
o1 模型在“医学领域”表现如何?研究人员进行了初步研究:AI 医生离我们更近了
OpenAI的o1模型,作为首个采用强化学习策略内化思维链(chain-of-thought)技术的LLM,已经在各种通用语言任务上展现出超凡的能力。
然而,它在医学等专业领域的性能仍然是一个未知数。为了探索这一问题,研究人员进行了一项初步研究,以评估o1在不同医学场景下的表现。

研究聚焦于o1模型在医学领域的三个关键方面:理解力、推理能力和多语言能力。为了确保评估的全面性,研究者们收集了35个现有的医学数据集,并开发了2个基于《新英格兰医学杂志》和《柳叶刀》的专业医学测验的新问答数据集,这些数据集被用于6个不同的任务中。
在理解力方面,评估包括概念识别和文本摘要任务。推理能力的测试更为复杂,它包括知识问答、临床决策支持和代理任务。多语言能力的评估则检查模型处理非英语医学问题的能力。这包括使用多种语言的问答任务,以及在中文医疗代理任务中模拟医疗互动。

为了衡量模型在这些任务上的表现,研究者们采用了多种评估指标。准确率直接衡量模型生成的答案与真实答案匹配的程度。F1分数则用于评估模型在需要选择多个正确答案的任务上的性能。BLEU和ROUGE指标用于评估生成文本与参考文本之间的相似度。AlignScore和Mauve指标则用于评估模型生成文本的事实一致性和自然度。
在实施评估时,研究者们探索了三种提示策略:直接提示、思维链提示和少量示例提示。他们选择了几种不同的模型进行比较,包括GPT-3.5、GPT-4以及开源模型MEDITRON-70B和Llama3-8B。实验涉及到多个医学任务,如问答、文本摘要、概念识别等,并使用了相应的数据集来评估模型在每个任务上的表现。

实验结果显示,o1模型在多数医学任务上都展现出了优越的性能。
在理解医学概念方面,o1在多个概念识别数据集上的表现超过了其他模型,在BC4Chem数据集上,o1的平均性能提升达到了24.5%。
在推理能力方面,o1在新构建的NEJMQA和LancetQA问答任务上取得了显著的准确率提升,o1的平均准确率分别比GPT-4高出8.9%和27.1%。
此外,o1在多语言医学问答任务中也展现了强大的能力,但在复杂的中文医疗代理任务中,其性能却有所下降。
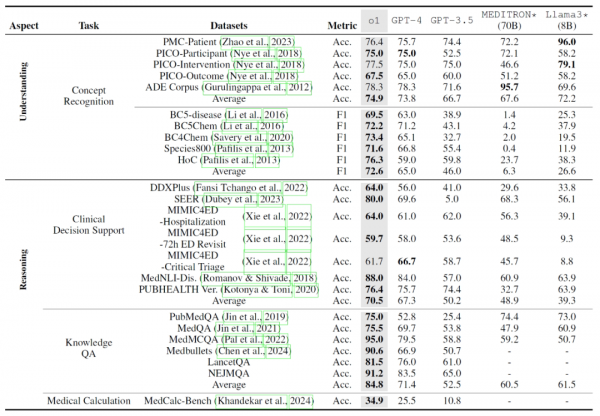
研究人员也发现了一些局限性。o1在多个医学任务上表现出色,但其较长的解码时间可能导致在需要快速响应的临床环境中的实用性受限。此外,模型在处理复杂的中文医疗代理任务时性能有所下降,在处理复杂的多语言医学案例时仍面临挑战。
研究人员还发现,传统的评估指标如BLEU和ROUGE,无法充分捕捉到模型在医学领域的表现,需要开发更加精确的评估工具,以便更好地衡量和理解模型在复杂医学任务中的表现。
研究人员认为,尽管o1在某些方面仍有不足,但其在多个医学任务上展现出的能力表明,我们离实现AI医生的目标已经越来越近。然而,为了实现这一目标,还需要在模型性能、评估指标和用户指导策略等方面进行更多的研究和改进。
好文章,需要你的鼓励


西班牙病毒如何将谷歌带到马拉加
33年后,贝尔纳多·金特罗决定寻找改变他人生的那个人——创造马拉加病毒的匿名程序员。这个相对无害的病毒激发了金特罗对网络安全的热情,促使他创立了VirusTotal公司,该公司于2012年被谷歌收购。这次收购将谷歌的欧洲网络安全中心带到了马拉加,使这座西班牙城市转变为科技中心。通过深入研究病毒代码和媒体寻人,金特罗最终发现病毒创造者是已故的安东尼奥·恩里克·阿斯托尔加。

让AI记住房间每个角落:悉尼大学团队如何让视频生成拥有“空间记忆“
悉尼大学和微软研究院联合团队开发出名为Spatia的创新视频生成系统,通过维护3D点云"空间记忆"解决了AI视频生成中的长期一致性难题。该系统采用动静分离机制,将静态场景保存为持久记忆,同时生成动态内容,支持精确相机控制和交互式3D编辑,在多项基准测试中表现优异。

LangChain核心库曝出严重漏洞,AI智能体机密信息面临泄露风险
人工智能安全公司Cyata发现LangChain核心库存在严重漏洞"LangGrinch",CVE编号为2025-68664,CVSS评分达9.3分。该漏洞可导致攻击者窃取敏感机密信息,甚至可能升级为远程代码执行。LangChain核心库下载量约8.47亿次,是AI智能体生态系统的基础组件。漏洞源于序列化和反序列化注入问题,可通过提示注入触发。目前补丁已发布,建议立即更新至1.2.5或0.3.81版本。

马里兰大学突破性发现:AI推理过程终于有了“身体检查“——ThinkARM框架揭开大型语言模型思维奥秘
马里兰大学研究团队开发ThinkARM框架,首次系统分析AI推理过程。通过将思维分解为八种模式,发现AI存在三阶段推理节律,推理型与传统AI思维模式差异显著。研究揭示探索模式与正确性关联,不同效率优化方法对思维结构影响各异。这为AI系统诊断、改进提供新工具。
2024
09/26
21:04
分享
点赞

