。

人工智能是关于关系的吗?
本篇文章以 Navin Chaddha 的采访为主线,阐述了 AI 技术背后人际伙伴关系和早期合作的重要性,以及“协同智能即服务”的理念,强调未来创新依旧由人类主导,技术只是辅助工具。

解锁物体组合的新时代:南方科技大学团队开创几何可编辑与外观保持双重平衡的对象组合技术
南方科技大学林剑满团队开创性提出DGAD模型,解决通用物体组合中几何编辑与外观保持的双重挑战。该方法首先利用语义嵌入隐式捕捉物体几何特性,再通过密集交叉注意力机制精确对齐外观特征,成功实现物体在任意场景中的灵活编辑同时保持细节不变。实验表明,DGAD在编辑灵活性和外观保真度上均优于现有技术,为AR/VR内容创建等应用提供了强大工具。
2024
03/05
14:04
分享
点赞

