
Cohere发布RAG增强版大模型并开源权重,支持中文、1040亿参数
4月5日,知名类ChatGPT平台Cohere在官网发布了全新模型——Command R+。
据悉,Command R+有1040亿参数,支持英语、中文、法语、德语等10种语言。最大特色之一是,Command R+对内置的RAG(检索增强生成)进行了全面强化,其性能仅次于GPT-4 tubro,高于市面上多数开源模型。
目前,Cohere已经开源了Command R+的权重,但只能用于学术研究无法商业化。想商业应用,用户可以通过微软Azure云使用该模型或者Cohere提供的API。
huggingface地址:https://huggingface.co/CohereForAI/c4ai-command-r-plus
量化版:https://huggingface.co/CohereForAI/c4ai-command-r-plus-4bit

强化版RAG
Cohere联合创始人兼Transformer作者之一的Aidan Gomez表示,RAG作为目前大模型厂商必备模块之一,Command R+对该功能进行了深度强化,在提升生成内容的准确的同时,极大减少了模型的“幻觉”。
根据其发布的性能测试数据显示,在多语言、RAG、工具使用三大模块,Command R+的性能基本与GPT-4 turo差不多,大幅度超过知名开源模型Mistral。
由于Command R+内置了一个高级分词器,对非英语文本的压缩效果比市面上其他模型好得多能够实现高达 57% 的成本降低。
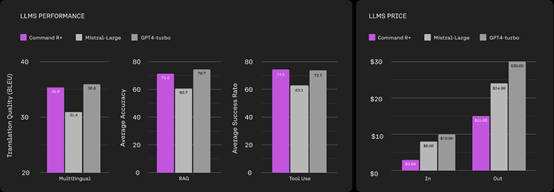
所以,在大模型输入方面成本只有GPT-4 turo的三分之一,输出只有其二分之一,可以帮助企业节省大量资金。
Command R+另外一个特色就是支持与企业平台相结合,实现业务流程自动化。Gomez认为,大模型不仅能够生成各种文本等内容,对于企业来说就像“发动机”一样,能充当核心推理引擎来实现复杂业务流程的自动化(和RPA机器人差不多)。
Command R+可以与企业的CRM、ERP、HR等不同类型的软件相结合使用,例如,可以将大模型内置在CRM平台中,帮助企业自动记录、管理客户关系、活动以及更新日志等。
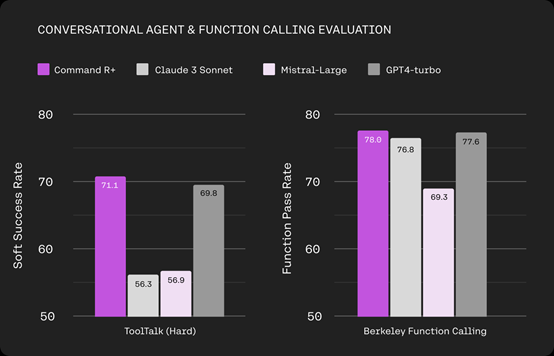
这也就是说,Command R+不仅仅是一个能生成内容的模型,更多的是可以帮助自动执行多场景复杂业务的智能AI代理(和AutoGPT差不多)。
此外,当Command R+在执行任务的过程中发生错误时,可以进行自我纠错,然后记住错误避免下次遭遇相同的情况。
什么是RAG
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和生成的技术,主要为大型语言模型提供外部知识源,以便生成更准确、更丰富的回答或内容,并减少模型的幻觉问。
尤其是在需要广泛背景知识来生成响应的任务中,例如,问答、文本摘要和拟人对话等。
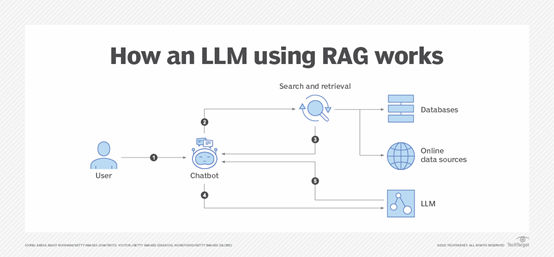
RAG的主要架构包括检索器、生成器和融合机制三大块。
检索器:检索器的作用是在给定输入(例如,一个自然文本提问)时,从一个大规模的文档集合中快速检索出相关的文档或信息片段。常用的检索方法包括基于向量空间模型的方法包括BM25、Dense Passage Retrieval等。
生成器:生成器通常是一个预训练模型,例如,GPT-4、Command R+等。它使用检索到的文档作为额外的上下文信息,生成与输入相关的回答或文本。
融合机制:在检索到的文档和原始输入之间建立联系的机制。它决定了如何将检索到的信息整合到生成过程中,以提高生成文本的相关性和准确性。
可以通过不同的方式实现,包括直接将检索结果作为生成器的一部分输入,或使用更复杂的注意力机制来动态选取最相关的信息。
所以,大模型在使用了RAG功能后,可以访问比预训练模型训练时期更广泛、更具时效性的知识,提高生成内容的相关性和准确性。
尤其是对于一些需要特定知识背景的任务,大模型直接生成响应需要耗费巨大AI算力。而RAG通过检索引入的背景知识,可以显著减少算力需求。
好文章,需要你的鼓励


OpenAI发布ChatGPT Work平台并扩大GPT-5.6部署范围
OpenAI推出企业级智能体平台ChatGPT Work,可跨应用自动执行多步骤工作任务,生成文档、演示文稿及电子表格等业务内容。同步推出的GPT-5.6系列模型涵盖Sol、Terra、Luna三档,主打"更低成本、更强性能"。Sol在编码、网络安全及复杂推理基准测试中表现突出,定价为每百万输入tokens 5美元。新模型还支持Microsoft 365、Google Drive等企业应用集成,并引入max与ultra两种推理模式以应对复杂工作负载。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

DJI发布AP100降落伞,为Matrice 400无人机提供紧急安全保障
大疆发布AP100降落伞,专为旗舰级Matrice 400企业无人机设计。该配件重约935克,支持自动与手动两种部署方式,可在600毫秒内触发展开,将无人机下降速度控制在每秒5米以内。AP100作为独立安全模块运行,配备独立飞控、传感器及备用电容,断电后仍可持续工作一小时。此外,内置飞行终止系统可在展开前切断电机,防止螺旋桨缠绕。该配件还支持欧盟EASA和英国CAA的C5/C6等级合规认证,适用于超视距飞行任务,防护等级IP55,适应-20°C至50°C宽温环境。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2024
04/07
20:04
分享
点赞

