
重磅!Llama-3,最强开源大模型正式发布!
4月19日,全球科技、社交巨头Meta在官网,正式发布了开源大模型——Llama-3。
据悉,Llama-3共有80亿、700亿两种参数,分为基础预训练和指令微调两种模型(还有一个超4000亿参数正在训练中)。
与Llama-2相比,Llama-3使用了15T tokens的训练数据,在推理、数学、代码生成、指令跟踪等能力获得大幅度提升。
此外,Llama-3还使用了分组查询注意力、掩码等创新技术,帮助开发者以最低的能耗获取绝佳的性能。很快,Meta就会发布Llama-3的论文。
开源地址:https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
Github地址:https://github.com/meta-llama/llama3/
英伟达在线体验Llama-3:https://www.nvidia.com/en-us/ai/#referrer=ai-subdomain

「AIGC开放社区」曾在今年3月13日,根据Llama-3的硬件设施和训练速度,预测其将于4月末发布果然被说中了。
但首发的Llama-3虽然在性能上获得大幅度提升,功能上却没有带来太多的惊喜,例如,将类Sora的视频,或者Suno那样的音频功能内置在模型中,通过文本直接生成。
其实,Meta已经发布了很多音频、视频还有图像的产品和研究论文,想整合它们估计只是时间问题。我们就期待一下Llama-3可以在未来几个月,带来更多的亮眼功能吧。
Llama-3简单介绍
本次Llama-3的介绍与前两个版本差不多,大量的测试数据和格式化介绍。但Meta特意提到Llama-3使用了掩码和分组查询注意力这两项技术。
目前,大模型领域最流行的Transformer架构的核心功能是自我注意力机制,这是一种用于处理序列数据的技术,可对输入序列中的每个元素进行加权聚合,以捕获元素之间的重要关系。
Llama-3介绍
但在使用自我注意力机制时,为了确保模型不会跨越文档边界,通常会与掩码技术一起使用。在自我注意力中,掩码被应用于注意力权重矩阵,用于指示哪些位置的信息是有效的,哪些位置应该被忽略。
通常当处理文档边界时,可以使用两种类型的掩码来确保自我注意力不会跨越边界:1)填充掩码,当输入序列的长度不一致时,通常会对较短的序列进行填充,使其与最长序列的长度相等。
填充掩码用于标记填充的位置,将填充的部分掩盖,使模型在自我注意力计算中忽略这些位置。
2)未来掩码,在序列生成任务中,为了避免模型在生成当前位置的输出时依赖后续位置的信息,可以使用未来掩码。
未来掩码将当前位置之后的位置都掩盖起来,使得自我注意力只能关注当前或之前的位置。
此外,在Transformer自注意力机制中,每个查询都会计算与所有键的相似度并进行加权聚合。
而在分组查询注意力中,将查询和键分组,并将注意力计算限制在每个查询与其对应组的键之间,从而减少了模型计算的复杂度。
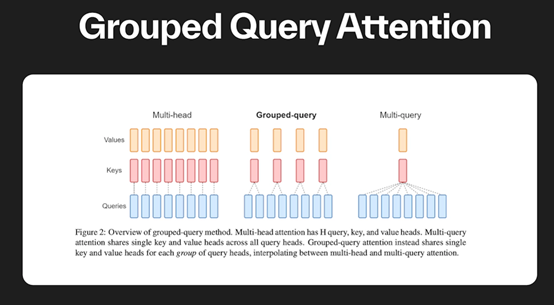
由于减少了计算复杂度,分组查询注意力使得大模型更容易扩展到处理更长的序列或更大的批次大小。这对于处理大规模文本数据或需要高效计算的实时应用非常有益。
同时分组查询注意力允许在每个查询和其对应组的键之间进行关注的计算,从而控制了注意力的范围。这有助于模型更准确地捕捉查询和键之间的依赖关系,提高了表示能力。
Meta表示,Llama-3 还使用了一个 128K的词汇表标记器,能更有效地编码语言,在处理语言时也更加灵活。
训练数据方面,lama 3 在超过 15T tokens的公开数据集上进行了预训练。这个训练数据集是 Llama 2 的7倍,包含的代码数量也是 Llama 2 的4倍。
为了实现多语言能力,Llama 3 的预训练数据集中有超过 5% 的高质量非英语数据,涵盖 30 多种语言。
Llama-3测试数据
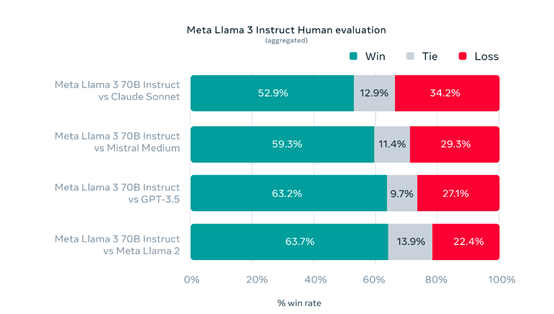
为了测试Llama-3的性能,Meta开发了一个全新的高质量人类评估数据集,有1,800个提示,涵盖12个关键用例,包含,征求建议,头脑风暴,分类,封闭式问题回答,编码,推理等。
测试结果显示,Llama-3 -700亿参数的指令微调模型的性能,大幅度超过了Claude Sonnet、Mistral Medium和GPT-3.5。
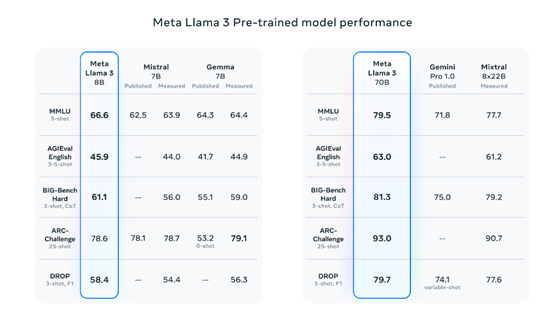
Meta还在MMLU、AGIEval、BIG、ARC等知名测试平台中,对Llama-3 -700亿参数基础预训练模型进行了综合测试,性能大幅度超过了Mistral 7B、Gemma 7B、Gemini Pro 1.0等知名开源模型。
好文章,需要你的鼓励


OpenAI发布ChatGPT Work平台并扩大GPT-5.6部署范围
OpenAI推出企业级智能体平台ChatGPT Work,可跨应用自动执行多步骤工作任务,生成文档、演示文稿及电子表格等业务内容。同步推出的GPT-5.6系列模型涵盖Sol、Terra、Luna三档,主打"更低成本、更强性能"。Sol在编码、网络安全及复杂推理基准测试中表现突出,定价为每百万输入tokens 5美元。新模型还支持Microsoft 365、Google Drive等企业应用集成,并引入max与ultra两种推理模式以应对复杂工作负载。

当AI学会“挑剔“:斯坦福与伯克利联手打造的智能验证框架,让AI自己检验自己的答案
斯坦福与UC伯克利提出LLM-as-a-Verifier框架,通过提取AI模型内部概率分布生成连续评分,在代码、机器人、医疗领域均达到最优性能,且无需额外训练。

DJI发布AP100降落伞,为Matrice 400无人机提供紧急安全保障
大疆发布AP100降落伞,专为旗舰级Matrice 400企业无人机设计。该配件重约935克,支持自动与手动两种部署方式,可在600毫秒内触发展开,将无人机下降速度控制在每秒5米以内。AP100作为独立安全模块运行,配备独立飞控、传感器及备用电容,断电后仍可持续工作一小时。此外,内置飞行终止系统可在展开前切断电机,防止螺旋桨缠绕。该配件还支持欧盟EASA和英国CAA的C5/C6等级合规认证,适用于超视距飞行任务,防护等级IP55,适应-20°C至50°C宽温环境。

字节跳动Seed团队发现:AI智能体学习新任务的速度,正以每三个月翻倍的惊人节奏增长
字节跳动Seed团队发现AI智能体在真实环境中学习的进步曲线精确遵循对数S形规律,R?达0.998,且前沿模型的学习速度每三个月翻倍。
2024
04/24
13:04
分享
点赞

