
数据中心运营中的节能降碳措施综述与应用

1、数据中心能耗情况分析
图1 数据中心能耗分布柱状图
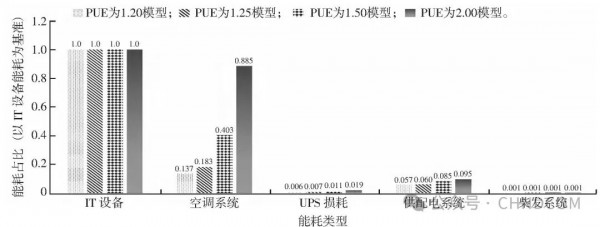
注:PUE为电源使用效率,UPS为不间断电源。

1)在数据中心建设初期一定要遵照相关法律法规政策,如《高耗能落后机电设备(产品)淘汰目录》,确保未选用落后淘汰设备。
2)在满足工艺要求的情况下,数据中心应选用性能稳定、操作可靠、维修简单、能耗低的新技术和先进设备。
3)在总图布置及机房楼、变电站等关键设施的布置上,需确保紧凑合理,减少线路和变压器的损耗。
5)注意密封机机架内部的空隙、机架与机架之间的空隙、机架底部的空隙,以防热风灌入。
1)根据工程的总图布置规划,合理配置配电室以减小电缆长度,同时,优化配电线路,降低供电系统线损,提高平均负荷与最大负荷之比,选用低耗能、高功率的电气设备,减少配电环节电能消耗。
2)选用新型、节能的各类产品。车间供电应将线路长度降到最小,将电力损失降到最低;增加动力,减少无功损失。
3)产品选用高效节能的绿色环保型照明灯具,该灯具可自动开闭照明器,利用智能声光控制技术减少电力损失。根据各场所使用功能的不同,采用与之相符的光源和灯具。
1)机房楼管道和所有热力设备的保温均采用轻质高效保温外墙和屋面隔热材料等新型保温材料,以减弱热传导效应。
3)建筑充分考虑自然采光与通风,应尽量减少人工照明与机械通风。冬季最大限度地利用自然热进行加热,发热更多,减少损耗;夏季最大限度地利用天然能量降温,节约能源,降低消耗。
4)根据GB/T7107—2002《建筑外窗气密性能分级及检测方法》,建筑物外窗气密性能分级不应低于6级,采用传热性和遮阳性符合要求的塑钢窗、中空玻璃等。

1)由于数据中心大多数选址于工业开发区或偏远僻静的地方,距离人员聚集的城市或建筑设施较远,余热的供出无法满足城镇用热需求,仅为数据中心内部的运维楼、办公楼、生活楼等区域供暖,周边单位未实现有效供应。
2)关于数据中心余热的回收与利用,中国并没有出台相关标准和政策,国内也没有指导性的依据来支持数据中心开展余热回收项目。
3)国内数据中心余热回收能量利用存在效率相对较低、热交换效率不高、管线损耗高等问题,且中国目前设备制造能力和余热工艺方案的技术先进性与国外数据中心有着较大的差距。
4)考虑到目前的经济形势,数据中心余热回收利用项目的落地对于企业来说是一笔不小的投资,并且由于回收效果差、用热单元稀少等,项目投资回收期较长。

3、结束语
作者:穆建军
参考文献:
[1]石云鹏.“双碳”背景下数据中心能耗现状与节能技术研究[J].中国新通信,2022,24(8):119-121.
[2]张忠斌,邵小桐,宋平,等.数据中心能效影响因素及评价指标[J].暖通空调,2022,52(3):148-156.
[3]杨春梅,黎晓彬,杨昉,等.基于咨询案例的数据中心绿色发展研究[J].节能,2023,42(7):66-68.
[4]李德明,朴春爱,陈磊.大型数据中心制冷系统设计探讨[J].信息工程,2017(9):30.
[5]马妍,刘小林.以零碳数据中心为生产力提质增新[J].中国电信业,2024(3):24-28.
-END-
未经授权,禁止转载。公众号:数据中心基础设施运营管理
【版权声明】
凡本公众平台注明来源或转自的文章,版权归原作者及原出处所有,仅供大家学习参考之用,若来源标注错误或侵犯到您的权利,烦请告知,我们将立即删除。
【免责声明】
本公众平台对转载、分享的内容、陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完善性提供任何明示或暗示的保证,仅供读者参考。
好文章,需要你的鼓励



牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。

美国多源电子患者数据采集方法研究综述
随着医疗数据数字化与互操作性的进步,跨机构纵向患者数据的研究应用成为可能。本研究通过对20位领域专家的访谈,识别出8种数据收集方法,涵盖智能手机应用、结构化数据导出、区域/全国研究查询及聚合数据源等。研究发现,各方法均有其优缺点,无单一最优方案。参与者中介交换方式可绕过复杂治理安排,但存在数据缺口;全国性网络尚不支持研究查询。公共政策的持续推进将对该领域发展起关键作用。

奖励模型的“选择困难症“:卡内基梅隆大学与Meta联手发现AI训练中被忽视的隐患
研究发现主流奖励模型对同等质量答案给出差异悬殊的分数,并提出"奖励聚类"算法通过蒙特卡洛随机失活将连续分数离散化,在不重训模型的前提下有效减少AI训练中的奖励作弊现象。
2024
10/31
13:04
分享
点赞

