
清华提出ArtCrafter!可控多样的风格迁移框架!
数源AI 最新论文解读系列

论文名:ArtCrafter: Text-Image Aligning Style Transfer via Embedding Reframing
论文链接:https://arxiv.org/pdf/2501.02064

导读
基于扩散的文本到图像生成在个性化和定制领域取得了显著进展,特别是在身份保护、对象定制和风格转换等一致性合成方面。特别是文本引导的风格转换关注细粒度的风格表现,涵盖纹理、颜色、构图和材质等抽象概念,以创造一系列基于文本语义本质的个性化输出。当前方法通常使用预训练的扩散模型进行风格化任务,通过添加一个可训练的适配器模块而不进行完全重新训练来增强模型特征。在文本到图像风格转换应用中,基于适配器的方法通过调整输入图像和文本提示的条件指导比例来塑造输出的风格和内容的形状。
简介
我们引入了ArtCrafter,这是一种新颖的文本到图像风格迁移框架。具体来说,我们引入了一个基于注意力的风格提取模块,该模块经过精心设计,以捕捉图像中微妙的风格元素。该模块采用多层架构,利用感知注意力机制的能力整合细粒度信息。此外,我们提出了一种新颖的文本-图像对齐增强组件,巧妙地在两种模态之间平衡控制,使模型能够高效地将图像和文本嵌入映射到一个共享的特征空间。我们通过注意力操作实现模态间的平滑信息流动来实现这一点。最后,我们引入了一种显式的调制机制,通过嵌入重框架设计无缝地将多模态增强嵌入与原始嵌入融合在一起,使模型能够生成多样化的输出。广泛的实验表明,ArtCrafter在视觉风格化方面取得了令人印象深刻的结果,展现出卓越的风格强度、可控性和多样性。
方法与模型
ArtCrafter的整体架构如图3所示。ArtCrafter基于扩散模型构建。我们引入了基于注意力机制的样式提取方法,该方法通过接收器注意力和多层设计捕获多级样式信息。文本-图像对齐增强允许模型动态权衡文本提示不同部分的重要性。这使得生成过程更加细致且具有上下文感知能力,从而生成与文本提示更紧密相关的图像。显式调制提供了一种有效的方式来结合文本和视觉信息,使模型能够生成既与文本提示相关又具有多样化视觉表现的图像。
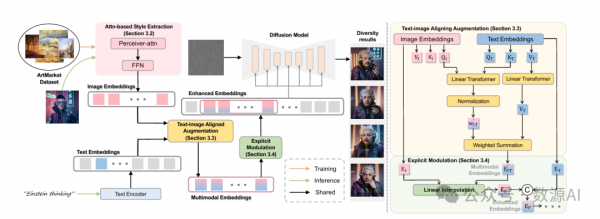
1. 初步
扩散模型[33]包括两个过程:一个正向过程,通过马尔可夫链逐步向数据c0添加高斯噪声e。此外,去噪过程利用一个由参数θ定义的可学习去噪模型εθ(xt,t,c),从高斯噪声xT~N(0,1)生成样本。这个去噪模型εθ(·)采用U-Net[34]实现,并以由变分界限简化变体得出的均方误差进行训练。
其中c表示一个可选条件。在扩散模型中,c通常由使用CLIP[31]从文本提示编码的文本嵌入表示,并通过以下设计的模块(第3.4节)整合到扩散模型中。
2. 基于注意力的风格提取
本节详细阐述了风格提取方法,该方法通过多层架构整合细粒度特征来增强风格编码能力。其目的是通过利用感知器注意力[18]和位置前馈网络(FFN)[41]捕捉图像中的复杂风格细节。
给定参考图像,我们通过CLIP获得输入图像嵌入,记作x。潜在变量z初始化为形状为(1,N,D)的张量,其中N是查询数量,D是潜在空间的维度,并通过除以D的平方根进行归一化以稳定训练过程:
为了匹配输入x的批量大小,我们通过沿批量维度重复潜在变量z来对其进行扩展。这个过程可以表示为:
其中, 是一个形状为 (B,1,1) 的全1张量,B 是 x 的批量大小。该操作产生一个形状为 (B,N,D) 的张量 z,其中 N 是查询的数量,D 是潜在空间的维度。
然后应用名为 P-Attn 的感知器注意力机制,通过关注输入 x 和重复的潜在变量来更新潜在变量:
其中, 是键张量的维度,通常等于D。该操作允许模型根据可学习的潜在变量选择性地关注输入数据的不同部分。
FFN由两个线性变换组成,中间有一个GELU激活函数:
其中, 和 是权重矩阵, 和 是偏置项。输出 代表从输入图像中提取的风格嵌入,通过结合FFN输出和更新后的潜在变量 得到:
3. 文本-图像对齐增强
文本-图像对齐增强方法旨在通过利用跨注意力机制动态地为文本提示的不同方面优先考虑。该模块允许模型更有效地整合图像和文本嵌入,将它们投影到一个共享的特征空间中,以便它们的互动可以更为细致。
我们首先通过线性层将图像提示嵌入 和文本提示嵌入 转换为查询、键和值矩阵。这些转换表示为:
、 和 分别代表与图像查询、文本键和文本值相关联的权重矩阵。注意力权重 是通过计算查询矩阵 和键矩阵 的点积得到的,并通过键维度 的平方根进行缩放以防止梯度消失:
然后,将softmax函数应用于这些原始注意力分数,以获得标准化的注意力权重 :
使用规范化的注意力权重 ,我们计算价值矩阵 的加权和,以生成多模态嵌入 :
更有效地捕捉多模态上下文,使模型能够生成与文本提示的语义内容更为紧密对齐的图像。在需要将文本和视觉信息紧密结合以产生连贯输出的场景中,这种方法特别有益。
4. 显式调制
显式调制通过利用线性插值无缝融合图像嵌入与文本-图像对齐的增强多模态嵌入,解决了传统融合方法缺乏灵活性的问题。具体来说,我们通过线性插值融合图像嵌入 与多模态嵌入 :
其中, 是一个预定义的常数,用于控制原始嵌入与增强嵌入之间的融合比例。最终,我们将融合后的图像嵌入 与文本提示嵌入 来形成完整的提示嵌入,用于图像生成:
其中, 表示串联操作, 代表增强嵌入,并整合到扩散模型中。通过平衡上述嵌入,模型获得了一个鲁棒且可控的表示,有效地捕捉了多模态条件,提高了生成性能。
实验与结果
4.2 定性评估
在定性评估中,ArtCrafter与其他现有的文本引导风格化方法进行了比较,包括Styleshot、Style Aligned、VSP、InstantStyle、InstantStyle(Plus)、IP-Adapter、IP-Adapter(SDXL)、CSGO和StyleCrafter。通过视觉评估,ArtCrafter在风格表现、细节捕捉和风格一致性方面表现出色。例如,在“时尚鞋”这一描述下,ArtCrafter能够生成与文本对齐的多种鞋型,而其他方法则出现了不一致或多样性不足的问题。


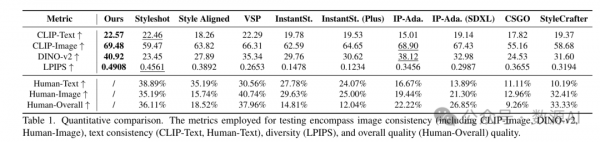
4.3 定量评估
定量评估采用了多种指标,包括CLIP-Text、CLIP-Image、DINO-v2和LPIPS。ArtCrafter在这些指标上均优于其他方法,显示出其在生成与目标描述和风格高度一致的图像方面的优势。特别是,ArtCrafter在保持内容细节的同时,还能维持高质量的样式转移和多样性。
4.4 用户研究
用户研究进一步验证了ArtCrafter的有效性。艺术领域的专业人士对生成的图像进行了评分,结果显示ArtCrafter在文本一致性、图像一致性和整体视觉吸引力方面得分最高。这表明ArtCrafter在用户眼中实现了更好的平衡和综合表现。
4.5 消融研究
消融研究通过移除每个关键组件来评估其对模型性能的影响。结果表明,基于注意力的风格提取、文本-图像对齐增强和显式调制组件各自对提高图像一致性、文本内容指导和生成多样性起到了重要作用。


总结
在本文中,我们介绍了ArtCrafter,这是一种通过嵌入重构架构实现的新型文本-图像对齐风格迁移框架。我们的方法通过集成三个核心组件确保了卓越的文本引导风格迁移质量:基于注意力的风格提取、文本-图像对齐增强以及显式调制。全面的评估展示了ArtCrafter在适应多样艺术风格、保持文本提示一致性、增强输出多样性以及提升整体视觉质量方面的优势。
好文章,需要你的鼓励


FERC要求NERC为数据中心等计算负载制定强制可靠性标准
美国联邦能源监管委员会(FERC)于7月16日发布命令,要求北美电力可靠性公司(NERC)在2026年12月31日前,针对数据中心、加密货币矿场等计算负荷制定强制性电网可靠性标准。此前,NERC已观察到大型数据中心负荷引发电网不稳定事件,并于2026年5月发布最高级别警报。FERC指出,自愿性时间表无法提供足够确定性,必须以强制联邦要求取代,以应对AI数据中心驱动的前所未有的负荷增长对电网可靠性构成的威胁。

广东人工智能研究院开发的“图像创作指挥家“,能像大厨一样编排十几种视觉工具完成复杂图片任务
广东人工智能研究院提出CanvasAgent,通过编排11种专业视觉工具,将复杂图像创作任务拆解为可执行的多步操作,并配套构建了14万条SFT轨迹数据和1万条RL任务规格的CanvasCraft数据集。

西子洁能加快美国燃机余热锅炉订单,24年NE技术合作接住数据中心供电需求
今天讲的出海案例是西子洁能,这家余热锅炉制造商依托24年美国NE技术合作,加快北美燃机余热锅炉订单转化。

当学术写作遇上AI“大管家“:Bibby AI如何把研究者从工具切换的泥潭中解救出来
Bibby AI是一个原生集成编辑器、编译器、文献检索和AI智能体的学术写作平台,将碎片化的研究工具链压缩为单一系统,并引入专利引用信号衡量文献技术影响力。
2025
01/10
13:04
分享
点赞

