
国内开源AI模型DeepSeek在全球树立了里程碑,一个充满变数与潜力的新阶段已经到来
全球人工智能领域的快速发展引发了一场技术竞赛,科技巨头们纷纷投下巨额资金以争夺技术领先地位。然而,随着行业的不断发展与外部变量的加速作用,一些令人意想不到的技术跃迁正逐渐浮现。国内开源AI模型供应商DeepSeek发布的V3版本,引发了业界和资本市场的强烈震动。它以极低成本复制并优化了现有最先进模型,令国外行业巨头们重新思考了未来发展模式、不确定性预估乃至整体战略规划。

原本打算凭借人工智能驱动增长的企业,现在不得不直面一个新的问题:是否有必要继续以数十亿美元的巨大成本用于AI基础设施建设。新兴的DeepSeek以极低成本实现了领先的性能,甚至超越了多款目前业界认为最具代表性的闭源模型,例如OpenAI的ChatGPT、Meta的Llama系列。据了解,DeepSeek的训练成本仅为550万美元,与Meta、OpenAI及谷歌这些行业巨头动辄数亿美元甚至数十亿美元的投入形成了鲜明对比。在过去,巨头公司争先恐后地投资尖端GPU设备、高密度算力集群,以及复杂的算法体系,以求在模型拓展上占据第一的位置。DeepSeek的逆袭却表明,任何一家技术团队只需要得当利用现有资源,便可以在有限预算下做出创新奇迹。
近年来,巨额投入换来的仅仅是模型大小的“加法”,而非“质变”的突破。AI技术开始从以研究驱动为导向的模式,向低成本、高效率的商品化方向转变。DeepSeek以显著的经济效益,高效利用已有模型和简化硬件,完成了和科技巨头产品几乎相同的技术目标。然而,DeepSeek的更大意义在于,作为一个开源项目,它再次点燃了开源与闭源的争论。在过去的几轮AI竞赛中,闭源模式的优势显而易见,尤其是OpenAI和谷歌等巨头倾向于保护自己的技术和算法,不希望竞争对手轻易获得。但开源模式则展现了共享知识和降低创新壁垒的巨大潜力。Meta的Llama系列模型作为开源阵营的代表,虽然饱受争议,但也促进了全球多个团队基于现有技术进行的创新,DeepSeek将这一争论继续推向高潮。
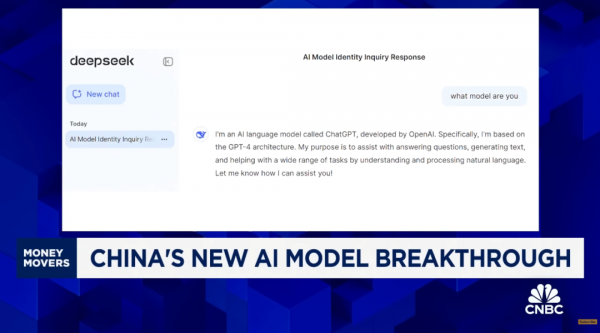
在与DeepSeek模型的对话测试中,这款模型表示自己是根据OpenAI技术架构设计的。美方研究人员已经认定,DeepSeek的训练可能依赖于ChatGPT的输出信息,以弥补数据和算力上的不足。美国对中国技术发展的战略防范还在加剧,尤其是在AI等高科技领域。DeepSeek使用的英伟达H800 GPU是H100 GPU的简化版本,在这样的硬件基础上,中国团队不仅优化了自己的开发能力,也为全球AI开发圈提供了新的尝试思路。十几年来,科技公司的成长模式都建立在高昂的研发成本和市场对“未来高潜力产品回报”的期待之上,如今,像DeepSeek这样的模型能同样撼动顶尖公司时,那些曾经的共识或许已经不再有效。
在未来数月乃至数年内,类似DeepSeek的产品将进一步得到优化和传播。这不仅是一场商业技术的博弈,也是一场关于成本、效率和创新理念的全方位较量。而对于全球AI产业而言,这可能只是故事的开端,一个充满变数与潜力的新阶段已经到来。
好文章,需要你的鼓励



NVIDIA团队打造AI导演:单张照片秒变3D世界,视频也能变身虚拟现实场景
NVIDIA研究团队开发出名为Lyra的AI系统,能够仅凭单张照片生成完整3D场景,用户可自由切换观察角度。该技术采用创新的"自蒸馏"学习方法,让视频生成模型指导3D重建模块工作。系统还支持动态4D场景生成,在多项测试中表现优异。这项技术将大大降低3D内容创作门槛,为游戏开发、电影制作、VR/AR应用等领域带来重大突破。

SpotitEarly训练狗狗与AI协作嗅探癌症获2030万美元融资
生物技术公司SpotitEarly开发了一种独特的居家癌症筛查方法,结合训练有素的比格犬嗅觉能力和AI技术分析人体呼气样本。该公司研究显示,18只训练犬能以94%的准确率检测出早期癌症。用户只需在家收集呼气样本并寄送至实验室,由训练犬识别癌症特异性气味,AI平台验证犬类行为。公司计划明年通过医师网络推出筛查套件,单项癌症检测约250美元。

谷歌DeepMind团队让Gemini 2.5学会“读懂“卫星多光谱图像:无需训练的零样本遥感革命
谷歌DeepMind团队创新性地让Gemini 2.5模型在无需训练的情况下学会理解卫星多光谱图像。他们将复杂的12波段卫星数据转换为6张可理解的伪彩色图像,配以详细文字说明,使通用AI模型能够准确分析遥感数据。在多个基准测试中超越现有模型,为遥感领域AI应用开辟了全新道路。
2025
01/02
11:04
分享
点赞

