KIMI悄然开启收费模式!大模型to C商业化已成大势所趋
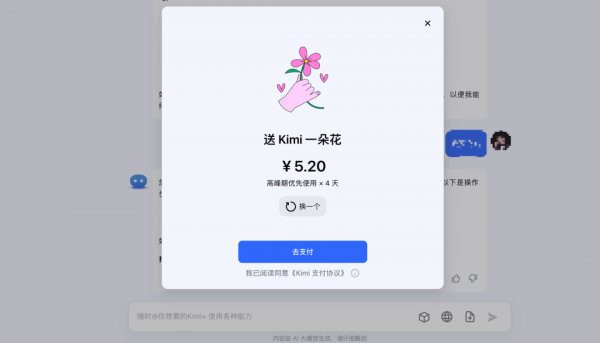
Kimi推出了“打赏”功能,用户可以通过支付进行“打赏”,金额从5.20元到399元不等,共6个档位,每个档位对应不同的高峰期优先使用时长。
随着大模型竞争日渐激烈,战场也从单纯的比拼技术,开始转向比拼商业化的能力。
近日,Kimi推出了“打赏”功能,用户可以通过支付进行“打赏”,金额从5.20元到399元不等,共6个档位,每个档位对应不同的高峰期优先使用时长。例如,支付5.20元,用户便可在可在高峰期优先使用4天,而支付399元则可优先使用365天,相当于Kimi的“包年会员”。
对此,业内专家指出,由于大模型训练成本高昂,走专业工具路线的大模型收费是大势所趋。例如OpenAI旗下的GPT-4于去年3月发布之初即宣布收费,用户需每月支付20美元费用,被设计师广为使用的Midjourney更是最高收费60美元/月,用户仍然络绎不绝。
去年11月,百度推出了满足专业人士需求的文心一言专业版。相比基础版,专业版搭载了性能更加强大的文心大模型4.0,在理解、生成、逻辑和记忆四大能力上有显著提升。用户可根据自身情况选择,日常需求可使用免费的基础版,工作需求则可体验专业版,满足自身在更高专业层次的要求。
与其他会员制产品不同,Kimi的付费模式更加灵活,允许用户根据需要选择使用天数,而无需按月或按年支付。不过,在权益方面,Kimi在付费后,相较于免费版,仅额外提供了“高峰期优先使用”的权益,回答速度与之前无异,也并未新增其他功能。例如,200万字长文本处理权限和AI绘画功能仍未开放。
通常而言,目前市面上的收费AI应用,往往会提供更高版本、更多Tokens、插件/生图功能等权益。
以文心一言为例,文心一言专业版相对基础版,明显更为智能和强大。文心一言专业版使用百度最新推出的文心大模型4.0版本,在理解、生成、逻辑和记忆能力上都有显著提升。
为了直观地体现文心4.0的聪明程度,李彦宏曾在百度世界2023上举了多个例子。比如,李彦宏问文心4.0,如果一位在北京工作的年轻人,想在河北购房,能不能在北京申请公积金贷款?它都可以对前后乱序的表述,比较模糊的表达意图,话语中的潜台词,进行相当准确的理解,并且给出答案。
“我觉得它能节省我的时间和精力,让我腾出手来做更专业的工作,所以我愿意付费,”一位已经购买文心一言专业版会员的程序员表示。
其次,文心一言专业版有了多项新突破,变得更专业。在图片生成方面,文心一言专业版支持更高分辨率、更优画图效果和多风格图片生成等功能;插件权益方面,它可以在网页端使用依言优答、一镜流影等高阶插件。
业内专家透露,大模型成本主要受三个因素影响。一是网络结构和参数规模,参数规模越大,计算成本越高。文心4.0采用万卡集群训练,计算成本自然更高;二是推理部署,比如模型量化压缩、推理计算策略、服务调度策略等;三是芯片和集群,所用芯片型号、规模以及集群架构等。
“这些资源的成本是巨大的,需要由提供模型的公司或组织承担。如果不收费,这些成本根本无法覆盖。”上述专家表示,付费是国际主流趋势,大模型要健康正向、长远发展,为用户持续提供优质服务,就必须解决长期可持续问题。
为了应对大模型使用成本的挑战,科技巨头与研究机构正积极探索新的解决方案。例如,通过改进算法来提升计算效率,或通过开发更高效的硬件来降低能耗。同时,利用云计算资源进行分布式训练和部署,也成为降低成本的一种有效途径。
然而,尽管技术的进步可能在一定程度上缓解成本压力,但完全免除付费模式仍然不现实。长期来看,付费模式不仅能够保障技术公司的可持续发展,还能推动整个行业的创新和进步,为用户提供更加先进和高效的人工智能服务。因此,用户和企业需要逐步接受并适应这一趋势,共同推动大模型技术的良性发展。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
Anthropic发布SCONE-bench智能合约漏洞利用基准测试,评估AI代理发现和利用区块链智能合约缺陷的能力。研究显示Claude Opus 4.5等模型可从漏洞中获得460万美元收益。测试2849个合约仅需3476美元成本,发现两个零日漏洞并创造3694美元利润。研究表明AI代理利用安全漏洞的能力快速提升,每1.3个月翻倍增长,强调需要主动采用AI防御技术应对AI攻击威胁。
NVIDIA联合多所高校开发的SpaceTools系统通过双重交互强化学习方法,让AI学会协调使用多种视觉工具进行复杂空间推理。该系统在空间理解基准测试中达到最先进性能,并在真实机器人操作中实现86%成功率,代表了AI从单一功能向工具协调专家的重要转变,为未来更智能实用的AI助手奠定基础。
Spotify年度总结功能回归,在去年AI播客功能遭遇批评后,今年重新专注于用户数据深度分析。新版本引入近十项新功能,包括首个实时多人互动体验"Wrapped Party",最多可邀请9位好友比较听歌数据。此外还新增热门歌曲播放次数显示、互动歌曲测验、听歌年龄分析和听歌俱乐部等功能,让年度总结更具互动性和个性化体验。
这项研究解决了现代智能机器人面临的"行动不稳定"问题,开发出名为TACO的决策优化系统。该系统让机器人在执行任务前生成多个候选方案,然后通过伪计数估计器选择最可靠的行动,就像为机器人配备智能顾问。实验显示,真实环境中机器人成功率平均提升16%,且系统可即插即用无需重新训练,为机器人智能化发展提供了新思路。