
一秒钟实现移动图像中任何物体!Meta提出新的分层可控文生图模型!
数源AI 最新论文解读系列

论文名:Move Anything with Layered Scene Diffusion
论文链接:https://arxiv.org/pdf/2404.07178.pdf

引言
可控场景生成(即生成具有可重新排列布局的图 像的任务)是生成建模的一个重要课题 [16, 34],其应 用范围包括社交媒体平台的内容生成和编辑,以及互 动式室内设计和视频游戏。
在 GAN 时代,潜空间 [14, 21, 32, 39] 被设计用于 对生成的场景进行中级别的控制。这些潜空间以无监 督的方式优化,在场景布局和外观之间提供分离。例 如,BlobGAN [14] 使用一组溅墨图形来控制 2D 布局, 而 GIRAFFE [21] 则使用组合神经领域来控制 3D 布局。虽然这些方法可以很好地控制场景布局,但生成的图像质量仍然有限。
简介
在本文中,我们提出 **SceneDiffusion** 在扩散采样过程中优化分层场景表示。我们的 主要见解是可以通过在不同空间布局下对场景渲染进 行联合去噪来实现空间分离。我们生成的场景支持各 种空间编辑操作,包括移动、调整大小、克隆以及分 层外观编辑操作,例如对象重新造型和替换。此外, 可以根据参考图像生成场景,从而实现野生图像中的对象移动。值得注意的是,该方法无需训练,与一般文本到图像扩散模型兼容,响应时间不到一秒。
方法与模型
框架概述。我们的框架概览如 Figure 2 所示。在 Section 3.1 中,我们简要介绍了关于扩散模型和局部条 件扩散的初步工作。然后在 Section 3.2 中,我们介绍 了如何通过 SceneDiffusion 获取空间分离的层状场景。最后在 Section 3.3 中,我们讨论了 SceneDiffusion 如何 实现对真实场景图像的空间编辑。
1
Preliminary
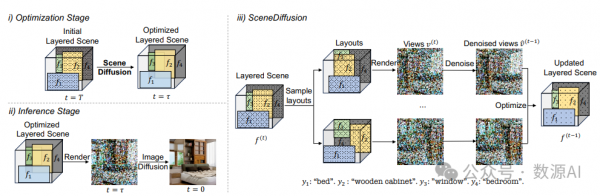
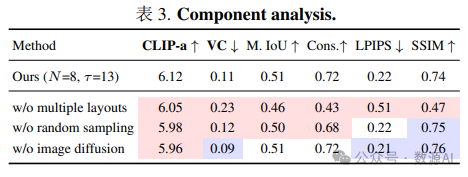
我们的框架分为两个阶段:(i)优化阶段,我们使用 SceneDiffusion 对分层场景表示形式进行优化 T – τ 个扩 散步骤,以及 (ii)推理阶段,我们使用 τ 步标准图像扩散来渲染优化的分层场景。(iii)SceneDiffusion 通过并行去噪多个 随机采样的布局来更新分层场景。在这个示意图中,场景由 4 层组成。每一层由一个特征图 f、一个掩码 m(显示为矩形)和 一个文本提示 y(显示在底部)组成。在去噪步骤 t 中,我们随机采样 N 个布局并渲染它们以获得不同的视图 v (t)。然后,我 们使用预训练的 T2I 扩散模型对视图进行一步去噪,以获得 v^ (t–1),并将其用于更新分层场景中的特征图 f (t) → f (t–1)。需要 注意的是,这里矩形仅作为对象的粗略几何形状(类似于 Epstein et al. [9] 中的blob),可以替换为更准确的掩码。
扩散模型(Diffusion Models)。扩散模型 [15, 42] 是 一种生成式模型(generative model),它学习从随机输 入噪声中生成数据。更具体地说,给定来自数据分布 x0 ~ p(x0) 的一个图像,一个 固定 的正向噪声过程 (forward noising process)会逐步向数据添加随机高斯 噪声,从而创建一个随机隐变量 x1, x2, ..., xT 的马尔 可夫链(Markov Chain):
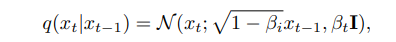
其中 β1, ...βT 是与所选择的噪声计划对应的常数,假 设扩散步骤足够多,则 xT 为标准高斯白噪声。然后我 们训练一个去噪器 θ 来学习反过程,即如何从噪声输 入中去除噪声 [15]。在推理时,我们可以从随机标准 高斯噪声 xT ~ N (0; I) 开始对图像进行采样,并根据 马尔可夫链(Markov Chain)迭代地对图像去噪,即连 续从 pθ(xt–1|xt) 中对 xt–1 进行采样,直到 x0:
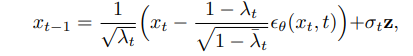
其中 z ~ N (0, I),λ? t = Qt s=1 λs,λt = 1 – βt,σt 是 噪声尺度。**局 部 条 件 扩 散 (Locally Conditioned Diffusion)**:已 有 多 种 方 法 [bar2023multidiffusiopo2023compositional] 被 提 出 来, 基 于 局 部 文 本 提 示使用预训练的文本到图像 (T2I) 扩散模型生成部分图 像内容。对于 K 个局部提示 y = 和二 进制非重叠掩码 m = ,局部条件扩散 [po2023compositional] 提出首先为每个局部提示 yk 使 用无分类器指导 [ho2022classifier] 预测完整的图像噪声 εθ(xt, t, yk),然后将其分配给相应的区域,该区域由 mk 掩码。
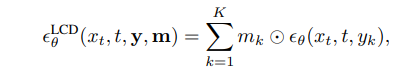
其中 ⊙ 是元素级乘法。
2
Generating Scenes with SceneDiffusion
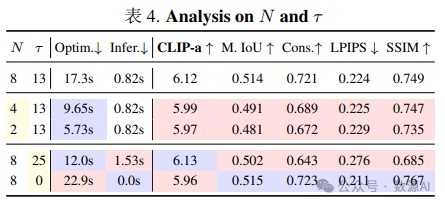
我们提出了一种名为 分层场景扩散 [Layered Scene Diffusion] 的方法,用于从高斯噪声优化分层场景中的 特征图。分层场景扩散的每个步骤 1) 从随机采样的 布局渲染多个视图,2) 从视图中估计噪声,然后 3) 更新特征图。具体来说,分层场景扩散从 [0; μk] × [0; νk] 运动范 围中采样 N 组偏移量 [o1,n, o2,n, · · · , oK,n] N n=1,其中 每个偏移量 ok,n 是该范围内的元素。这会产生 N 种 布局变体。布局数量越多有助于去噪器找到更好的模 式,但也增加了计算成本,如 Section 4.2 所示。从 K 个潜在特征图中,我们将布局渲染为 N 个视图 vn ∈ :
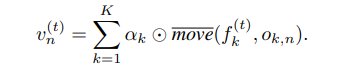
然后, 我们在每个 SceneDiffusion 步骤中堆叠所有 视图,并使用 Equation 3 中描述的使用局部条件扩 散 (locally conditioned diffusion) [33] 来预测噪声 N n=1:
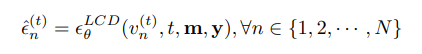
其中 m 是对象掩码,y 是每个图层的局部文本提示。由于我们可以并行运行多个布局去噪,计算 N n=1 几乎不会增加时间开销,但会额外消耗与 N 成比例的 内存。然后我们使用 Equation 2 從估计的噪声 ε^ (t) n 更 新视图 v (t) n 以得到 v^ (t–1) n 。由于每个视图对应于一个 不同的布局并独立地进行去噪,因此在重叠的掩码区 域可能会发生冲突。因此,我们需要优化每个特征图 f (t–1) k ,使从 Equation 5 渲染得到的视图与去噪后的视 图接近。
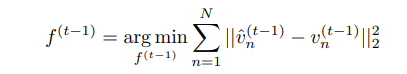
This least square problem has the following closed-form solution:
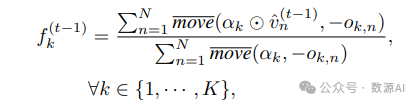
其中 move(x, –o) 表示 x 中沿 o 的反方向平移后的值。该解的推导过程与 Bar-Tal et al. [1] 中的讨论类似。该 解本质上将 f (t–1) k 设置为裁剪后去噪视图的加权平均 值。
3
Neural Rendering with Image Diffusion
我们在运行 SceneDiffusion T – τ 步后,改为运行 原始图像扩散 τ 步。由于层掩码 m(如边界框)仅作 为一种粗略的中级表示形式,而不是准确的几何形状, 因此可以将该图像扩散阶段视为一种 神经渲染器,它 将中间控制映射到图像空间 [9, 30, 49]。τ 的值是在图 像质量和对层掩码的忠实度之间进行权衡。τ 值设置为 总扩散步长的 25% 到 50% 可以取得最佳效果,这通常 使用流行的 50 步 DDIM 调度程序 [43] 耗时不到一秒。可以单独设置图像扩散阶段使用的全局提示。在本工 作中,我们主要将全局提示设置为按深度顺序连接局 部提示的结果 yglobal =< y1, y2, . . . , yK >,发现这种简 单的策略在大多数情况下都足够有效。
4
Layer Appearance Editing
通过修改本地提示,可以单独编辑每一层的外观。通过将本地提示更改到一个新的提示,然后使用相同 的功能图初始化执行命名扩散,可以对物体进行重新 造型或替换。
4
Application to Image Editing
SceneDiffusion可以通过将其采样轨迹作为*锚*, 以参考图像为条件,从而允许我们改变现有图像的布 局。具体来说,当给定参考图像和现有布局时,我们 将参考图像设置为最终扩散步骤的优化目标,即锚视 图表示为 v^ (0) a 。然后,我们在不同的扩散噪声级别向 该视图添加高斯噪声,在不同的去噪步骤创建一个锚 视图的轨迹。
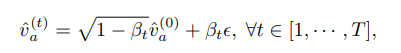
其中 ε ~ N (0, 1). 在每个扩散步骤中,我们使用相应的 锚点视图 v^ (t) a 来进一步约束 f (t–1),这会在 Equation 7 中产生一个额外的加权项:
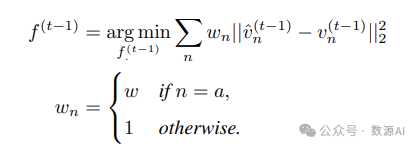
其中 n ∈ ∪ ,w 控制着 v^ (t) a 的重要性。足够大的 w 能够产生对参考图像的良好忠实度,我 们在这项工作中将 w = 104 。此方程的闭形式解与 Equation 8 类似,具体内容见补充材料。
实验与结果
我们从定性和定量的角度来评估我们的算法。对 于定量研究,需要成千上万的数据集来有效地衡量 FID 等指标。但是,为多对象场景提供具有语义意义 的空间编辑配对具有挑战性,特别是当需要考虑对象 之间的遮挡时。因此,我们将定量实验限制在单对象 场景下。多对象场景的定性结果请参见附录。
用于可控场景生成的定量比较
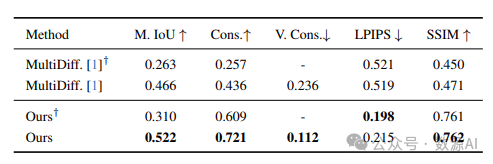
顺序操作

物体移动

【对象移动的量化比较】 +:使用遮罩训练的专业 [in painting (图像修复)] 模型。
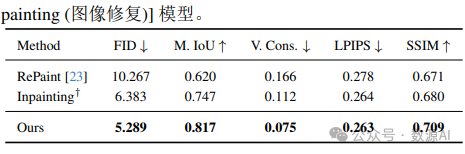
重塑 (Restyling) 对象

替换物体

混合场景

好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2024
04/15
23:04
分享
点赞

