
7000万高质量视频文本对!文生视频最大的开源数据集Panda-70M来了!
数源AI 最新论文解读系列

论文名:Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
论文链接:https://arxiv.org/pdf/2402.19479.pdf

引言
我们进入了一个计算和数据规模对于大规模多模 态学习至关重要的时代。大多数突破是通过大规模计 算基础设施、大规模模型和大规模数据实现的。由于 这些组成部分,我们拥有强大的文本到图像(text-to image)和图像到文本(image-to-text) 模型。增加模型大小或计算量具有挑战 性且昂贵;然而,这需要有限的工程时间。扩展数据 相对更具挑战性,因为需要人类分析每个样本所需的 时间更长。
简介
因此,为了建立具有高质量字幕的视频数据集,我们提出了一种自动方法,利用多模态输入,如文本视频描述、字幕和单独的视频帧。具体来说,我们从公开可用的高清视频语料库HD-VILA-100M中策划了380万个高分辨率视频。然后,我们将它们分割成语义一致的视频片段,并应用多个跨模态教师模型为每个视频获取字幕。接下来,我们在一个小子集上微调一个检索模型,手动选择每个视频的最佳字幕,然后在整个数据集中使用该模型选择最佳字幕作为标注。通过这种方式,我 们获得了配有高质量文本字幕的7000万个视频。我们将该数据集称为Panda-70M。我们展示了提出的数据集在三个下游任务上的价值:视频字幕生成、视频和文本检索以及文本驱动的视频生成。在所有任务中,基于提出的数据训练的模型在大多数指标上得分明显更好。
方法与模型
为构建Panda-70M,我们利用了从HD-VILA-100M 收集的3.8M高分辨率长视频。然后,我们按照第 3.1节中描述的方法将它们分割成70.8M语义连贯的片段。第 3.2节展示了如何使用多个跨模态教师模型生成一组候选字幕注释。接下来,我们微调一个细粒度检索模型,以选择最准确的字幕,详细内容请参见第3.3节。最后,在第 3.4节中,我们描述了使用Panda- 70M训练学生字幕模型的方法。我们方法的高层视图如图 2所示。
1
Semantics-aware Video Splitting
视频字幕数据集中的理想视频样本应具有两种有 些矛盾的特征。一方面,视频应在语义上保持一致, 这样视频样本才能更好地为下游任务(如动作识别) 带来益处,字幕也能更准确地表达其语义内容而不含糊。另一方面,视频不能太短或碎片化,以包含有意义的运动内容,这对于视频生成等任务是有益的。
为了实现这两个目标,我们设计了一个两阶段的 语义感知分割算法来将长视频切分为语义连贯的片段。在第一阶段,我们基于镜头边界检测 [1] 来分割视频, 因为当一个新场景开始时,语义通常会发生变化。在 第二阶段,如果相邻片段被第一阶段错误分开,我们会将它们拼接在一起,确保视频不会变得太短。为此, 我们使用 ImageBind来提取视频帧的嵌入,并在 两个片段的帧嵌入相似时合并相邻片段。我们还实施 了额外的程序来处理:1)没有切换场景的长视频,2) 使用复杂转场效果的视频,如淡入和淡出效果,通常 不会被检测为切换场景,以及 3)去除冗余片段以增 加数据集的多样性。有关分割算法的更多细节请参见附录 A。值得注意的是,虽然我们的数据集侧重于具 有一致语义的细粒度视频文本对,用户仍可以通过连 接连续片段和字幕来获取具有多个切换场景的长视频, 因为这些片段是从同一长视频中切分出来的。
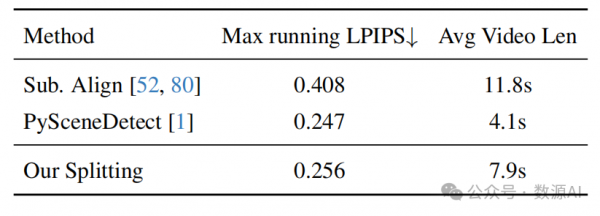
为了定量验证视频片段的语义一致性,我们引入 了最大运行 LPIPS,它突出显示视频片段内最显著的感 知变化。形式上,给定一个 n 秒的视频片段,我们每秒 对视频帧进行子采样,并将关键帧表示为 。最大运行 LPIPS 的公式如下: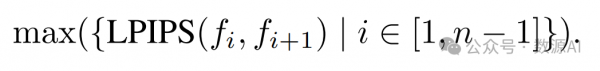
其中,LPIPS(·, ·)是两幅图像的感知相似度 [89]。如表 2 所示,我们的分割方法在保持比基于字幕句子对齐更 好的语义一致性的同时,比基于普通镜头边界检测保 持了更长的视频长度 [1, 52, 80]。
2
Captioning with Cross-Modality Teachers
视频中包含丰富的多模态信息,有利于字幕生成 [80]。具体来说,除了视频本身,还有一些有用的文本 (例如,视频标题、描述和字幕)和图像(例如,单独 的视频帧)。基于这一观察,我们提出使用几个具有不 同模态输入的字幕生成模型。我们从包含31个字幕生成模型的大型池开始。模 型池的介绍在附录 B.1 中。由于在70M视频片段上运行所有模型的推断是计算密集的,我们根据用户研究 构建了一个性能良好的八个模型的简短列表。该列表 显示在图 3 的y轴上。有关此过程的更多细节在附录 B.3 中。简而言之,这些模型由五个具有不同预训练 权重和输入信息的基础模型组成。这五个基础模型 包括 Video-LLaMA [88](视频VQA)、VideoChat(视频VQA)、VideoChat Text(将视频内容文本化 的自然语言模型)、BLIP-2(图像字幕生成)和 MiniGPT-4(图像VQA)。为了通过跨模态教师模 型实现视频字幕生成,我们针对每种模态制定了不同 的字幕生成过程。例如,对于VQA模型,除了视觉数 据,我们还输入一个包含额外文本信息的提示,并要 求模型将所有多模态输入总结为一句话。 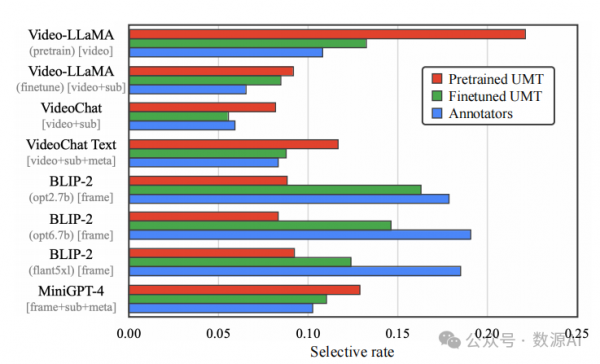
我们假设使用不同模态数据的教师模型在不同类 型的视频上表现良好。例如,由于具有处理时间信息 的额外模块,视频模型可以在具有复杂动态的视频上 表现更好。另一方面,由于它们是使用大规模图像-文 本配对数据集进行训练的,图像模型可以准确地为具 有罕见和不常见对象的视频生成字幕。最后,对 于视觉难以理解的视频,VQA模型具有优势,因为它 们可以利用额外的文本线索。
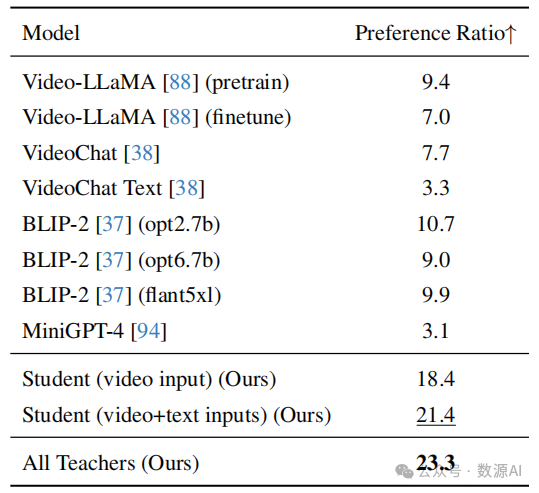
这一假设可以通过数值评估得到支持。具体来说, 我们进行了一个用户研究,要求参与者从八个候选项 中选择最佳字幕。我们在图 3 中绘制了每个教师模型 的选择率(蓝色柱形图)。结果显示,最佳字幕由不同 的教师模型生成。此外,单个教师模型的最高选择率 (即,BLIP-2 with opt6.7b [90])仅为17.85%。这一事实 表明单个模型在各种视频上的字幕生成能力有限。
3
Fine-grained Video-to-Text Retrieval
给定一个视频的多个候选字幕,我们寻找与视频 内容最匹配的字幕。一个直观的想法是使用现有的通 用视频到文本检索模型来选择这样一个字幕。不幸的是,我们发现它们通常无法选择最佳结果。一 个原因是通用模型是使用对比学习目标 进行训练的,并学会区分一个样本与其他完全不相关的样本1。相比之下,在我们的情况下,所有候选字幕与视频样本高度相关,并要求模型在每个字幕中识别微小差异以实现最佳性能。
为了将检索模型定制到我们的“细粒度”检索场 景,我们收集了一个包含 100K 个视频的子集,其中人类注释员选择包含有关视频主要内容最正确和详细 信息的字幕。然后我们在这个数据集上对 Unmasked Teacher(UMT) 进行微调。我们对对比损失实施了硬负采样,其中注释员未选择的七个字幕组成 了硬负样本,并被分配了更大的训练权重。
我们在验证集上定量评估了 UMT 在进行微调和未 进行微调时的检索性能。实验表明,经过微调的 UMT 可以达到 35.90% 的 R@1 准确率,明显优于预训练的 UMT,其 R@1 为 21.82%。值得注意的是,我们进行 了人类一致性评估,要求另外两个人重新执行注释, 并将结果与原始注释进行比较。平均人类一致性得分 仅为 44.9% 的 R@1,表明当有多个同样优秀的字幕时, 任务是主观的。或者,如果我们将三个人中任何一个 选择的字幕视为好的字幕(即,一个视频可能有多个 好的字幕),UMT 可以达到 78.9% 的 R@1。此外,在 图 3 中,我们展示了经过微调的 UMT(绿色柱)可以 选择与人类选择的字幕分布类似的字幕(蓝色柱)。
4
Fine-grained Video-to-Text Retrieval
尽管上述字幕生成流程可以生成有希望的字幕, 但庞大的计算需求阻碍了其扩展数据集规模的能力。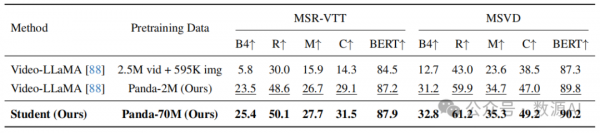
Zero-shot video captioning (%)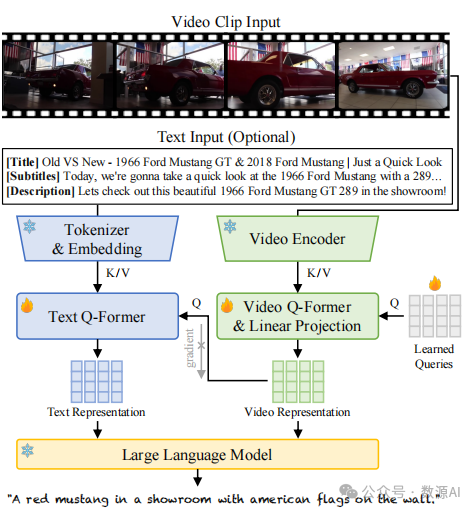
Architecture of student captioning model
事实上,需要运行 8 + 1 个不同的模型来注释单个视频片段。为了解决这个问题,我们在 Panda-70M 上学习了一个学生字幕模型,以从多个教师模型中提炼知识。
如图 4 所示,学生模型包括视觉和文本分支,利 用多模态输入。对于视觉分支,我们使用与 VideoLLaMA 相同的架构来提取与 LLM 兼容的视频表示。对于文本分支,一个直接的设计是将文本嵌入直接输入到 LLM 中。然而,这将导致两个问题:首先, 视频描述和字幕的文本提示可能过长,主导了 LLM 的 决策并且增加了沉重的计算负担;其次,描述和字幕 中的信息通常是嘈杂的,且与视频内容不必对齐。为了解决这个问题,我们添加了一个文本 Q-former 来提取具有固定长度的文本表示,并更好地连接视频和文本表示。Q-former 的架构与 BLIP-2 中的 Query Transformer 相同。在训练过程中,我们阻止文本分支到 视觉分支的梯度传播,并仅基于视频输入训练视觉编 码器。有关学生模型的架构和训练的更多细节请参见附录 D。
 Comparison of the teacher(s) and student captioning models (%)
Comparison of the teacher(s) and student captioning models (%)
实验与结果
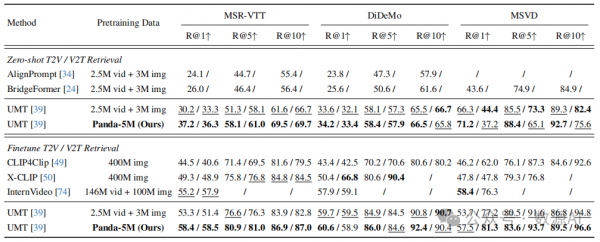
我们在附录 E 中展示了 Panda-70M 的样本。为了 定量评估 Panda-70M 的有效性,我们在三个下游应用 中测试了其预训练性能:视频字幕生成(视频字幕生成)在第 4.1 节,视频和文本检索(视频和文本检索) 在第 4.2 节,视频生成(视频生成)在第 4.3 节。下游模型的训练细节遵循官方代码库,除非另有明确说明。
Video and text retrieval (%)
Qualitative comparison of video captioning

Zero-shot text-to-video generation
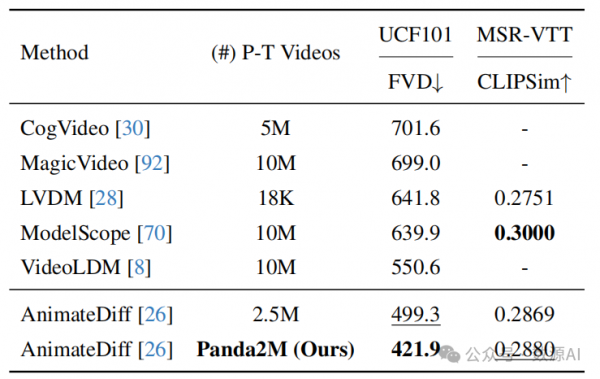
Qualitative results of text-to-video generation

来源:数源AI
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

浙江大学团队研发:AI机器人能否像人一样“找准角度“拍出同款照片?
浙江大学团队提出目标视角复现任务(TVR),测试AI主动导航至指定视角的能力,最强模型成功率仅12%,人类达93%,并验证了视觉示范学习与多轮强化学习的提升路径。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

香港城市大学与快手团队联手:让AI“导演“教会视频生成模型真正“思考“
这项研究提出"VLM即教师"框架,让视觉语言模型在视频生成推理时充当实时监考官,通过可微分奖励信号在线优化轻量LoRA模块,平均提升视频推理性能16.7分。
2024
03/05
17:04
分享
点赞

