
新华三推出AI数据平台解决方案,加速推理驱动智算时代
近日,紫光股份旗下新华三集团(以下简称“新华三”)宣布推出基于 NVIDIA AI 数据平台参考设计的技术集成方案,打造更智能、更灵活、更安全的大模型数据处理能力,为AI推理场景注入新能力和强劲动能。
当前,在大模型实时交互场景中,用户对AI服务的响应速度要求极高;同时,如果AI推理没有基于新的或更新过的内容,就会造成生成内容与事实不符、逻辑错误等情况,严重影响其可靠性和实用性。新华三新推出的 AI 数据平台解决方案,打通“算力”和“存力”之间的效率鸿沟,实现从底层硬件到上层 AI应用的数据流通加速,大幅提升AI推理的实时性、相关性与准确度,不仅优化了大模型的整体运行效率,也显著改善了真实场景中使用大模型时的响应速度与使用体验。
H3C AI数据平台解决方案:软硬协同 推理加速
AI数据平台解决方案整合了新华三与NVIDIA的领先技术,打造存算网技术深度集成的智能数据平台,并通过上层软件平台协同优化,为AI基础设施注入强劲动能,显著提升AI大模型的推理能力。
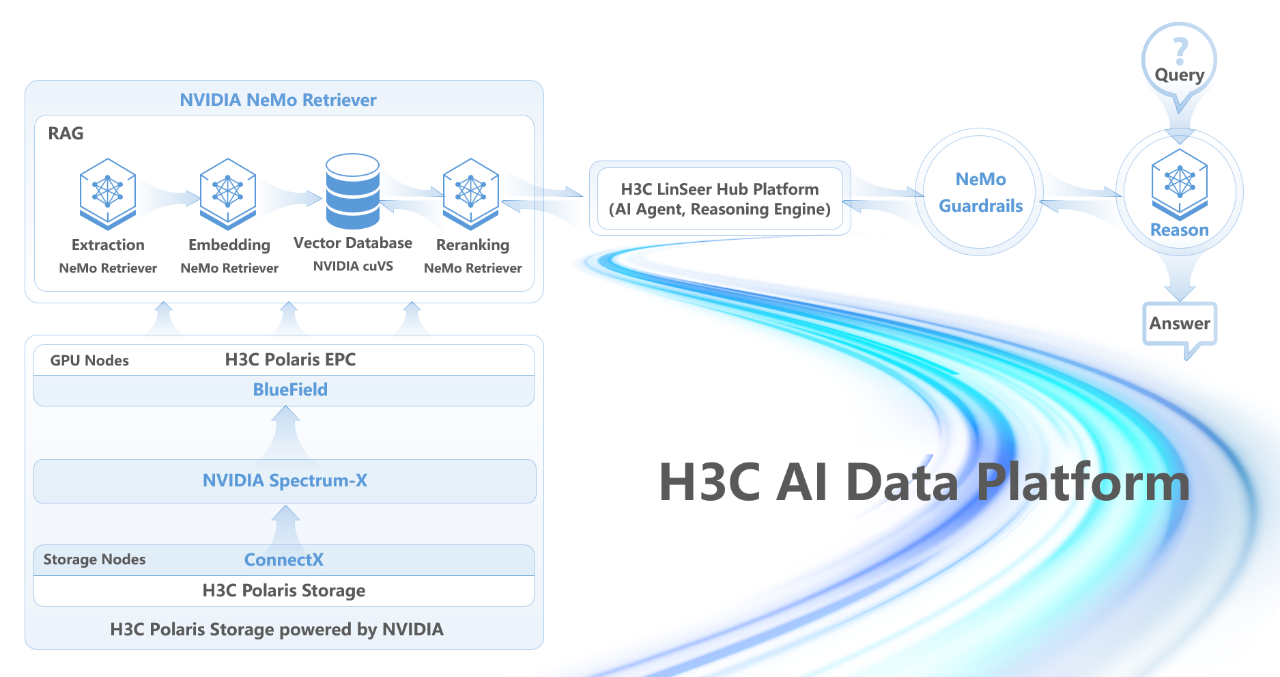
存算网深度集成,打通推理性能瓶颈
AI数据平台解决方案集成了NVIDIA Spectrum-X AI以太网网络平台,包括Spectrum以太网交换机、NVIDIA BlueField-3 DPU 数据处理器及NVIDIA ConnectX SuperNIC,将普通以太网的带宽利用率从50-60%提升至97%以上,有效应对瞬时流量高峰,保障存储与计算节点间的高速互连。BlueField-3 DPU可与H3C Polaris X20000存储系统完美适配,支持NVMe over Fabrics、NVIDIA GPU-Direct Storage(GDS)等技术,实现存储卸载和加速,涵盖数据冗余、完整性校验、解压缩和重复数据删除等功能,进一步提升存储性能并降低功耗。
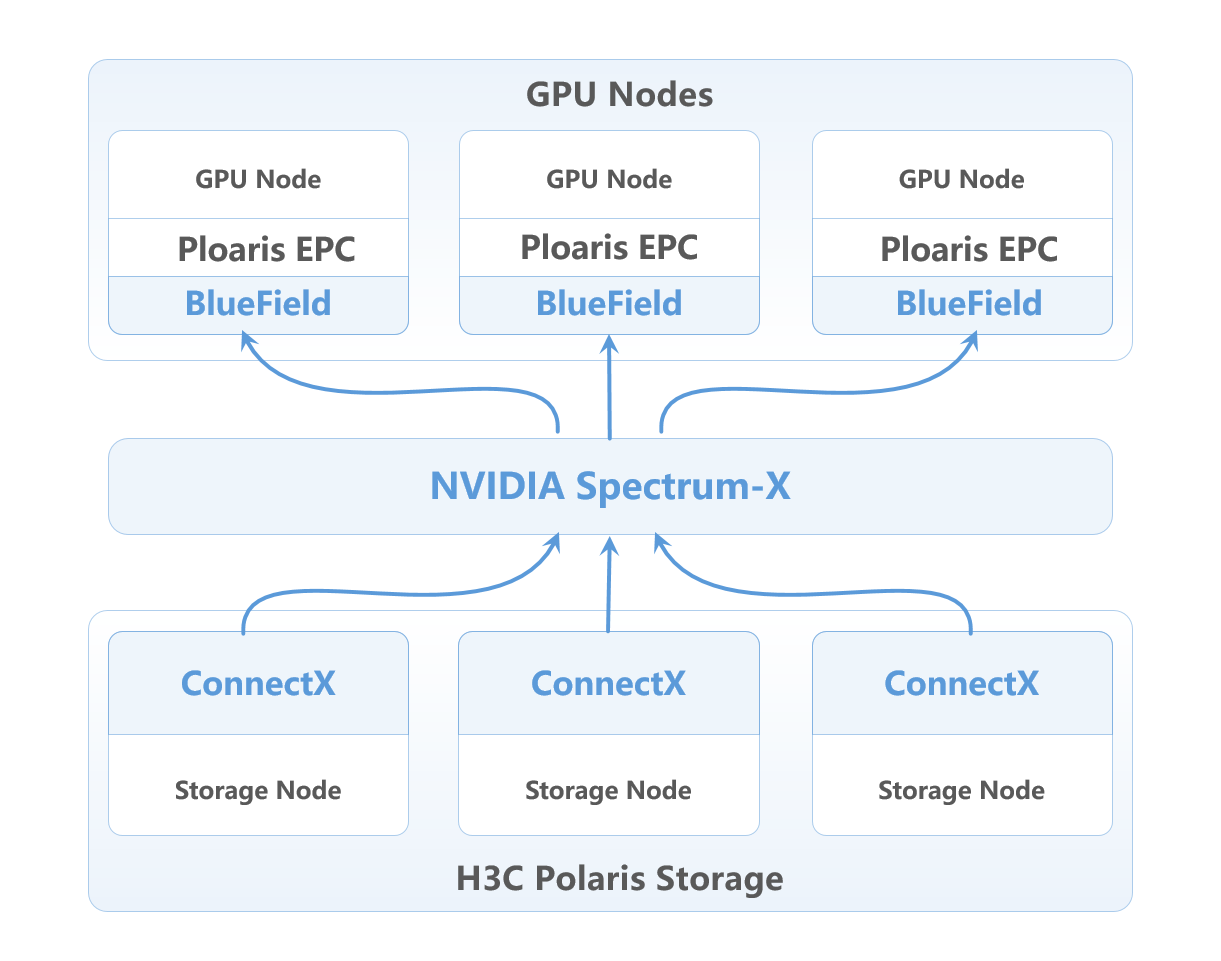
新华三Polaris X20000系列专为AI智算场景设计,采用全新自研存储引擎,面向AI/HPC场景下的海量数据处理需求提供极致性能,单节点实现120GB/s带宽和200万IOPS,集群性能近线性增长,满足AI大模型训练中海量小文件高并发和百TB级带宽需求;并将块、文件、对象与HDFS协议集成于统一存储平台,从数据采集、模型训练到分发全流程实现数据零迁移。同时,系统大幅提升可靠性,毫秒级故障上报与秒级切换确保训练任务不中断,计划内/外升级扩容对上层应用无感,为企业提供稳定、高效的存储支持。
软件平台协同优化 加速智算推理引擎
在 AI-Q NVIDIA Blueprint 的支持下,代理式系统可以连接到新华三Polaris X20000高性能数据存储平台上,AI-Q 使用NVIDIA NeMo Retriever 加速数据提取和检索,NVIDIA NeMo Retriever 是用于处理海量结构化、半结构化及非结构化数据(如文本、PDF、图像、视频等)的软件。如此,可显著加速RAG(检索增强生成)应用的响应速度。
同时 NVIDIA NeMo Guardrails 可确保推理问答交互的安全性、准确性和主题相关性。新华三自主研发的灵犀使能平台(LinSeer Hub)则作为上层管理平台,提供了AI智能体和推理引擎的功能。
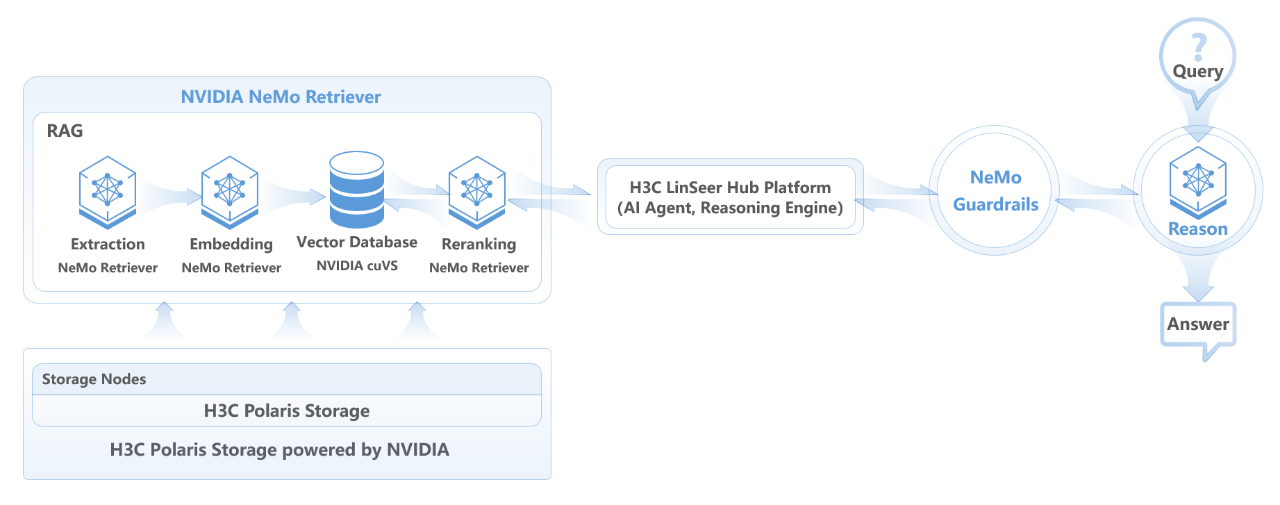
通过上述组件的深度整合,AI 数据平台解决方案显著提升大模型的推理性能与Token处理速度,为企业提供实时数据洞察能力,助力业务场景的智能化升级。
数据驱动 加速推理 引领智算未来
随着AI大模型的快速发展,数据已成为AI生产力的核心要素,与此同时,企业核心生产数据80%存储于外置专业存储,新华三作为存储领域的领先厂商,以Polaris X20000系列的卓越性能和灵活性,提升了AI 数据平台的能力。NVIDIA则通过硬件加速和软件能力,释放Polaris存储硬件的潜力,帮助新华三实现从“数据仓库”到“智能数据平台”的转型,形成完整的AI数据闭环。并结合存储厂商成熟的数据管理能力,构建高效AI基础设施。
作为数字化及AI解决方案提供者,新华三拥有深厚的市场积累和广泛的行业覆盖,服务于金融、电信、政务、医疗、教育、制造等多个领域。新华三此次推出的AI 数据平台解决方案,是新华三“算力╳联接”技术战略的持续深化。未来,新华三将持续携手生态伙伴,推动AI数据平台的技术革新与产业落地,助力百行百业实现高效、智能、可信的AI转型。
好文章,需要你的鼓励


OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
OpenAI在与多家新闻机构的版权诉讼中陷入困境。以《纽约时报》为首的原告指控OpenAI在长达两年时间里向法庭撒谎,刻意隐瞒其已对ChatGPT日志进行大规模搜索的事实。据悉,OpenAI实际上已拥有包含1000万和7800万条记录的日志样本,并曾用于研究版权内容过滤器,却对外声称无法进行此类搜索。原告据此提出制裁动议,要求法院追责。OpenAI则否认相关指控,坚称其立场基于合理使用原则。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

外科医生远程操控人形机器人,完成全球首例活猪手术
美国加州大学圣地亚哥分校研究团队在《自然》期刊发表研究成果:外科医生通过远程操控宇树G1仿人机器人,成功完成两例活体猪胆囊切除手术,创下全球首例。与造价数十至数百万美元的达芬奇手术机器人相比,仿人机器人成本更低、体积更小,未来有望部署于农村、战地乃至太空等资源匮乏的医疗场景。但目前仍存在需频繁重新校准、机械臂活动范围受限等挑战。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2025
05/20
11:54
分享
点赞

OpenAI在版权诉讼中疑因隐瞒证据遭遇重大危机
外科医生远程操控人形机器人,完成全球首例活猪手术
OpenAI发布ChatGPT Work:AI助手可连续工作数小时
欧盟向Meta施压:关闭自动播放和无限滚动,否则面临巨额罚款
世界模型的潜力与局限:它真的能模拟一切吗?
苹果起诉OpenAI:前员工利用系统漏洞窃取商业机密
如何利用开源AI智能体实现工作流程自动化
Cloudzy 云服务评测:VPS 性能与体验全面解析
这款PCIe插卡内置38核至强处理器与64GB内存,堪称完整服务器
是否该为企业招募数字员工?AI 智能体团队搭建全指南
AI赋能自主机器人:从工厂走向家庭的未来图景
数据中心能源需求威胁特朗普"美国制造"计划
