
AI服务器产业链及竞争格局分析
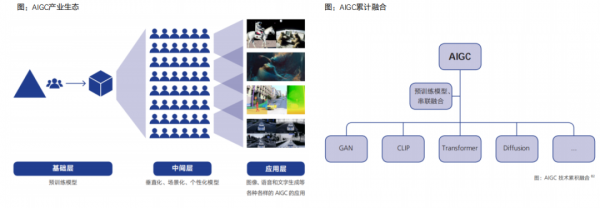
目前,AIGC产业生态体系的雏形已现,呈现为上中下三层架构:①第一层为上游基础层,也就是由预训练模型为基础搭建的AIGC技术基础设施层。②第二层为中间层,即垂直化、场景化、个性化的模型和应用工具。③第三层为应用层,即面向C端用户的文字、图片、音视频等内容生成服务。
根据IDC发布的《2022年第四季度中国服务器市场跟踪报告Prelim》,浪潮份额国内领先,新华三次之,超聚变排行第三,中兴通讯进入前五。
服务器主要硬件包括处理器、内存、芯片组、I/O (RAID卡、网卡、HBA卡) 、硬盘、机箱 (电源、风扇)。以一台普通的服务器生产成本为例,CPU及芯片组大致占比50% 左右,内存大致占比 15% 左右,外部存储大致占比10%左右,其他硬件占比25%左右。

服务器的逻辑架构和普通计算机类似。但是由于需要提供高性能计算,因此在处理能力、稳定性、可靠性、安全性、可扩展性、可管理性等方面要求较高。
逻辑架构中,最重要的部分是CPU和内存。CPU对数据进行逻辑运算,内存进行数据存储管理。
服务器的固件主要包括BIOS或UEFI、BMC、CMOS,OS包括32位和64位。
3、大模型参数量持续提升
GPT模型对比BERT模型、T5模型的参数量有明显提升。GPT-3是目前最大的知名语言模型之一,包含了1750亿(175B)个参数。在GPT-3发布之前,最大的语言模型是微软的Turing NLG模型,大小为170亿(17B)个参数。训练数据量不断加大,对于算力资源需求提升。
回顾GPT的发展,GPT家族与BERT模型都是知名的NLP模型,都基于Transformer技术。GPT,是一种生成式的预训练模型,由OpenAI团队最早发布于2018年,GPT-1只有12个Transformer层,而到了GPT-3,则增加到96层。其中,GPT-1使用无监督预训练与有监督微调相结合的方式,GPT-2与GPT-3则都是纯无监督预训练的方式,GPT-3相比GPT-2的进化主要是数据量、参数量的数量级提升。
4、未来异构计算或成为主流
异构计算(Heterogeneous Computing)是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式,目前主要包括GPU云服务器、FPGA云服务器和弹性加速计算实例EAIS等。让最适合的专用硬件去服务最适合的业务场景。
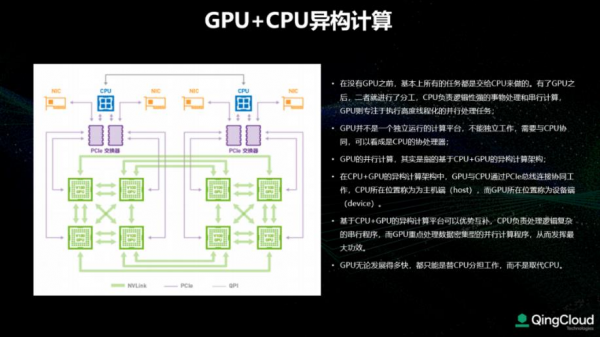
在CPU+GPU的异构计算架构中,GPU与CPU通过PCle总线连接协同工作,CPU所在位置称为主机端 (host),而GPU所在位置称为设备端(device)。基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。
越来越多的AI计算都采用异构计算来实现性能加速。
阿里第一代计算型GPU实例,2017年对外发布GN4,搭载Nvidia M40加速器.,在万兆网络下面向人工智能深度学习场景,相比同时代的CPU服务器性能有近7倍的提升。
5、为什么GPU适用于AI
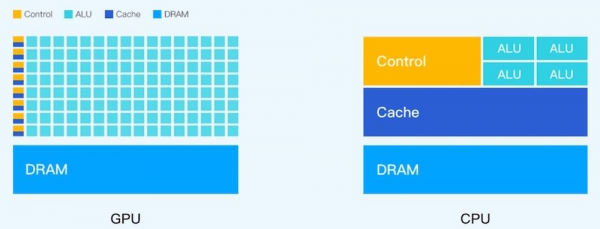
CPU 适用于一系列广泛的工作负载,特别是那些对于延迟和单位内核性能要求较高的工作负载。作为强大的执行引擎,CPU 将它数量相对较少的内核集中用于处理单个任务,并快速将其完成。这使它尤其适合用于处理从串行计算到数据库运行等类型的工作。
GPU 最初是作为专门用于加速特定 3D 渲染任务的 ASIC 开发而成的。随着时间的推移,这些功能固定的引擎变得更加可编程化、更加灵活。尽管图形处理和当下视觉效果越来越真实的顶级游戏仍是 GPU 的主要功能,但同时,它也已经演化为用途更普遍的并行处理器,能够处理越来越多的应用程序。

训练和推理过程所处理的数据量不同。
在AI实现的过程中,训练(Training)和推理(Inference)是必不可少的,其中的区别在于:
训练过程:又称学习过程,是指通过大数据训练出一个复杂的神经网络模型,通过大量数据的训练确定网络中权重和偏置的值,使其能够适应特定的功能。
推理过程:又称判断过程,是指利用训练好的模型,使用新数据推理出各种结论。
简单理解,我们学习知识的过程类似于训练,为了掌握大量的知识,必须读大量的书、专心听老师讲解,课后还要做大量的习题巩固自己对知识的理解,并通过考试来验证学习的结果。分数不同就是学习效果的差别,如果考试没通过则需要继续重新学习,不断提升对知识的掌握程度。而推理,则是应用所学的知识进行判断,比如诊断病人时候应用所学习的医学知识进行判断,做“推理”从而判断出病因。
训练需要密集的计算,通过神经网络算出结果后,如果发现错误或未达到预期,这时这个错误会通过网络层反向传播回来,该网络需要尝试做出新的推测,在每一次尝试中,它都要调整大量的参数,还必须兼顾其它属性。再次做出推测后再次校验,通过一次又一次循环往返,直到其得到“最优”的权重配置,达成预期的正确答案。如今,神经网络复杂度越来越高,一个网络的参数可以达到百万级以上,因此每一次调整都需要进行大量的计算。吴恩达(曾在谷歌和百度任职)举例“训练一个百度的汉语语音识别模型不仅需要4TB的训练数据,而且在整个训练周期中还需要20 exaflops(百亿亿次浮点运算)的算力”,训练是一个消耗巨量算力的怪兽。
推理是利用训练好的模型,使用新数据推理出各种结论,它是借助神经网络模型进行运算,利用输入的新数据“一次性”获得正确结论的过程,他不需要和训练一样需要循环往复的调整参数,因此对算力的需求也会低很多。

推理常用:NVIDIA(R) T4 GPU 为不同的云端工作负载提供加速,其中包括高性能计算、深度学习训练和推理、机器学习、数据分析和图形学。引入革命性的 Turing Tensor Core 技术,使用多精度计算应对不同的工作负载。从 FP32 到 FP16,再到 INT8 和 INT4 的精度,T4 的性能比 CPU 高出 40 倍,实现了性能的重大突破。
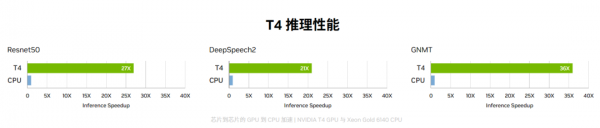
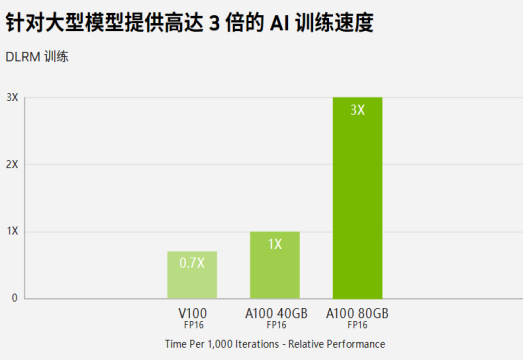
训练:A100和H100。对于具有庞大数据表的超大型模型,A10080GB 可为每个节点提供高达 1.3TB 的统一显存,而且吞吐量比A100 40GB 多高达 3 倍。在 BERT 等先进的对话式 AI 模型上,A100 可将推理吞吐量提升到高达 CPU 的 249 倍。
6、推算ChatGPT带来的服务器需求增量
H100性能更强,与上一代产品相比,H100 的综合技术创新可以将大型语言模型的速度提高 30 倍。根据Nvidia测试结果,H100针对大型模型提供高达 9 倍的 AI 训练速度,超大模型的 AI 推理性能提升高达 30 倍。
在数据中心级部署 H100 GPU 可提供出色的性能,并使所有研究人员均能轻松使用新一代百亿亿次级 (Exascale)高性能计算 (HPC) 和万亿参数的 AI。
H100 还采用 DPX 指令,其性能比 NVIDIA A100 Tensor Core GPU 高 7 倍,在动态编程算法(例如,用于DNA 序列比对 Smith-Waterman)上比仅使用传统双路 CPU 的服务器快 40 倍。
假设应用H100服务器进行训练,该服务器AI算力性能为32 PFLOPS,最大功率为10.2 kw,则我们测算训练阶段需要服务器数量=训练阶段算力需求÷服务器AI算力性能=4.625×107台(同时工作1秒),即535台服务器工作1日。
根据天翼智库,GPT-3模型参数约1750亿个,预训练数据量为45 TB,折合成训练集约为3000亿tokens。按照有效算力比率21.3%来计算,训练阶段实际算力需求为1.48×109 PFLOPS。
对AI服务器训练阶段需求进行敏感性分析,两个变化参数:①同时并行训练的大模型数量、②单个模型要求训练完成的时间。
按照A100服务器5 PFLOPs,H100服务器32 PFLOPs来进行计算。
若不同厂商需要训练10个大模型,1天内完成,则需要A100服务器34233台,需要H100服务器5349台。
此外,若后续GPT模型参数迭代向上提升(GPT-4参数量可能对比GPT-3倍数级增长),则我们测算所需AI服务器数量进一步增长。
7、AI服务器市场规模预计将高速增长
AI服务器作为算力基础设备,其需求有望受益于AI时代下对于算力不断提升的需求而快速增长。
根据TrendForce,截至2022年为止,预估搭载GPGPU(General Purpose GPU)的AI服务器年出货量占整体服务器比重近1%,预估在ChatBot相关应用加持下,有望再度推动AI相关领域的发展,预估出货量年成长可达8%;2022~2026年复合成长率将达10.8%。
AI服务器是异构服务器,可以根据应用范围采用不同的组合方式,如CPU + GPU、CPU + TPU、CPU +其他加速卡等。IDC预计,中国AI服务器2021年的市场规模为57亿美元,同比增长61.6%,到2025年市场规模将增长到109亿美元,CAGR为17.5%。
8、AI服务器构成及形态
以浪潮NF5688M6 服务器为例,其采用NVSwitch实现GPU跨节点P2P高速通信互联。整机8 颗 NVIDIAAmpere架构 GPU,通过NVSwitch实现GPU跨节点P2P高速通信互联。配置 2颗第三代Intel(R) Xeon(R) 可扩展处理器(Ice Lake),支持8块2.5英寸NVMe SSD orSATA/SAS SSD以及板载2块 SATA M.2,可选配1张PCIe 4.0 x16 OCP 3.0网卡,速率支持10G/25G/100G;可支持10个PCIe 4.0 x16插槽, 2个PCIe 4.0 x16插槽(PCIe 4.0 x8速率), 1个OCP3.0插槽;支持32条DDR4RDIMM/LRDIMM内存,速率最高支持3200MT/s,物理结构还包括6块3000W 80Plus铂金电源、N+1冗余热插拔风扇、机箱等。
目前按照GPU数量的不同,有4颗GPU(浪潮NF5448A6)、8颗GPU(Nvidia A100 640GB)以及16颗GPU(NVIDIA DGX-2)的AI服务器。
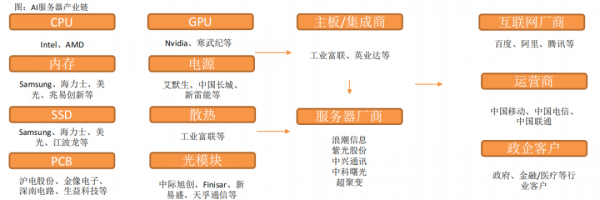
9、AI服务器产业链
AI服务器核心组件包括GPU(图形处理器)、DRAM(动态随机存取存储器)、SSD(固态硬盘)和RAID卡、CPU(中央处理器)、网卡、PCB、高速互联芯片(板内)和散热模组等。
-
CPU主要供货厂商为Intel、GPU目前领先厂商为国际巨头英伟达,以及国内厂商如寒武纪、海光信息等。 -
内存主要为三星、美光、海力士等厂商,国内包括兆易创新等。 -
SSD厂商包括三星、美光、海力士等,以及国内江波龙等厂商。 -
PCB厂商海外主要包括金像电子,国内包括沪电股份、鹏鼎控股等。 -
主板厂商包括工业富联,服务器品牌厂商包括浪潮信息、紫光股份、中科曙光、中兴通讯等。
10、AI服务器竞争格局
IDC发布了《2022年第四季度中国服务器市场跟踪报告Prelim》。从报告可以看到,前两名浪潮与新华三的变化较小,第三名为超聚变,从3.2%份额一跃而至10.1%,增幅远超其他服务器厂商。Top8服务器厂商中,浪潮、戴尔、联想均出现显著下滑,超聚变和中兴则取得明显增长。其中,浪潮份额从30.8%下降至28.1%;新华三份额从17.5%下降至17.2%;中兴通讯(000063)从3.1%提升至5.3%,位居国内第5。联想降幅最为明显,从7.5%下降至4.9%。
据TrendForce集邦咨询统计,2022年AI服务器采购占比以北美四大云端业者Google、AWS、Meta、Microsoft合计占66.2%为最,而中国近年来随着国产化力道加剧,AI建设浪潮随之增温,以ByteDance的采购力道最为显著,年采购占比达6.2%,其次紧接在后的则是Tencent、Alibaba与Baidu,分别约为2.3%、1.5%与1.5%。
国内AI服务器竞争厂商包括:浪潮信息、新华三、超聚变、中兴通讯等。
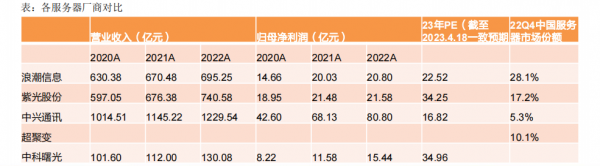
服务器主要厂商包括:工业富联、浪潮信息、超聚变、紫光股份(新华三)、中兴通讯、中科曙光。
AI服务器目前领先厂商为工业富联和浪潮信息,浪潮信息在阿里、腾讯、百度AI服务器占比高达90%。
紫光股份在 GPU 服务器市场处于领先地位,有各种类型的 GPU 服务器满足各种 AI 场景应用。特别针对 GPT 场景而优化的 GPU 服务器已经完成开发,并取得 31 个世界领先的测试指标,该新一代系列 GPU 服务器将在今年二季度全面上市。
来源:架构师技术联盟
好文章,需要你的鼓励



明尼苏达大学最新研究颠覆认知:训练AI大模型,只需动其中一层就够了?
这项来自明尼苏达大学等机构的研究发现,大语言模型在强化学习后训练中,只需训练中间少数几层即可匹配甚至超越全参数训练效果,且这一规律跨模型、跨任务高度稳定,为更高效的AI训练策略提供了新思路。


台湾大学与NVIDIA揭秘:你的声音正在悄悄改变AI对你的判断
本文介绍VIBE框架,一套通过开放式任务评估大型音频语言模型声音诱发偏见的系统,测试12个模型后发现每个模型均存在显著性别或口音偏见。
2024
04/16
01:04
分享
点赞

