
文本+图片生成高保真视频,阿里推出视频模型AtomoVideo
阿里巴巴集团的技术团队推出了文本+图片生成高保真视频模型——AtomoVideo。
用户通过AtomoVideo只需要提供高清图片和简单的文本提示,就能快速生成高清视频并保留逼真的细节。
根据评测数据显示,AtomoVideo生成的视频在动作连贯性、图片一致性、时序一致性、运动强度等方面超过了VideoCrafter、I2VGEN-XL、SVD开源模型,可媲美商业模型Gen-2和Pika。
论文地址:https://arxiv.org/abs/2403.01800
项目地址:https://atomo-video.github.io/

AtomoVideo架构简单介绍
AtomoVideo使用了预训练的Stable Diffusion 1.5作为基础模型,并在每个空间卷积和注意力层之后新增了1D时序卷积和时序注意力模块。
AtomoVideo的技术创新在于融合了多粒度图片注入和时间建模,可将输入图片经过 VAE 编码器处理后,获得了细粒度的图片潜在表征,再与高斯噪声拼接在一起作为 UNet 的输入。
AtomoVideo还利用 CLIP 编码器对输入图片进行了高层语义表征,并通过交叉注意力注入到 UNet 中。这种巧妙设计使得模型能同时捕捉到图片的细节信息和文本语义提示,从而提高生成视频与原始图片的一致性。

AtomoVideo还在时间维度上进行了技术创新,在 UNet 的每一个空间卷积和注意力层之后,都增加了一维时间卷积和时间注意力模块,从而赋予了模型学习时序动态模式的能力。
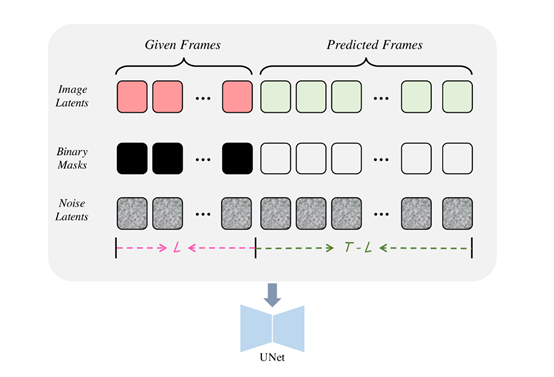
功能方面除了图片生成视频,AtomoVideo还可用于其他视频相关任务。例如,给定视频的前几帧,AtomoVideo可对剩余未知帧进行视频扩展预测,为视频添加无缝延续的新内容;
可基于上下文帧,自动修复受损帧或插值缺失帧,自动修复损坏的视频。
AtomoVideo训练策略
训练数据方面,AtomoVideo使用了包含1500万条视频,每条长度在10-30秒左右以及视频的文本描述也被输入到模型中。
在训练阶段,研究人员使用了零终端信噪比和v-预测等策略,显著提升了生成视频的稳定性,无需依赖于噪声先验。
传统上在生成模型中,使用的是正常的信噪比,输入图像与生成结果之间的比较。但这种信噪比的计算方式可能会导致生成过程不稳定。
而零终端信噪比是一种在生成过程中使用的评估指标,将生成图像与最终期望的目标图像之间的差异作为噪声信号。
在训练过程中,通过最小化零终端信噪比来优化模型,以提高生成视频的稳定性和质量,并且对生成的细节和一致性有更好的控制。

此外,还固定了预训练的文本到图片模型的权重,仅训练新添加的时序层和输入层参数,这使得AtomoVideo可以无缝集成到目前流行的个性化文生图模型、可控生成模型等,进一步扩展了其应用场景。
AtomoVideo实验数据
为了评估AtomoVideo的性能,研究人员在AIGCBench测试集上与VideoCrafter、I2VGEN-XL、SVD等开源模型,以及Pika、Gen-2等商业模型进行了深度比较。
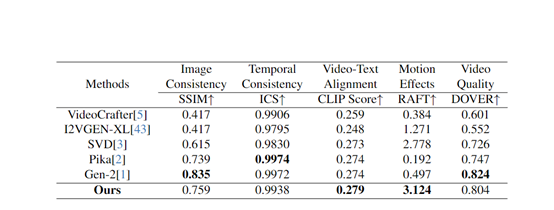
实验结果显示,相比其他方法,AtomoVideo在图片一致性、时间连贯性、运动强度和视频质量等多个评估维度上表现卓越,尤其在保持较大运动强度的同时实现了优异的时间稳定性。
来源:AIGC开放社区
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

香港大学与字节跳动联手:教机器人“看“人类动作来学习新技能,只需去掉那些令人头疼的旋转信息
香港大学与字节跳动研究团队提出"桥接动作"概念,通过只学习人类手腕的平移轨迹(丢弃噪声大且易误导机器人的旋转信息),实现从人类操作视频向双臂机器人的高效技能迁移。


清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。
2024
03/11
22:04
分享
点赞

