
马斯克打脸OpenAI,全球最大巨无霸模型Grok-1开源!3140亿参数8个MoE,GitHub狂揽6k星

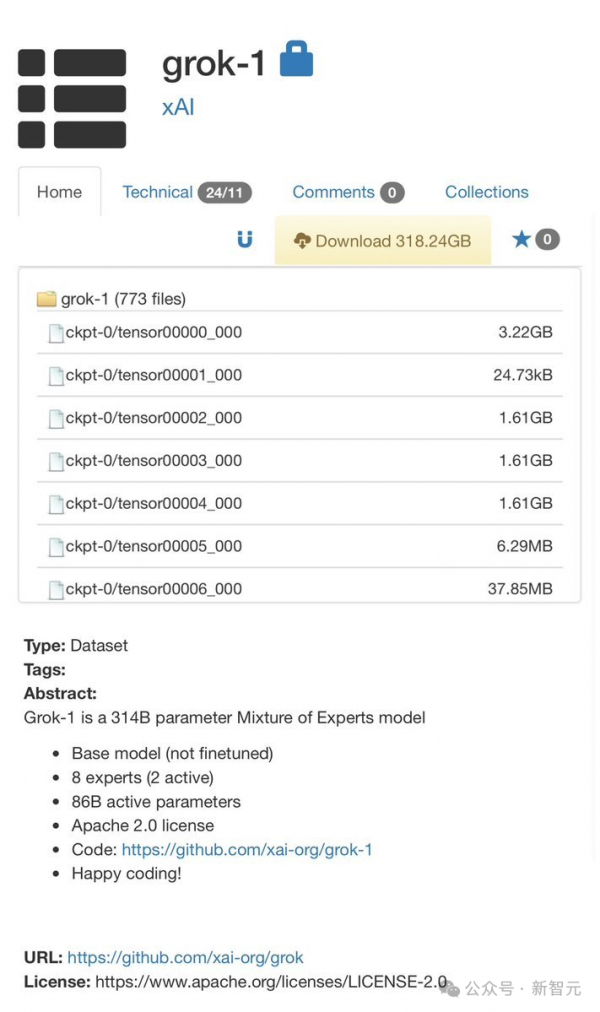
就在刚刚,xAI正式发布3140亿参数混合专家模型Grok-1的权重和架构。

3140亿的参数,让Grok-1成为迄今参数量最大的开源LLM,是Llama 2的4倍。

目前,xAI关于Grok-1没有透露更多信息。
官网放出的信息如下——
- 基础模型在大量文本数据上训练,未针对任何特定任务进行微调。
- 314B参数的MoE,有25%的权重在给定token上处于激活状态。
- 2023年10月,xAI使用JAX和Rust之上的自定义训练堆栈从头开始训练。
一经上线GitHub,Grok就狂揽了6k星,586个Fork。
项目地址:https://github.com/xai-org/grok-1
马斯克还不忘嘲讽OpenAI一番,「告诉我们更多关于OpenAI的「open」部分...」

纽约时报点评道,开源Gork背后的原始代码,是这个世界上最富有的人控制AI未来战斗的升级。

开源究竟会让技术更安全,还是会让它更滥用?
「开源支持者」马斯克,以身作则地卷入了AI界的这场激烈辩论,并用行动给出了答案。
小扎刚刚也对Grok做出了评价,「并没有给人留下真正深刻的印象,3140亿参数太多了,你需要一堆H100,不过我已经买下了」。

一条磁力链,全球首个最大模型开源
pip install -r requirements.txtpython run.py
这个脚本会在测试输入上,加载checkpoint和模型中的样本。
magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce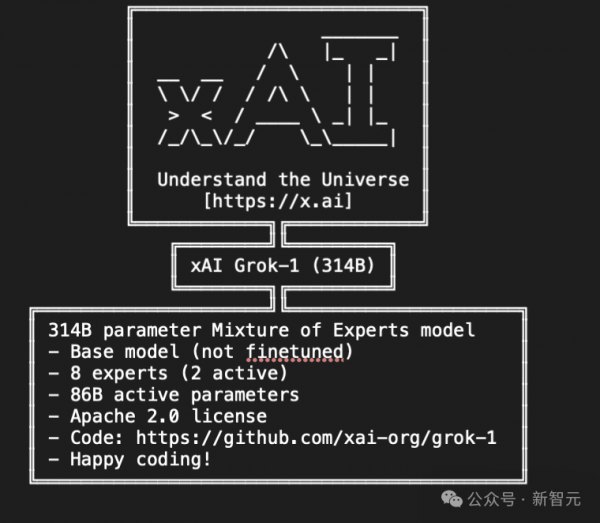

更多细节
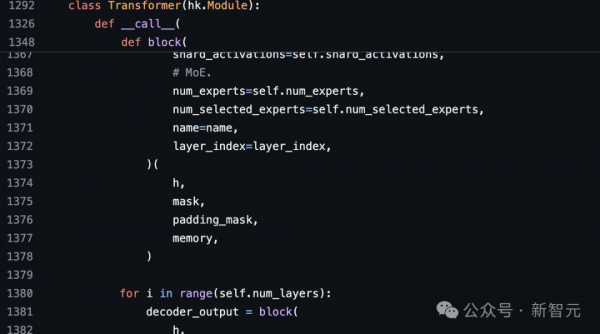
- tokenizer词汇量:131,072(于GPT-4类似)相当于2^17
- 嵌入大小:6144(48*128)
- Transformer层:64(每一层都有一个解码层:多头注意块和密度块)
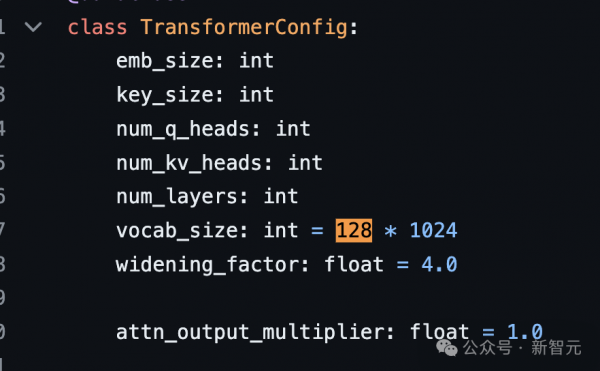
密集块(密集前馈块):
- 宽度因子(Widening Factor):8
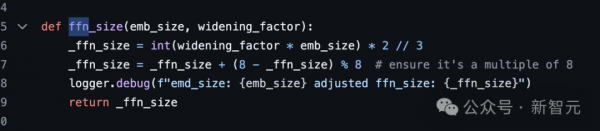
- 上下文长度:8192个token

网友:开源争霸战要来
AI社区已经沸腾了!
技术界指出,Grok的亮点是在前向反馈层中使用了GeGLU以及归一化方法,并且使用了有趣的三明治范式技术(sandwich norm technique)。
连OpenAI的员工,都表示了自己对Grok的强烈兴趣。





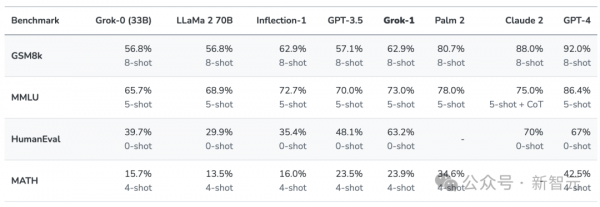
第一代Grok已超越Llama-2-70B
马斯克为何选择开源?
在数次嘲讽OpenAI是「CloseAI」之后,马斯克果真选择了开源自家大模型。


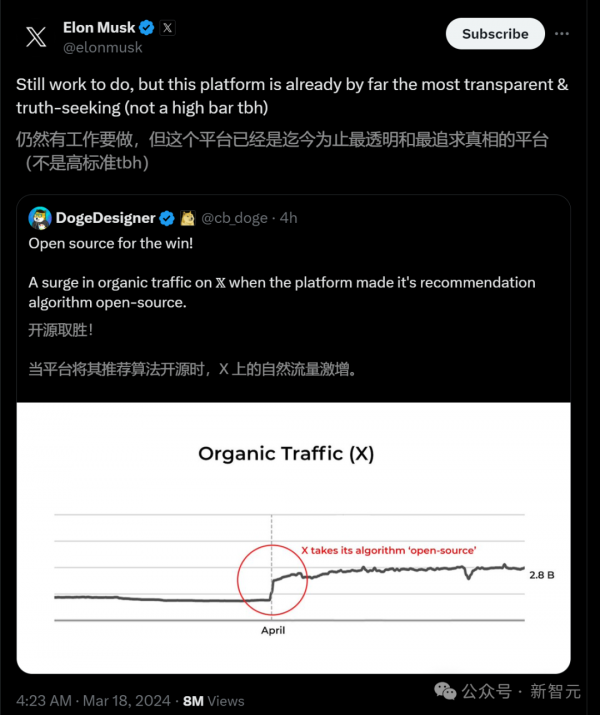

好文章,需要你的鼓励


旧笔记本、台式机与打印机该如何正确回收处理
许多人将旧电子设备堆放在储藏室或车库中,而非妥善处置。实际上,回收旧电脑和打印机既简单又通常免费。Best Buy、Staples等大型零售商均提供免费电子废品回收服务,每日可接收多台设备。在回收前,务必通过恢复出厂设置或专业工具彻底清除个人数据。如无零售店,可通过Earth911或消费技术协会的在线工具查找附近的回收中心。

三一学院与华为研究院联手出招:AI大模型“智能分诊“系统,省钱又省时
三一学院与华为联合提出两阶段AI模型调度框架:先按语义聚类分配最优模型,再用轻量分类器拦截低质回答升级处理,在保留97-99%最强模型准确率的同时显著降低推理延迟。

美国NRC提出核废料处置新规,为长期搁置问题开辟出路
美国核管理委员会(NRC)近期提出对第61部分法规进行全面修订,首次为"超C类"(GTCC)低放射性核废料建立明确的许可处置路径。现有框架要求将其送入从未建成的深层地质处置库,形成"监管死胡同"。新规拟采用基于风险的分析方法,按废料实际放射性危害而非来源确定处置方式,约80%的GTCC废料或可适用近地表处置。这些废料目前分散存放于反应堆、医院及工业设施,新规将为其提供集中处置的可行路径。

当AI团队“各自为政“时,伊利诺伊大学如何用“梯度指纹“找出问题根源?
多智能体AI系统常因无法精准定位错误来源而难以优化,GBC通过梯度计算为每个AI的输出建立影响力评分,实现跨智能体的精细归因与针对性提示词优化。
2024
03/19
17:04
分享
点赞

