
Omdia《中国人工智能框架市场调研报告》: 预训练大模型、AI for Science等成为产业焦点
行业研究机构Omdia(Informa tech集团旗下)发布《中国人工智能框架市场调研报告》,指出中国AI框架市场竞争格局与创新趋势。Omdia调研发现,PyTorch、TensorFlow与MindSpore在知名度与市场份额上处于第一梯队。
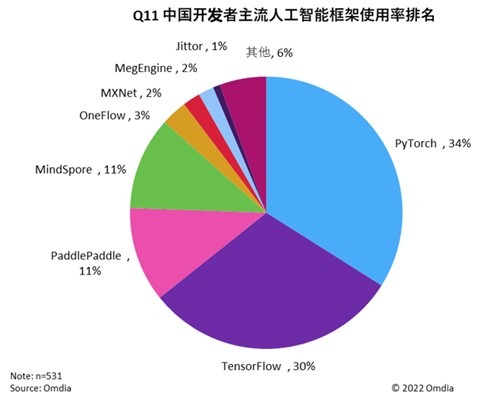
人工智能随着技术的发展逐渐出现在大众眼前,作为新兴产业,市场规模不断扩大,应用场景也随着人工智能技术的成熟而扩展。从科研创新到产业应用落地,预训练大模型、AI for Science、负责任的AI等已成为全球学术界、产业界的焦点。AI框架是模型算法开发的核心,是支撑人工产业繁荣发展的基础,因此Omdia深入研究了AI框架的发展与产业趋势。
时下,以ChatGPT为代表的大模型获得的瞩目已经超越学术界、产业界,成为所有人的关注的创新成果,而大模型需要有强大的AI框架技术支撑。报告指出预训练大模型的三大趋势:第一,大模型参数量继续呈指数增长态势,“大模型”正走向“超大模型”;第二, 大模型正从单模态走向多模态、多任务融合; 第三,人工智能框架对大模型的训练有关键性的技术支撑作用。
在支持超大规模模型训练开发方面,全球领先的人工智能框架TensorFlow和PyTorch仍然占据领导地位;同时,开发者认为在中国本土人工智能框架中昇思MindSpore已占据优势地位,原生支持大模型,并孵化出了一系列创新大模型。
Omdia通过与专家深度访谈,发现TensorFlow由于有了JAX这一新生框架的融入,给业界带来更多期待;PyTorch则是依托第三方并行算法库补充了大模型支持能力;在中国本土市场上, 百度飞桨和昇思MindSpore由于有独特的中国本土语言和数据优势,更能在支持本土预训练大模型方面取得成功。
在以ChatGPT为代表的AIGC火爆的背后, 也出现了“造假”等AI伦理道德问题,人工智能开发者和机构越来越关注“负责任的人工智能”。 Omdia在对开发者的调研中发现,在所有主流人工智能框架中,TensorFlow 与MindSpore 对“负责任的人工智能”提供的支持能力最好,分别是第一与第二名。
同时,《中国人工智能框架市场调研报告》指出,“负责任的人工智能”既是一套道德准则, 又是一套技术体系。“负责任的人工智能”是以安全、可靠和合乎道德的方式开发、评估、部署和规模化人工智能系统的方法。人工智能框架引入众多的技术手段和可信AI功能模块,帮助开发者打造可信AI,帮助开发者和机构解决人工智能的安全隐私等合规性问题, 实现人工智能的可持续发展。
在科研创新领域,“AI for Science”也是人工智能行业的前沿热点,人工智能与科学的深度融合正在推动科研范式的创新,给科研领域带来了新的发展机遇。Omdia的分析师认为,与大模型类似,“AI for Science”是AI创新发展的新的重要方向,而人工智能框架对“AI for Science”的发展起着关键的技术支撑作用。“AI for Science”的发展对人工智能框架提出了更高的要求,调研发现,中国的人工智能开发者认为昇思MindSpore是最适合做 “AI for Science”项目的国产人工智能框架, 其对“AI for Science”的支持能力甚至超过了PyTorch,并有赶超TensorFlow的趋势。
人工智能框架作为AI创新的重要基础,将助力行业加速智能化转型升级。更多人工智能框架调研发现,请查看《中国人工智能框架市场调研报告》。Omdia报告链接:
https://omdia.tech.informa.com/commissioned-research/articles/china-ai-frameworks-market-report-2023
好文章,需要你的鼓励



Meta开发的AI编程助手,真的懂你吗?还是需要你反复“纠正“它才能干活?
Meta团队推出SWE-Together评测框架,将真实用户与AI编程的多轮对话转化为可复现的测试题,首次将"用户需要纠正AI多少次"纳入评分体系。

亚马逊 Mechanical Turk 将停止接受新用户注册
亚马逊宣布,其众包服务Mechanical Turk将于2026年7月30日停止接受新用户注册。现有用户可继续正常使用,AWS也将持续维护安全性,但不再引入新功能。该平台自2005年上线以来,曾是人工标注数据的重要来源,并在AI训练领域发挥过关键作用。然而近年来平台逐渐衰退,2023年研究显示33%至46%的任务已由大语言模型完成,平台价值受到质疑。业界普遍认为该服务已名存实亡。

AI模型的“肌肉记忆“:阿联酋人工智能大学揭示为何安全训练会被无害微调悄悄抹去
阿联酋MBZUAI研究团队发现,AI安全对齐后的"引力回归"现象:良性微调会沿着可预测的几何方向使模型悄悄恢复危险行为,且该方向可被测量和干预。
2023
02/10
10:40
分享
点赞

5060 Ti 16GB 跑本地 AI,真不如加钱买二手 3090?
散热为什么成了AI算力的“阀门”?
亚马逊 Mechanical Turk 将停止接受新用户注册
量子力学百年演进:从费解理论到改变世界的技术基石
Uber欧洲扩张计划遭遇阻碍,五国上线暂停
Claude Sonnet 5 发布:编码、推理与工具使用能力全面提升
AI高速扩张正悄然考验电网承载极限
福特对AI失望,重新雇用350名经验丰富的工程师
首批四家云服务商加入CISPE欧盟云主权认证计划
2026 Eurobike 展会:最值得关注的电动自行车与新奇产品盘点
联想Legion 7i Gen 10游戏本评测:颜值在线,性价比存疑
杀毒软件已不够用?全面了解现代网络安全防护
DeepSeek之后,中国人形机器人以“群体智能”再次掀起技术浪潮
QwQ-32B模型成本地部署福音,通义App可第一时间体验
入局智驾的印奇,看到了怎样的未来?
成本打到6万以下,手把手教你用4路锐炫显卡+至强W跑DeepSeek
千里科技亮相吉利AI智能科技发布会,共启“AI+车”新纪元
天翼云CPU实例部署DeepSeek-R1模型最佳实践
京东云与宝德计算战略签约,共绘分布式存储与智算新未来
全球AI顶会AAAI 2025 在美开幕,产学研联手的“中国队”表现亮眼
蚂蚁数科提出创新跨域微调框架ScaleOT入选全球AI顶会AAAI 2025
国产软件再破记录!阿里云PolarDB数据库登顶TPC-C双榜第一
