Anthropic发布全新的Haiku 3.5和升级版Sonnet 3.5,大模型控制电脑使用能力强了很多!
本文原文来自DataLearnerAI官方网站:
https://www.datalearner.com/blog/1051730035281379
2024年10月22日,Anthropic发布了两个新模型:升级版的Claude 3.5 Sonnet和全新的Claude 3.5 Haiku。升级版的Claude 3.5 Sonnet在保持原有价格和速度的基础上,实现了全面性能提升,尤其在编码领域取得了显著进步。新推出的Claude 3.5 Haiku则以与Claude 3 Haiku相同的成本和类似的速度,在多个评测中达到了与Claude 3 Opus相当的性能水平。
此次发布最引人注目的是Claude 3.5 Sonnet引入了一项突破性的新功能:计算机使用能力(Computer Use)。这项目前处于公测阶段的功能,使Claude能够像人类一样通过观看屏幕、移动光标、点击按钮和输入文本来操作计算机。

- 升级版Claude 3.5 Sonnet的主要特点
- Claude 3.5 Sonnet的突破性功能:计算机使用能力
- 工作原理与技术实现
- Claude 3.5 Haiku的主要特点
- 评测结果分析
- 软件工程与代理任务评测
- 视觉能力评测
- 总结
升级版Claude 3.5 Sonnet的主要特点
在2024年6月份,Claude发布了Claude Sonnet 3.5模型,该模型相比上一代模型提升明显。Claude模型分为三个版本,最强的是Opus,其次是Sonnet,最小但是最快的是Haiku模型。Sonnet 3.5模型甚至超过了此前的Claude Opus 3模型(即上一代Claude最强的模型)。而四个月后,Sonnet 3.5版本不变,Anthropic给它做了一个升级,目前大家一般称该版本模型为Claude Sonnet 3.5 New。
升级版Claude 3.5 Sonnet带来了以下关键改进:
- 计算机使用能力:首次在公测版中提供此功能,能够执行需要数十甚至数百个步骤才能完成的任务。
- 软件工程能力显著提升:在代码编写和工具使用方面取得重大突破。
- 视觉处理能力增强:在多个关键多模态评估中达到了最新水平。
在计算机使用能力方面,Claude 3.5 Sonnet New在OSWorld基准测试中取得了14.9%的成绩(仅使用截图输入),明显优于其他AI系统的7.8%。当允许更多操作步骤时,其成绩可提升至22.0%。
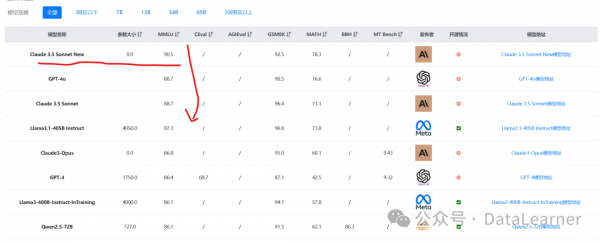
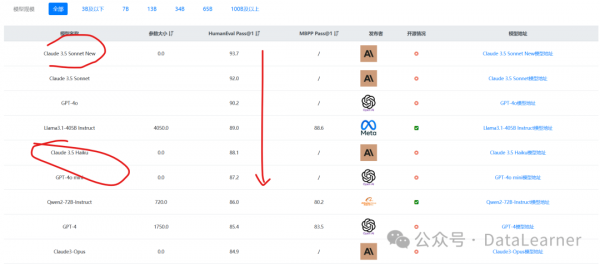
Claude Sonnet 3.5 New版本各个评测都是非常好,目前在常规的文本理解(MMLU)和编程水平(HumanEval)评测上都是全球第一,超过了GPT-4o模型。
DataLearnerAI官方评测排行榜收集的结果如下:
Claude 3.5 Sonnet的突破性功能:计算机使用能力
计算机使用能力(Computer Use)是Claude 3.5 Sonnet这次升级中最具突破性的新功能。这项创新使Claude能够像人类一样通过观察屏幕、移动光标、点击按钮和输入文本来操作计算机,而不是仅依赖特定的API或工具。这种方法标志着AI与计算机交互方式的重要转变,使模型能够使用为人类设计的标准工具和软件程序。
工作原理与技术实现
Anthropic为实现这一功能开发了专门的API,使Claude能够感知和交互计算机界面。其工作流程如下:
- 感知界面:通过截图方式获取计算机界面信息
- 理解任务:将用户的自然语言指令转换为具体的计算机操作序列
- 执行操作:通过移动光标、点击、输入文本等方式与界面交互
- 验证结果:观察操作结果并根据需要调整后续动作
例如,当用户要求”使用我的计算机和在线数据填写这个表单”时,Claude可以:
- 查看电子表格
- 移动光标打开网络浏览器
- 导航到相关网页
- 从这些页面收集数据
- 将数据填入表单
尽管这项功能具有突破性意义,但目前仍处于早期阶段,存在一些限制:
基础操作挑战:
- 滚动操作
- 拖拽功能
- 缩放操作
- 复杂的多步骤任务
这项功能的使用建议如下:
- 建议从低风险任务开始探索
- 重要操作需要人工监督
- 复杂任务建议分解为更小的步骤
- 为关键操作设置验证机制
尽管目前还处在早期阶段,但是这个功能的进化速度是可以预见的会很快!
Claude 3.5 Haiku的主要特点
Claude 3.5 Haiku作为Anthropic最快速模型的下一代产品,具有以下特点:
- 性能显著提升:在保持相同成本和速度的情况下,各项技能都有所提高。
- 强大的编码能力:在多个编码任务评测中表现优异。
- 低延迟和改进的指令执行能力:特别适合面向用户的产品和专门的子代理任务。
评测结果分析
软件工程与代理任务评测
SWE-bench Verified评测
这是一个评估模型解决实际软件工程任务能力的基准测试,通过解决来自流行开源Python存储库的GitHub问题来进行评估。
| 模型 | 通过率 |
|---|---|
| Claude 3.5 Sonnet (New) | 49.0% |
| Claude 3.5 Haiku | 40.6% |
| Claude 3.5 Sonnet | 33.4% |
| Claude 3 Opus | 22.2% |
| Claude 3 Haiku | 7.2% |
数据显示,升级版Claude 3.5 Sonnet在代码开发能力上有了显著提升,通过率提高了近16个百分点。而新的Claude 3.5 Haiku也展现出强劲实力,其40.6%的通过率超过了原版Claude 3.5 Sonnet。
TAU-bench评测结果
TAU-bench评估模型在零售和航空领域的客户服务场景中与模拟用户和API交互的能力。
| 模型 | 零售领域 | 航空领域 |
|---|---|---|
| Claude 3.5 Sonnet (New) | 69.2% | 46.0% |
| Claude 3.5 Haiku | 51.0% | 22.8% |
| Claude 3.5 Sonnet | 62.6% | 36.0% |
| Claude 3 Opus | 45.1% | 34.5% |
| Claude 3 Haiku | 18.2% | 16.0% |
在这个评测中,升级版Claude 3.5 Sonnet在两个领域都取得了明显进步,特别是在较为复杂的航空领域提升了10个百分点。Claude 3.5 Haiku也展现出不俗实力,在零售领域的表现超过了Claude 3 Opus。
视觉能力评测
升级版Claude 3.5 Sonnet在多个视觉相关任务中都展现出强大实力:
| 评测项目 | Claude 3.5 Sonnet (New) | Claude 3.5 Sonnet | Claude 3 Opus | GPT-4o | Gemini 1.5 Pro |
|---|---|---|---|---|---|
| MMMU (validation) | 70.4% | 68.3% | 59.4% | 69.1% | 65.9% |
| MathVista | 70.7% | 67.7% | 50.5% | 63.8% | 68.1% |
| AI2D | 95.3% | 94.7% | 88.1% | 94.2% | - |
| ChartQA | 90.8% | 90.8% | 80.8% | 85.7% | - |
| DocVQA | 94.2% | 95.2% | 89.3% | 92.8% | - |
在视觉理解任务中,升级版Claude 3.5 Sonnet在大多数测试中都达到了最优水平,特别是在科学图表理解(AI2D)和图表问答(ChartQA)方面的表现尤为突出。相比其前代版本,新版本在数学视觉推理(MathVista)等领域都有明显提升。
总结
通过这些评测结果可以看出,Anthropic在这次更新中不仅提升了模型的整体性能,还在专业领域如编程、视觉理解等方面取得了显著进步。特别是新增的计算机使用能力,虽然仍处于早期阶段,但展现出了AI与计算机交互的新可能性。
目前,Claude官网的聊天应用(Claude Chat)已经可以使用Sonnet 3.5 New模型了。而Haiku 3.5目前则是面向开发者开放。
话说,Sonnet 3.5都这么强了,Opus 3.5得变成什么样了!
这两个模型更多的信息参考DataLearnerAI模型信息卡地址:
Claude Haiku 3.5模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/claude-3_5-haiku
Claude Sonnet 3.5 New模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/claude-3_5-sonnet-new
好文章,需要你的鼓励

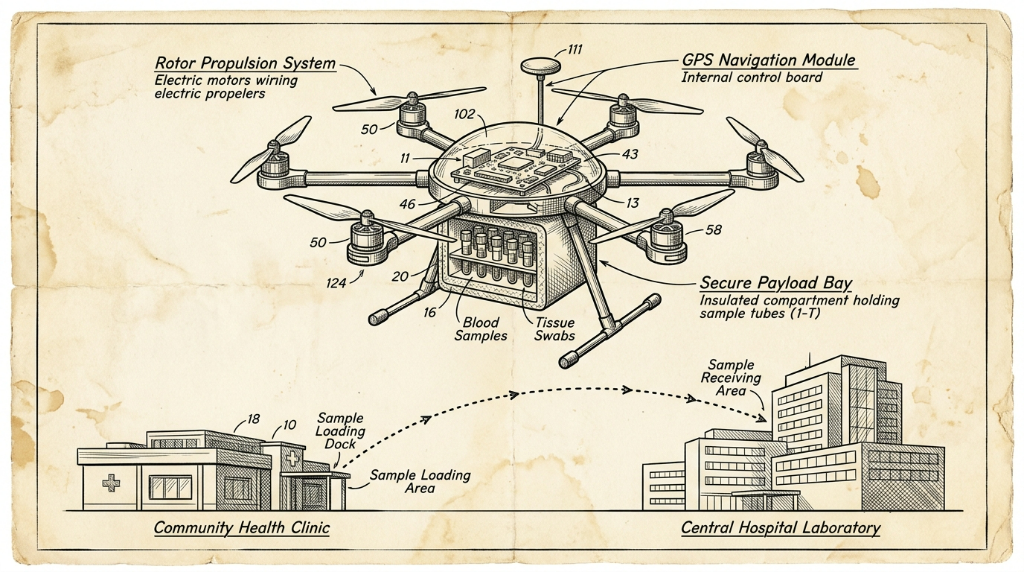
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2024
10/29
11:04
分享
点赞