
智谱AI上线4K60帧"新清影",还要直接开源,我觉得他们疯了。
就在刚刚,智谱宣布全新迭代的AI视频模型“新清影”,正式上线。
10s、4k、60帧,还能自带生成挺匹配的AI音效。
视频模型已经上线智谱清言上,人人可用。音效模型这个月也即将上线。
这个点,其实还好,就是线上模型迭代升级了一版而已。
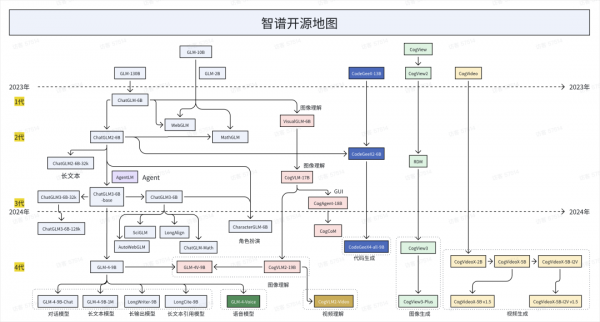
但是最牛逼的是,他们直接宣布,把这个“新清影”背后的底层模型,也就是CogVideoX v1.5,直接开源了。。。

我觉得他们疯了,真的。
上上周发类似GPT4o那种端到端的语音对话模型也是,直接发布即开源。
真的,智谱给我整不会了。
周二才夸过腾讯混元,开源了他们参数最大的MoE模型混元Large和AI 3D模型Hunyuan3D-1.0。
现在智谱直接接力,直接开源了他们内部效果最好的AI视频模型。
还是那句话,对于每一个愿意开源,让社会、让开源社区,百尺竿头更进一步的公司。我都永远报以最崇高的敬意,和最大的善意。
CogVideoX v1.5我也第一时间去测试了一下。
开源地址在此:https://github.com/thudm/cogvideo
普通用户也可以去智谱清影上玩。
我放一些我自己跑的case吧。
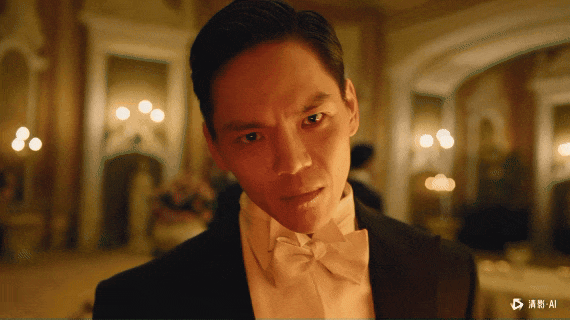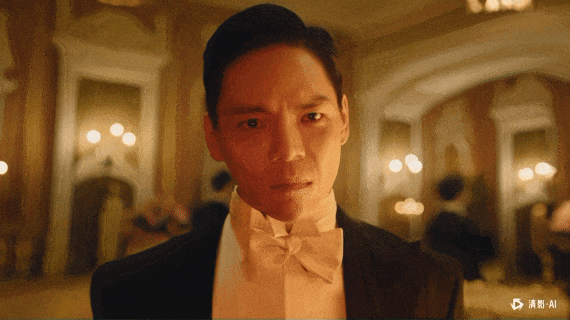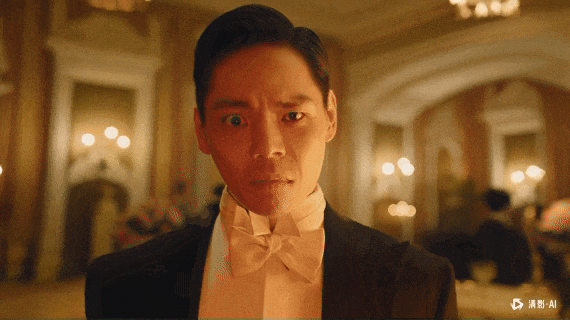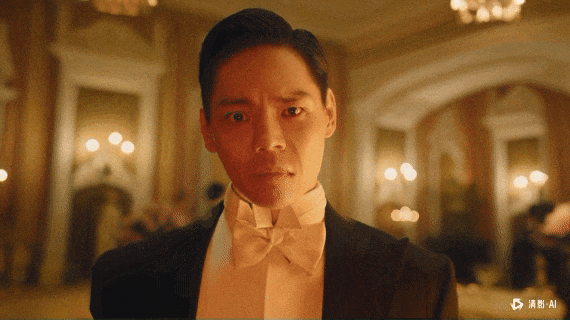


非常坦率的讲,智谱的新清影,跟上一代比,已经进步巨大了。
不管是审美、还是动作幅度、还是物理规律、还是稳定程度。
真的,上一代的人物变形变得我到现在都还记忆犹新。
但是如果你要把他跟业界最好的比,比如你跟豆包PixelDance比分镜比运镜,那肯定还是差了一定距离的。
毕竟这一版的新清影,在版本号上,还是一个折中的阶段,也就是CogVideoX v1.5,而且他们进步速度还是飞快的。
当时8月也是第一个把生视频全面公开让c端来玩的,说实话也勇气可嘉。
而且我问了一下内部人,参数量更大更新更强的模型正在训练,如果等过两个月CogVideoX v2.0阶段,可能又会来一波进化的飞跃。
当然,不管怎么样,智谱敢把新清影发布即开源,就凭这点,我赞智谱一声勇士。
上一次他们开源CogVideoX,直接给开源社区贡献了一波大力。
一群老外直接玩的飞起。
比如微调一个自己的视频模型。
比如微调一个室内设计的专属视频模型。
等等等等。
AI绘图的开源生态已经被玩出花了,但是AI视频的生态,确实还是非常的贫瘠,不管是配套插件,还是微调方式,还是模型数量等等,都还远远处于起步阶段。
希望这一波新清影CogVideoX v1.5的开源,能让AI视频的开源社区和生态,继续沸腾一次。
除了CogVideoX v1.5的开源之外,还有另一个东西我觉得非常值得说,虽然它还没有上线,但是在这次的demo里一窥了真容。
就是智谱的AI音效模型。
智谱可能是我知道的,唯一一个,什么模态都做的,关键,每个模特居然做的都还不错。
我真的,尊称一声模型法王。
给你们数一下。

好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。


南洋理工大学等机构联合发布:AI看懂艺术的“为什么“,距离人类还有多远?
MUSEBENCH是一个专门测试AI理解视听艺术创作意图的评测基准,涵盖电影、视觉艺术、舞台表演和游戏四类,发现最强AI得分仅48%,远低于人类专家87%。

