
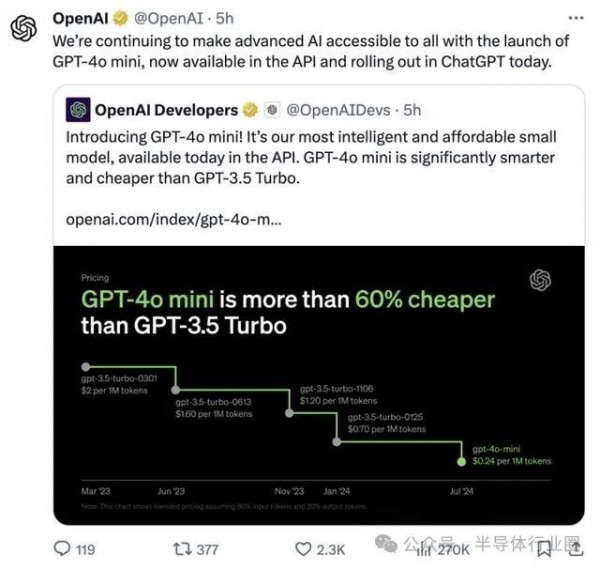
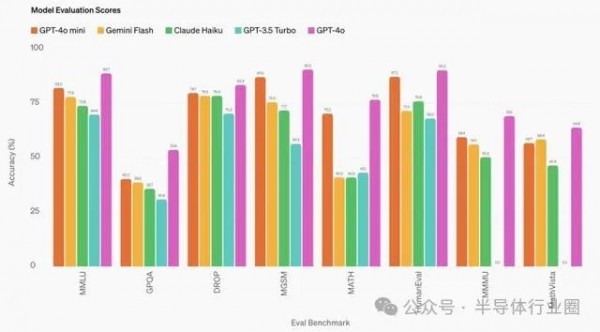
成本大降, OpenAI小型模型GPT-4o mini
GPT-4o mini输入价格为15美分/百万Tokens,输出价格为60美分/百万Tokens。而曾被视为OpenAI内部最轻量级且高性价比的GPT-3.5 Turbo,其输入价格为50美分/百万Tokens,输出价格为150美分/百万Tokens。

来源:半导体行业圈
好文章,需要你的鼓励


全球数据中心电力需求暴涨,超越电网建设速度
国际能源署发布的2025年世界能源展望报告显示,全球AI竞赛推动创纪录的石油、天然气、煤炭和核能消耗,加剧地缘政治紧张局势和气候危机。数据中心用电量预计到2035年将增长三倍,全球数据中心投资预计2025年达5800亿美元,超过全球石油供应投资的5400亿美元。报告呼吁采取新方法实现2050年净零排放目标。

维吉尼亚理工学院破解单细胞生物学新密码:当大语言模型遇见细胞世界的奇妙变革
维吉尼亚理工学院研究团队对58个大语言模型在单细胞生物学领域的应用进行了全面调查,将模型分为基础、文本桥接、空间多模态、表观遗传和智能代理五大类,涵盖细胞注释、轨迹预测、药物反应等八项核心任务。研究基于40多个公开数据集,建立了包含生物学理解、可解释性等十个维度的评估体系,为这个快速发展的交叉领域提供了首个系统性分析框架。

AMD双轮驱动:路线图与资金互促,收入持续提升
AMD首席执行官苏姿丰在纽约金融分析师日活动中表示,公司已准备好迎接AI浪潮并获得传统企业计算市场更多份额。AMD预计未来3-5年数据中心AI收入复合年增长率将超过80%,服务器CPU收入份额超过50%。公司2025年预期收入约340亿美元,其中数据中心业务160亿美元。MI400系列GPU采用2纳米工艺,Helios机架系统将提供强劲算力支持。

西湖大学团队突破:AI推理模型内存消耗降低50%的秘密武器
西湖大学王欢教授团队联合国际研究机构,针对AI推理模型内存消耗过大的问题,开发了RLKV技术框架。该技术通过强化学习识别推理模型中的关键"推理头",实现20-50%的内存缩减同时保持推理性能。研究发现推理头与检索头功能不同,前者负责维持逻辑连贯性。实验验证了技术在多个数学推理和编程任务中的有效性,为推理模型的大规模应用提供了现实可行的解决方案。

