
基于Gemini!Waymo提出端到端自动驾驶多模态模型EMMA!
数源AI 最新论文解读系列

论文名:EMMA: End-to-End Multimodal Modelfor Autonomous Driving
论文链接:https://arxiv.org/pdf/2410.23262.pdf

引言
近年来,自动驾驶技术取得了显著进展。为了使自动驾驶车辆成为无处不在的交通形式,它们必须导航越来越复杂的现实世界场景,这些场景需要理解丰富的场景上下文以及复杂的推理和决策。端到端自动驾驶系统最近作为潜在解决方案出现,直接从传感器数据中学习生成驾驶动作。这种方法消除了模块之间需要符号接口的需求,并允许从原始传感器输入中联合优化驾驶目标。然而,这些系统通常是为特定驾驶任务专门设计的,并在有限的训练数据集上训练,阻碍了它们泛化到罕见或新颖场景的能力。多模态大型语言模型(MLLMs)为自动驾驶中的AI提供了一个有前景的新范式,可能有助于解决这些挑战。
简介
我们介绍了EMMA,一个端到端的自动驾驶多模态模型。基于多模态大型语言模型的基础,EMMA直接将原始相机传感器数据映射到各种特定于驾驶的输出中,包括规划器轨迹、感知对象和道路图元素。EMMA通过将所有非传感器输入(例如导航指令和自我车辆状态)和输出(例如轨迹和3D位置)表示为自然语言文本,最大化了预训练大型语言模型的世界知识效用。这种方法允许EMMA在统一的语言空间中联合处理各种驾驶任务,并使用特定于任务的提示生成每个任务的输出。实证上,我们通过实现在nuScenes上的运动规划达到最先进性能以及在Waymo开放运动数据集(WOMD)上的竞争性结果来证明EMMA的有效性。EMMA还在Waymo开放数据集(WOD)上的相机主导的3D物体检测上取得了有竞争力的结果。我们展示了与规划器轨迹、物体检测和道路图任务共同训练EMMA在所有三个领域都产生了改进,突出了EMMA作为自动驾驶应用通用模型的潜力。然而,EMMA也存在一些局限性:它只能处理少量的图像帧,没有集成像激光雷达或雷达这样的精确3D感测方式,而且在计算上也很昂贵。我们希望我们的结果能够激发进一步的研究,以减轻这些问题,并推动自动驾驶模型架构的进一步发展。
方法与模型
EMMA建立在Gemini之上,这是一个由谷歌开发的MLLM家族。我们利用自回归的Gemini模型,这些模型经过训练以处理交织的文本和视觉输入,以产生文本输出。
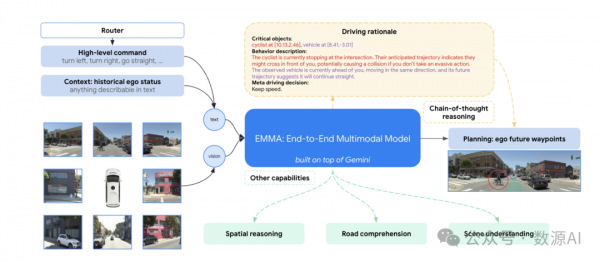
我们将自动驾驶任务映射到基于Gemini的EMMA公式中。所有传感器数据都表示为缝纫图像或视频作为V;所有路由器命令、驾驶上下文和特定任务的提示都表示为T;所有输出任务都呈现为语言输出O。一个挑战是许多输入和输出需要捕获3D世界坐标,例如运动规划中的航点BEV(鸟瞰视图)位置(x, y)以及3D盒子的位置和大小。我们选择文本表示,以便所有任务都能共享相同的统一语言表示空间,并且它们可以最大限度地重用预训练权重中的知识,即使文本呈现可能产生的标记数超过专门的标记化。
1、端到端运动规划
EMMA采用统一的、端到端的训练模型,直接从传感器数据生成自动驾驶车辆的未来轨迹。然后,这些生成的轨迹被转换为特定于车辆的控制动作,如加速和转向,用于自动驾驶车辆。EMMA的端到端方法旨在模拟人类驾驶行为,重点关注两个关键方面:(1)首先,使用导航系统(例如谷歌地图)进行路线规划和意图确定;(2)其次,利用过去的行为来确保在时间上平稳一致的驾驶。
我们的模型包含三个关键输入,以与这些人类驾驶行为保持一致:
(1)周围视图摄像头视频(V):提供全面的环境信息。
(2)高级意图命令(Tintent):源自路由器,包括指令如“直行”、“左转”、“右转”等。
(3)历史自我状态集(Tego):以鸟瞰视角(BEV)空间的一组航点坐标表示,Tego = {(xt, yt)}–Tht=–1 对于Th时间戳。所有航点坐标都以纯文本形式表示,不使用专门的标记。这也可以扩展以包括更高阶的自我状态,如速度和加速度。
模型生成未来轨迹,用于运动规划,表示为同一BEV空间中本车未来的轨迹航点集合,其中所有输出航点也以纯文本形式表示。
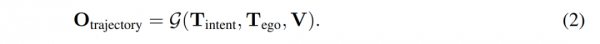
2、使用链式思维推理进行规划
链式思维提示[Wei等人,2022]是MLLM中的一个强大工具,它增强了推理能力并提高了可解释性。在EMMA中,我们通过要求模型在预测最终的未来轨迹航点Otrajectory的同时,阐述其决策理由Orationale,将链式思维推理整合到端到端规划器轨迹生成中。
我们按层次结构构建驾驶理由,从粗粒度信息到细粒度信息分为四种类型:
(1)场景描述广泛描述了驾驶场景,包括天气、一天中的时间、交通情况和道路状况。
(2)关键对象是可能影响本车驾驶行为的在路上实体,我们需要模型识别它们的精确3D/BEV坐标。
(3)关键对象的行为描述描述了被识别关键对象的当前状态和意图。
(4)元驾驶决策包括12个高级驾驶决策类别,总结了根据先前观察给出的驾驶计划。
3、EMMA Generalist
虽然端到端运动规划是最终的核心任务,但一个全面的自动驾驶系统需要额外的能力。具体来说,它必须感知三维世界并识别周围的物体、道路图和交通状况。为了实现这一目标,我们将EMMA构建为一个能够通过训练混合体处理多个驾驶任务的Generalist模型。
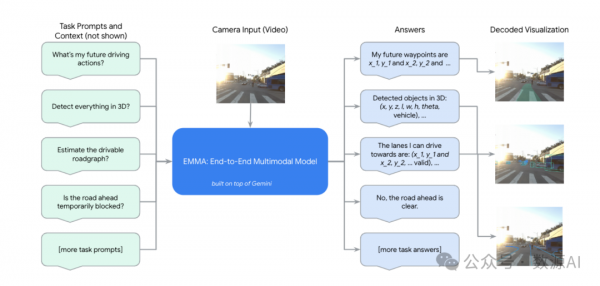
我们的视觉语言框架将所有非传感器输入和输出表示为纯文本,提供了必要的灵活性,以纳入许多其他驾驶任务。我们采用指令微调这一在大型语言模型(LLMs)中广泛采用的成熟方法,共同训练所有任务,并结合输入方程式1中的特定任务提示。我们将这些任务组织成三个主要类别:空间推理、道路图估计和场景理解。
4、Generalist Training
我们的统一视觉-语言公式使得多个任务能够与单一模型同时训练,在推理时通过任务提示Ttask的简单变化进行特定任务的预测。训练过程既直接又灵活。
对于每个任务,我们构建一个包含|Dtask|个训练样本的数据集Dtask。在每次训练迭代中,我们从可用的数据集中随机抽取一批样本,选择特定数据集的样本概率与数据集大小成正比:即|Dtask|/t |Dt|。
实验与结果
实验细节
我们强调了用于验证EMMA模型有效性的实验。我们利用了Gemini团队Google发布的Gemini 1.0 Nano-1的最小尺寸,即所有实验都是使用Gemini 1.0 Nano-1进行的。我们首先在两个公共数据集上端到端规划器轨迹生成的结果。接下来,我们在内部数据集上进行额外的实验,研究思维链和数据规模对性能的影响。
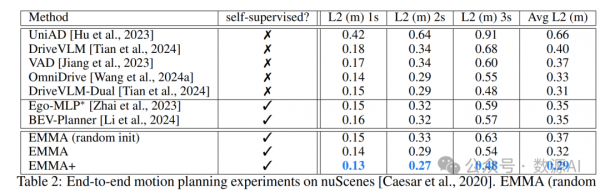
定量实验结果

可视化结果


好文章,需要你的鼓励

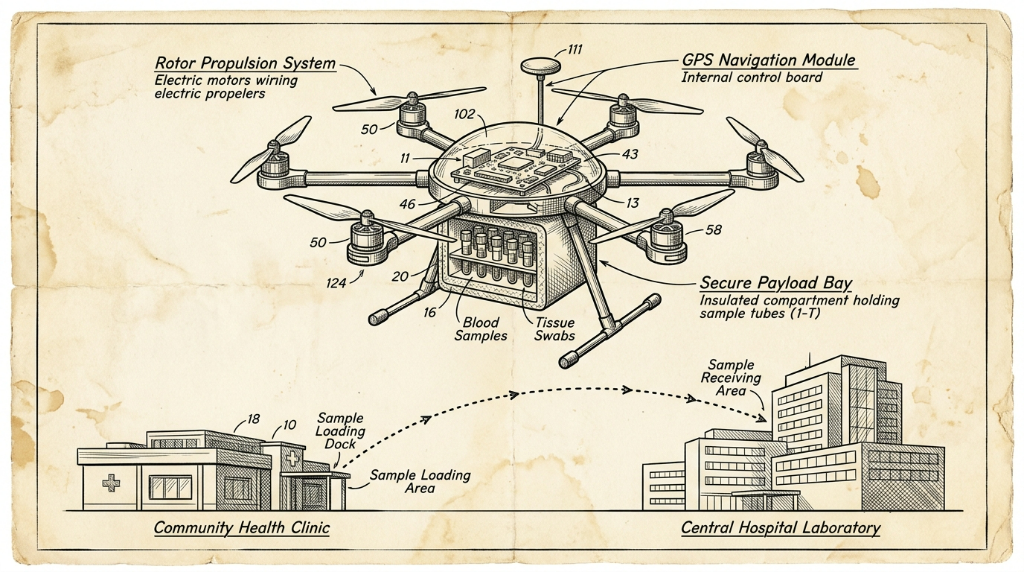
英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2024
11/04
11:05
分享
点赞

