
LLM指导3D说话面部生成!百度提出AVI-Talking!

论文名:AVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
论文链接:https://arxiv.org/pdf/2402.15391.pdf
引言
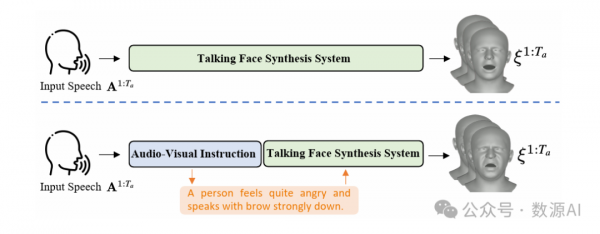
生成逼真的人脸三维动画对于许多娱乐应用至关重要,包括数字人类动画、电影视觉配音以及虚拟头像的创建。为了合成表现力丰富的基于语音驱动的3D说话人脸,先前的工作要么1)模拟动态头部姿态与音频节奏之间的关联,要么2)借用外部表示,如情感标签或视频剪辑作为生成过程中的风格参考。然而,头部动态具有有限的表现能力,因此只能产生粗略对齐,忽略了音频内容中存在的情感细微差别。后者的研究需要用 户手动选择风格来源,导致应用不自然。在本文中, 我们探索了更自然的情景,旨在直接利用语音传达的基础风格信息,生成与说话状态一致的富有表现力的说话人脸。
简介
在本文中,我们提 出AVI-Talking,一种用于生成表现力丰富说话面的Audio-Visual Instruction系统。该系统利用大型语 言模型(LLMs)提供的强大上下文推理和幻觉能力来指导3D说话面的逼真合成。我们的两阶段策 略不同于直接从人类语音中学习面部运动,而是首 先让LLMs理解音频信息并生成暗示与语音无缝对 应的表现力丰富面部细节的指令。随后,一个基于 扩散的生成网络执行这些指令。这一两阶段过程结 合LLMs的整合增强了模型可解释性,并为用户提供 了理解指令并指定所需操作或修改的灵活性。广泛 的实验展示了我们的方法在生成生动的说话面、具 有表现力的面部运动和一致的情感状态方面的有效性。
方法与模型
给定一个音频剪辑,我们的目标是用同步的嘴 唇运动和一致的面部表情来为一个模板网格添加动画。我们提议不直接从语音学习合成一个说话的脸, 而是将大型语言模型(LLMs)整合到合成过程中进 行指导。如图.2所示,我们的框架AVI-Talking包括 两个主要阶段:一个音频-视觉指导阶段和一个连接 详细面部表情描述的说话脸合成阶段。形式上,我 们的系统接受输入语音A1:Ta=Ta i=1,旨在生成 一系列3D参数系数ξ1:Ta=Ta i=1。
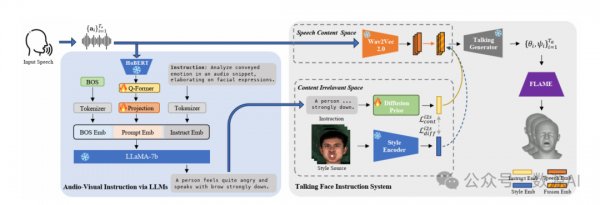
音视频指导模块以演讲者音 频片段的时间序列作为输入,旨在生成描述详细面 部运动并传达个体言语状态的指导语句。关键在于 开发一种提示策略,以有效利用LLMs中固有的丰富 上下文先验知识。
具体来说,我们利用预训练的LLaMA作为基础 文本生成模型。为了理解存在于音频模态中的演讲 者言语状态,音频信号需要投影到语言模型的文本 嵌入中。由于像HuBERT[18]在语音情感识别(SER) 任务上取得成功,我们利用HuBERT对音频信号进 行编码。随后,采用经典的Q-Former架构来聚合和 提取言语风格信息,弥合声学特征和视觉面部描述 之间的差距。然后学习线性投影层,将对齐特征映 射到语言模型的输入空间。将“BOS”(序列开头) 令牌与指导语句嵌入相结合,音频提示嵌入被馈送 到LLaMA以提示与演讲者状态一致的可能具有表 现力的面部运动。请注意,指导语句嵌入是通过对 预定义指导模板进行标记化获得的。在我们的实验 中,我们使用诸如分析音频片段中传达的情感,进 一步阐述面部表情之类的指导语句。我们手动编写 了10个意思相似的句子,并在训练阶段随机抽取其 中一个。
(1) Speech Feature Compression via Learnable Queries
从HuBERT提取的音频特征包含复杂信息,包 括语音内容、情绪状态和声学细节。为了有效地促 进语言模型,首先需要理解并从语音中提取相关的 面部运动信息。在这里,我们采用Q-Former架构[26, 1]来完成这项任务。
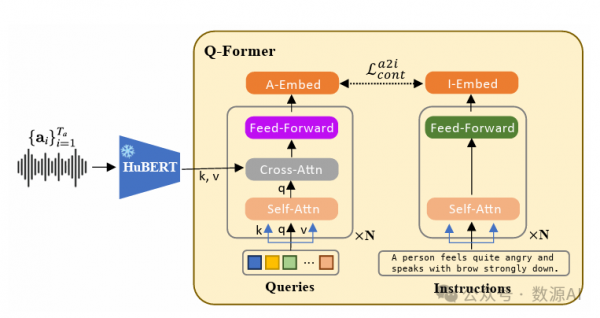
使用固定长度的可学习查询 通过交叉注意力聚合和压缩语音信息。值得注意的 是,这种做法导致一个与查询长度qa尺寸相同的音 频嵌入Fa si∈Rqa×l。这一设计选择简化了学习过程, 并增强了处理不同长度语音输入时的泛化性能。随 后,音频嵌入被馈送到一个投影模块,以在语言模 型空间中进行提示嵌入。为实现这一点,我们通过 领域适应微调输入投影层中的少量参数。
(2)Contrastive Audio-Visual Instruction Alignment
为了消除不必要的信息,如语音内容、环境噪 音,并着重于提取与面部动作相关的特征,我们采 用对比学习协议来约束学习查询的输出Fa si ∈ Rqa×l。对比学习范式将音频嵌入和指令特征进行对 齐,以最大化它们的互信息。通过增强正对样本的 音频-指令相似性来实现这一点,其优于负对样本的 相似性。具体来说,我们将相应的指令通过文本转 换器传入,并获得一个指令嵌入,如图3右侧所示。其[CLS]令牌的输出嵌入为Fi si∈Rl。由于有qa个 查询嵌入,我们对所有查询的Fa si进行平均以获得 ? Fa si∈Rl,并按以下方式应用对比学习:

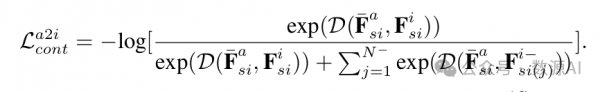
配对的批内样本被视为正样本(? Fa si,Fi si),而不配对 的N–样本被视为负样本(? Fa si,Fi– si(j))。在这里,我们选择余弦距离D(F1,F2)= FT 1*F2 |F1|·|F2| 作为特征距离度 量。
(3)Instruction Generation via Projection Layer Finetuning
在将Q-Former预先训练以对齐声学特征与视觉 面部描述之后。随后,我们冻结Q-Former,并微调 LLaMA-7b的输入线性投影层,以实现视觉指导预 测。具体来说,我们遵循一般文本生 成训练范式来学习这个投影层。
通过获得的面部指令,一个语音合成网络旨在 使用同步唇部动作和表情来激活 一个网格模板。唇部运动和面部表情表现出很高的 相关性。例如,特定的发音通常传达相关的情 感。为了解决这种相关性和潜在的交织,我们首先 提出训练一个解耦的语音先验,其中区分了 语音内容空间和与内容无关的空间。随后,提出了扩散先验模块),以在识 别的内容无关空间内弥合指令文本和语音风格之间 的差距。
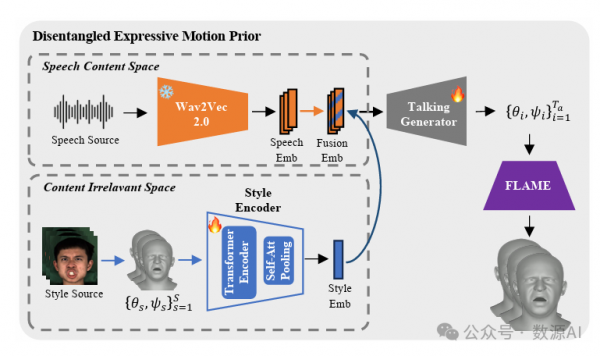
(1)Disentangled Expressive Motion Prior
我们旨在建立一个解耦的潜空间, 其中与语音内容相关的唇部运动和与说话状态相关的面部表情在“语音内容”空间和“内容无关”空 间中分别被明显表示。
具体来说,在语音内容空间中,我们使用预训 练的ASR网络,Wav2Vec2.0对说话者音频A1:Ta 进行编码。这些提取的语音特征捕获了语义内容信 息,随后被口型生成器用于音节发音。为了编码额 外的说话风格信息,我们指出存在着用于表示内容 排斥信息的“内容无关”空间,例如说话风格、姿 势和说话者身份。
为了学习“内容无关”空间,我们采用了基 于transformer的风格编码器[33],旨在捕获内容 排斥信息。对于给定的说话视频,我们随机选择 S个参考帧作为说话状态的源。然后,这些帧经 过FLAME模型处理,得到系数S s=1,其中在 时刻t的系数被排除。随后,这些系数被馈送到风 格编码器中,以提取视频的全面说话状态表示。为 了成功预测当前时刻的系数,我们依赖于 “语音内容”空间中的语音特征At和“内容无关” 空间中提取的风格信息。这些属性的互补性自然有 助于学习解耦的空间。
(2)Contrastive Instruction-Style Alignmentand Diffusion
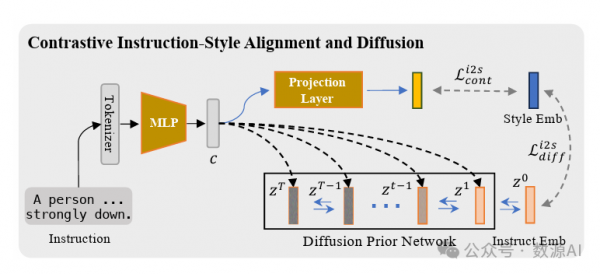
一旦确定了内容无关空间,跨模态生成的自然 方式是将视觉指导映射到此空间内的表示[32]。如 图5所示,首先衍生出一个多层感知器(MLP)网 络,以便将潜在指导表示与风格嵌入进行对齐。采 用了典型的对比损失Li2s cont,遵循标准的CLIP训练过程[43],我们在此不进行详述。然而,由于这种多 模态对比学习策略仅推动指导嵌入与其关联的风格 图像特征保持紧密方向,由于存在模态差距的存在, 容易导致不连续的嵌入[29]。为了进一步激活期望 视觉风格嵌入的运动先验,我们引入一个扩散先验 网络来通过映射到它们的分布来弥合模态差距。
对于扩散先验网络Fθ,我们利用典型的仅解码 器Transformers架构来迭代地预测以上表示c为条件 的去噪风格嵌入zt。与施加错误预测公式不同[17], 我们直接训练网络从在时间步长t采样的带噪音的嵌 入zt,预测无噪音的风格嵌入z。形式上说,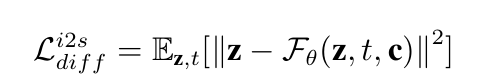
我们应用朴素均方误差(MSE)来评估预测结果。
因此,视觉指导语音风格生成的总体学习目标 可以表述为:
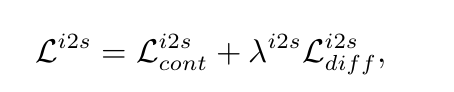
实验与结果
我们在MeadText 数据集上训练了音视频 指导模块和说话人脸指导网络。评估在RAVEDESS 和 MeadText 的测试集上进行。由于这两个数据 集均由RGB视频组成,我们通过Emoca获得重 建结果,并渲染面部网格作为GT视频进行对比。
我们将我们的方法与支持语音条件3D说 话面部生成的最先进基于模板的模型进行 比 较, 包 括MeshTalk, FaceFormer, CodeTalker和EmoTalk。
对MeadText和RAVEDESS的定量结果

定性结果
关于口型合成,我们的研究报告了 MeadText和RAVEDESS的定量结果。值 得注意的是,我们的方法在这两个数据集上的大多 数指标表现出色。然而,与其他方法相比,我们的 方法在口型同步性能方面可能表现较弱,特别是在 LSE-D方面。我们将这种差异部分归因于SyncNet 对中性表情的强烈偏好,它是在主要由无表情 视频预训练的。与这些方法不同,我们的合成结果 包含表情丰富的面部细节,这可能导致较低的评分。此外,我们的方法实现了与这两个数据集上的真实 视频接近的LSE-D得分,表明我们可以稳健地生成 精确的口型同步视频。
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

清华大学等团队如何让AI智能体拥有“记忆力“,从而真正学会自主探索未知世界?
清华大学等机构提出JAMEL框架,通过代码覆盖率信号联合训练AI智能体的潜在记忆模块与探索策略,以极低token消耗实现媲美大型闭源模型的自主探索能力。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

当AI“管家“学会分工协作:卡内基梅隆大学研究团队如何让电脑操作智能体突破单打独斗的瓶颈
卡内基梅隆大学提出MACU框架,让经理AI统筹多个员工AI并行完成复杂电脑操作任务,通过动态调整任务图,在四个基准上均超越单智能体。
2024
02/29
17:04
分享
点赞

