百度这张AI成绩单,透出了2025年AI行业三大机会点
百度发了一张2024年AI成绩单,涵盖百度在大模型、智能体、AI应用等领域的多项AI奖项。透过这份AI成绩单,我们或许能通过百度做AI的思路总结出一些布局AI的重点方向,找找明年做AI的机会。

过去一年,国内基础大模型持续迭代,应用落地高速发展,激烈的大模型竞赛中,只有不断深耕技术能力才能跑出来。以百度为例,文心大模型日均调用量超15亿,自去年12月首次披露以来增长30倍。这一快速增长的趋势,亦是国内乃至全球大模型发展的一个缩影。
近日,百度发了一张2024年AI成绩单,涵盖百度在大模型、智能体、AI应用等领域的多项AI奖项。透过这份AI成绩单,我们或许能通过百度做AI的思路总结出一些布局AI的重点方向,找找明年做AI的机会。
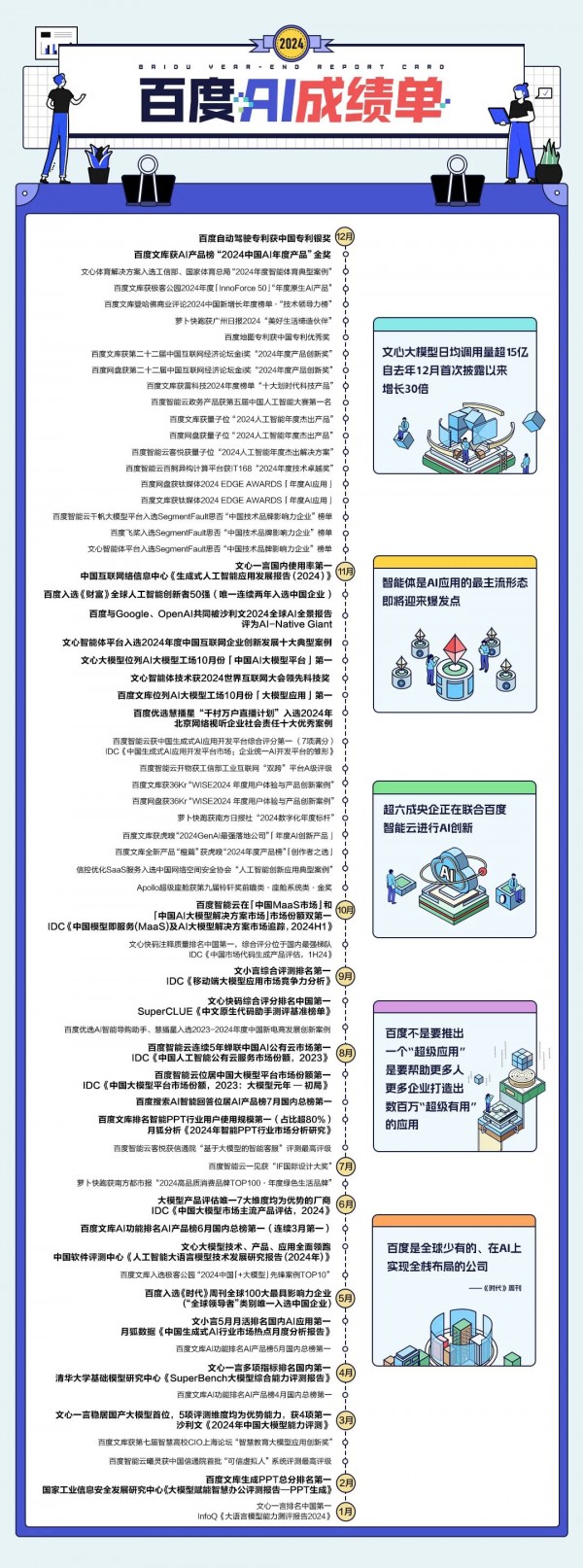
这第一大机会,便是智能体,将发展成为AI应用主流形态。
尽管大模型的技术进步令人瞩目,但其真正的产业价值仍需通过AI应用来得以实现。只有将大模型的强大能力深度融合于实际业务场景中,通过智能化改造与流程优化,才能有效释放千行百业的数据潜能、产生价值。
而智能体技术,便是连接产业与AI技术的关键纽带之一。
“智能体是我最看好的AI原生应用发展方向。”百度创始人李彦宏曾表示,智能体最明显的特点是门槛足够低,谁都能上手,天花板又足够高,可以做出非常复杂,非常强大的应用。
作为AI领域最为前沿的应用方向,智能体之所以会发展成为主流AI应用,在于它的门槛非常低,让人人都可触达AI红利。智能体不似其他技术一般被束之高阁,而是让更多没有代码基础能力的人,借助智能体的能力,可以做到会说大白话就能做出应用来。
在百度的文心智能体平台,普通人也能通过低代码甚至无代码的方式,加入到开发AI应用的队伍中来,只需要几句话,就能够打造自己的专属智能体,并实现从知识库集成到复杂任务处理的一站式服务,让专业知识借助智能体完成商业的转化。对普通人来说,这其实是一个不错的能赚到钱的“风口”。
今年以来,越来越多的科技企业正在将智能体作为重点关注的领域。12月11日,谷歌正式发布了其迄今最强大的AI模型,官方表示这是为专为智能体时代设计的大模型,为此谷歌也推出了三个新的AI智能体原型:通用大模型助手Project Astra、浏览器助手Project Mariner、编程助手Jules。
谷歌CEO桑达尔·皮查伊强调:Gemini 2.0的发布标志着谷歌在构建通用助手的愿景上迈出了重要一步。更加明确了智能体在人类通往AGI的关键意义。
除了百度和谷歌,微软、腾讯、字节跳动、科大讯飞等全球科技公司,也都在布局智能体相关的技术与应用。以百度为例,目前文心智能体平台已汇聚15万家企业和80万开发者,先一步实践的百度已为行业打样。11月,文心智能体平台入选2024年度中国互联网企业创新发展十大典型案例。
可以说,在AI这条赛道上,用一句“英雄所见略同”来形容对于智能体发展的希冀,并不为过。智能体应用的爆发,将是未来数以百万计AI应用的繁荣。
这一年,AI技术逐渐从“炫技”阶段过渡到以“实用性”为核心。衡量一个AI应用的价值只需看起来非常朴实的两个字——“有用”。
“超级有用”的应用之所以能成为行业的核心趋势,正是因为它能够切实解决问题,并为用户和行业带来显著的价值提升。正如李彦宏所言,AI时代,不是要推出一个“超级应用”,而是要打造出数百万的“超级有用”。
2025年将是AI技术全面融入产业的关键之年。伴随着智能体和无代码工具的进一步普及,让AI从专业领域走向更广泛的产业化应用成为可能,使“超级有用”的应用将成为行业发展的核心驱动力。
在百度世界2024上,百度发布了无代码工具“秒哒”, 进一步降低了AI开发的门槛。“秒哒”让普通用户也能参与AI应用的构建,将创意快速转化为应用。推出秒哒,是百度为助推AI应用爆发提供技术基础的一项“打地基”工程,让更多人、更多企业打造出数百万“超级有用”的AI应用。
这一年来,AI对于行业渗透的速度远超想象,千行百业中更是有无计其数的场景与五花八门的需求,它们都是亟待AI应用来解决实际问题。这也让“超级有用”的应用会先于“超级应用”一步出现。2025年不一定会出现月活数亿的“超级应用”,但一定会成为AI应用爆发之年,谁能先找到用户的刚需,做出“超级有用”的应用,就能抓住这一波机会。
AI技术正在以前所未有的速度改变着行业格局,成为推动社会进步的重要力量。关于AI对产业的改变行业改造,李彦宏曾做出判断:大模型对于ToB业务的改造会是非常深刻和彻底的,比互联网对于ToB的影响力要大一个数量级。
在产业落地方面,百度文心大模型的步伐很快。数据显示,百度智能云千帆大模型平台已帮助企业精调3.3万个模型,开发77万个应用。这张AI成绩单显示,在IDC报告中,百度智能云以7项满分的成绩,获得中国生成式AI应用开发平台综合评分第一。
让AI应用在千行百业爆发,“无行业不AI”的最终实现,仰赖技术和工具基础。
模型能力首当其冲,最终能脱颖而出的AI应用一定是基于最强的基座大模型的。过去一年,各大模型厂商都在卯足了劲儿去提升自己的模型能力。值得期待的是,百度计划在2025年初推出新版文心大模型,这将进一步提升基础模型能力,为AI应用的全面爆发提供有力支撑。
2025年,AI行业注定进入全面爆发的新时代,智能体的普及、“超级有用”的应用崛起,以及AI在企业与个人场景中的深度融合,将成为推动行业向前的三大主轴。在这一过程中,以百度为代表的科技巨头正扮演着开路先锋的角色,推动AI普惠,让每个人都切实享受到AI红利。
 0赞
0赞好文章,需要你的鼓励
 推荐文章
推荐文章
Anthropic发布SCONE-bench智能合约漏洞利用基准测试,评估AI代理发现和利用区块链智能合约缺陷的能力。研究显示Claude Opus 4.5等模型可从漏洞中获得460万美元收益。测试2849个合约仅需3476美元成本,发现两个零日漏洞并创造3694美元利润。研究表明AI代理利用安全漏洞的能力快速提升,每1.3个月翻倍增长,强调需要主动采用AI防御技术应对AI攻击威胁。
NVIDIA联合多所高校开发的SpaceTools系统通过双重交互强化学习方法,让AI学会协调使用多种视觉工具进行复杂空间推理。该系统在空间理解基准测试中达到最先进性能,并在真实机器人操作中实现86%成功率,代表了AI从单一功能向工具协调专家的重要转变,为未来更智能实用的AI助手奠定基础。
Spotify年度总结功能回归,在去年AI播客功能遭遇批评后,今年重新专注于用户数据深度分析。新版本引入近十项新功能,包括首个实时多人互动体验"Wrapped Party",最多可邀请9位好友比较听歌数据。此外还新增热门歌曲播放次数显示、互动歌曲测验、听歌年龄分析和听歌俱乐部等功能,让年度总结更具互动性和个性化体验。
这项研究解决了现代智能机器人面临的"行动不稳定"问题,开发出名为TACO的决策优化系统。该系统让机器人在执行任务前生成多个候选方案,然后通过伪计数估计器选择最可靠的行动,就像为机器人配备智能顾问。实验显示,真实环境中机器人成功率平均提升16%,且系统可即插即用无需重新训练,为机器人智能化发展提供了新思路。









