
20000 文本提示微调Stable Diffusion!商汤联合上海AI Lab提出CoMa!

论文名:CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
论文链接:https://arxiv.org/pdf/2404.03653.pdf
开源代码:https://caraj7.github.io/comat/

引言
文本到图像生成领域最近随着扩散模型的引入取得了显著进步。然而,对不 一致问题仍然缺乏合理的解释。缓解文本提示和图像之间的不对齐仍然是一个挑战。最近,各种作品提出从语言先验或大语言模型(LLM)中引入外部知识来解决此问题。造成不对齐的根本原因尚未得到充分研究。我们观察到,不对齐是由于令牌注意力激活不足造成的。我们进一步将此现象归因于扩散模型由于其训练范式而导致的条件利用不足。
简介
为解决此问题,我们提出了一种名为CoMat 的端到端扩散模型微调策略,具有图像到文本的概念匹配机制。我们利用图像字幕模型来衡量图像到文本的对齐,并引导扩散模型重新关注被忽略的令牌。还提出了一种新的属性集中模块来解决属性绑定问题。在没有图像或人类偏好数据的情况下,我们只使用20,000 个文本提示来微调 SDXL,以获得 CoMat-SDXL。广泛实验表明,在两个文本到图像对齐基准上,CoMat SDXL 明显优于基线模型SDXL,并取得了最先进的性能。
方法与模型
我们的方法的总体框架由三个模块组成:概念匹配 (Concept Matching)、属性集中(Attribute Concentration)和保真度保留 (Fidelity Preservation)。我们通过图像字幕生成模型说明 了图像到文本的概念匹配机制。随后,我们详细介绍了用于增 强属性绑定的属性集中模块。接下来,我们介绍了如何保留扩 散模型的生成能力。最后,我们结合了这三个部分进行联合学 习。
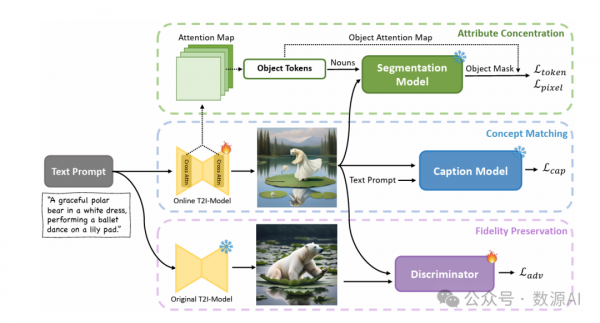
我们认为错位问题背后的根本原因在于对语 境信息利用不充分。因此,即使提供了所有文本条件,扩散模型仍然对某些 tokens 关注不够,从而导致生成的图像中缺少相应的概念。为了解决这个 问题,我们的主要见解是通过监督生成的图像来检测缺失的概念。我们通过 利用图像字幕模型的图像理解能力来实现这一点,它可以根据给定的文本 提示准确地识别生成图像中不存在的概念。在字幕模型的监督下,扩散模型 被迫重新关注文本tokens,以寻找被忽略的条件信息,并将为先前被忽视的 文本概念分配重要权重,从而改善文本与图像之间的对齐。具体来说,对于 给定的提示P 和其单词tokens ,我们首先使用 denoising 函数εθ 在经过T 个denoising 步骤后生成图像 I。然后,使用一个冻结的 图像字幕模型C 以对数似然的形式对提示和图像之间的对齐关系进行打分。因此,我们的训练目标是最小化该分数(表示为Lcap)的负值:
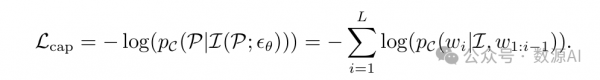
事实上,从标题模型中获得的分数可以被视为微调扩散模型的差异化 奖励。为了在整个迭代去噪过程中进行梯度更新,我们遵循[55] 对去噪网 络εθ 进行微调,通过简单地停止去噪网络输入的梯度来确保训练效果和效 率。此外,注意到图像中的概念包括一个广泛领域,对象的存在和复杂关系 等各种错位问题可以通过我们的概念匹配模块得到缓解。
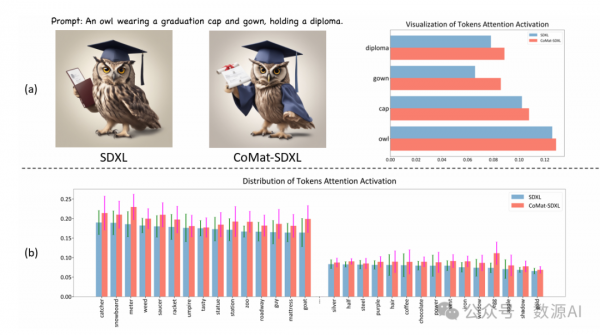
近年来有大量报道指出,属性绑定是文本-图像扩散模型中一个棘手的 难题[40]。如基于 SDXL 模型的图5所示的例子,词语“红色”和“蓝色” 的注意力主要集中在背景上,与其对应的对象几乎没有对齐。我们的概念匹 配模块在一定程度上可以缓解这一问题。然而,由于字幕模型对对象属性的 不敏感,性能提升有限。在这里,为了从更细粒度的角度对实体及其属性进 行对齐,我们引入了属性集中来引导实体的文本描述关注图像中的相应区 域。
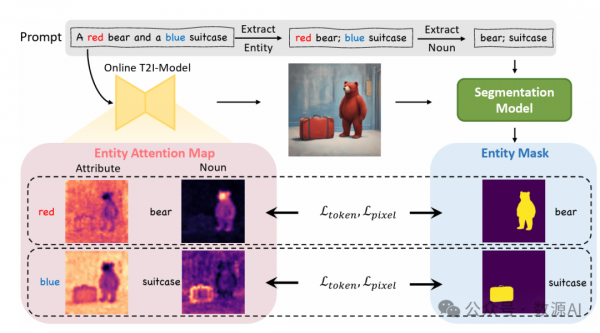
具体来说,我们首先从提示中提取所有实体。实体可以被定 义为名词ni 和其属性ai 的元组,即ei=(ni,ai),其中 ni 和 ai 都是一个 或多个标记的集合。我们采用spaCy 的基于转换器的依存关系解析器[18]
来解析提示,找到所有实体的名词,然后收集每个名词的所有修饰语。我 们手动过滤了抽象名词(例如:场景、气氛、语言)、难以识别其区域的名 词(例如:阳光、噪音、地点)或描述背景的名词(例如:上午、浴室、聚 会)。对于所有经过过滤的名词,我们使用Grounded-SAM[41] 开放词汇分 割模型来找到其对应的区域,并将其表示为二进制掩码。值 得强调的是,考虑到扩散模型可能会将错误的属性分配给对象,我们仅使用 实体的名词作为分割的提示,而不包括其关联的属性。以图5中的“行李 箱”对象为例,即使提示是“蓝色的行李箱”,模型生成的行李箱也是红色 的。因此,如果将提示“蓝色的行李箱”提供给分割器,它将无法识别实体 的区域。这些不准确可能会导致后续流程中的一系列错误。
然后,我们试图将每个实体ei 中名词ni 和属性ai 的注意力集中在由 二进制掩码矩阵Mi表示的相同区域。我们通过添加两个目标的训练监督来 实现这种对齐,即令牌级注意力损失和像素级注意力损失[52]。具体来说, 对于每个实体ei,令牌级注意力损失迫使模型仅在区域Mi 内激活对象令 牌ni∪ai 的注意力,即:
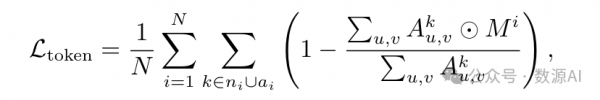
其中⊙表示元素级乘法。
像素级注意力损失通过二元交叉熵损失来进一步强制区域内的每个像 素仅关注对象标记:
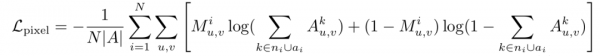
其中|A| 是注意力图上的像素数量。与[52]不同,由于对齐不准确,提示中 的某些对象可能不会出现在生成的图像中。在这种情况下,像素级注意力损 失仍然有效。当掩码完全为零时,它表示当前图像中的所有像素都不应关注 缺失的对象令牌。此外,由于计算成本,我们只计算在线模型图像生成过程 中的r个随机时间步长上的上述两种损失。
由于当前的微调过程完全由图像字幕模型和属性与实体之间关系的先 验知识引导,因此扩散模型可能会快速过拟合奖励,失去其原始能力,并产 生退化的图像(如图6所示)。为了解决这个奖励黑客问题,我们通过引入一 个区分器来提出了一种新型对抗损失,该区分器可以区分由预训练和微调 扩散模型生成的图像。对于鉴别器Dφ,我们遵循[58]的做法,用稳定扩散 模型中的预训练UNet对它进行初始化,该模型与在线训练模型共享相似知 识,预计能够更好地保持其能力。在我们的实践中,这还使对抗损失能够直 接在潜空间中计算,而不是图像空间。此外,必须指出的是,我们的微调模 型不使用真实世界的图像,而是使用原始模型的输出。这种选择的动机是我 们希望保持原始生成分布并确保更稳定的训练过程。
最后,对于给定的单个文本提示,我们分别使用原始扩散模型和在线训 练模型来生成图像潜变量^ z0 和 ^ z′ 0。然后计算对抗损失如下:
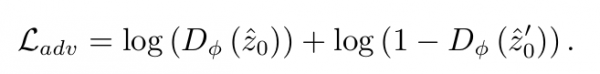
我们旨在微调在线模型以最小化此对抗损失,同时训练判别器以最大化该 损失。
在这里,我们结合了字幕模型损失(captioning model loss)、属性集中 损失(attribute concentration loss)和对抗损失(adversarial loss),为在线扩散模型构建了以下训练目标:
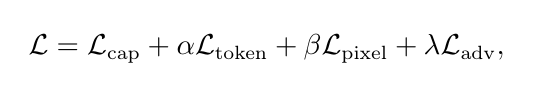
其中α、β和λ是用于平衡不同损失项的缩放因子。
实验与结果
在所有实验中,我们主要在SDXL[42]上实现我们的的方 法,这是最先进的开源文本生成图像模型。此外,我们还在StableDiffusion v1.5[42](SD1.5)上评估了我们的方法,以便在某些实验中进行更全面的 比较。对于字幕模型,我们选择了在COCO[31]图像字幕数据集上微调 的BLIP[25]。关于保真度保留中的鉴别器,我们直接采用SD1.5的预训练 UNet。
评估T2I-CompBench的结果
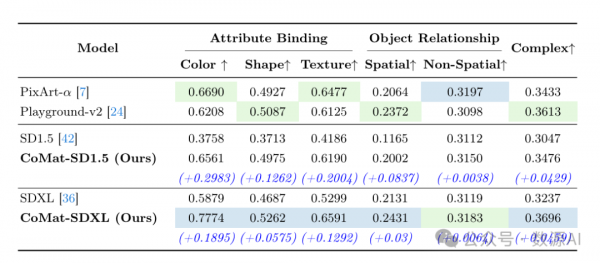
与最先进方法的定性比较



好文章,需要你的鼓励




2024
04/09
16:04
分享
点赞

