
微软开源最强小参数大模型—Phi-3 Mini
4月23日晚,微软在官网开源了小参数的大语言模型——Phi-3-mini。
据悉,Phi-3-mini是微软Phi家族的第4代,有预训练和指令微调多种模型,参数只有38亿训练数据却高达3.3T tokens,比很多数百亿参数的模型训练数据都要多,这也是其性能超强的主要原因之一。
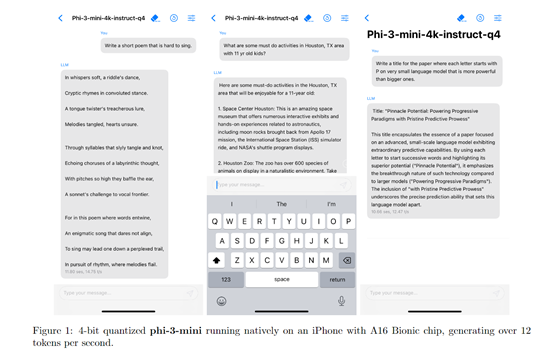
Phi-3-mini对内存的占用极少,可以在 iPhone 14等同类手机中部署使用该模型。尽管受到移动硬件设备的限制,但每秒仍能生成12 个tokens数据。
值得一提的是,微软在预训练Phi-3-mini时使用了合成数据,能帮助大模型更好地理解语言架构、表达方式、文本语义理解、逻辑推理以及特定业务场景的专业术语等。
开源地址:https://huggingface.co/collections/microsoft/phi-3-6626e15e9585a200d2d761e3
Ollama地址:https://ollama.com/library/phi3
技术报告:https://arxiv.org/abs/2404.14219
2023年6月,微软首次推出了专用于Python编码的模型Phi-1,只有13亿参数却在编程领域击败了GPT-3.5等知名模型,这让微软看到小参数模型的广阔发展空间。
随后在Phi-1基础之上,微软推出了具备推理、文本生成、内容总结、起草邮件的大语言模型Phi-1.5,成为当时最强小参数模型之一。
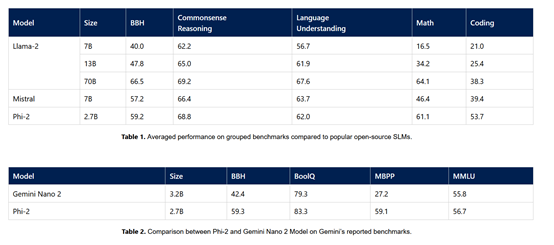
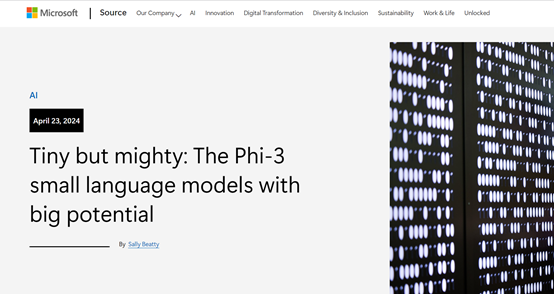
2023年12月,微软在Phi-1.5基础之上开发了Phi-2,参数只有27亿并且在没有人类反馈强化学习和指令微调的情况下,击败了130亿参数的Llama-2和70亿参数的Mistral;在编码和数学测试中,Phi-2的性能甚至超过了700亿参数的Llama-2。
本次发布的Phi-3系列集合了之前三代所有的优秀技术特征,并使用了海量高质量数据集、创新的训练、微调方法,使其成为目前最强的开源小参数模型。
Phi-3-mini架构简单介绍
Phi-3-mini采用了transformer架构,支持4K和128K上下文窗口,也是同类小模型中第一个支持128K的开源产品。
高质量训练数据集是Phi-3-mini性能超强的重要原因之一,微软使用了3.3T tokens数据集包括:经过严格质量筛选的网络公开文档、精选的高质量教育数据和编程代码;
通过合成数据创建的教科书式数据,例如,数学、编码、常识推理、世界常识、心理科学等;
高质量聊天格式的监督数据,涵盖各种主题以反映人类在不同方面的偏好,例如,遵循指令、真实性、诚实性等。
在训练策略方面,为了帮助Phi-3-mini更好地吸收合成数据,微软使用了迭代训练策略:初始阶段,Phi-3-mini使用了公开网络数据,学会了基本的语法、语义和上下文理解;
迭代阶段,将合成数据与网络数据合并构建全新的训练集,并对Phi-3-mini进行迭代训练,进一步强化模型的理解和生成能力,并且进行多次重复训练。
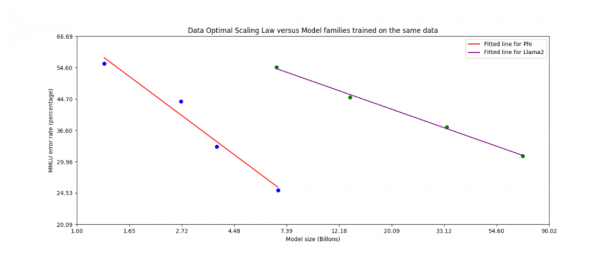
测试数据方面,Phi-3 Mini在MMLU、GSM-8K、MedQA、BigBench-Hard等知名基准测试平台中,对语言理解、逻辑推理、机器翻译、编码等进行了综合测试。
结果显示,Phi-3-mini仅通过少量样本提示,在语言理解、编码、数学的性能超过了参数更大的模型,整体性能非常出色。
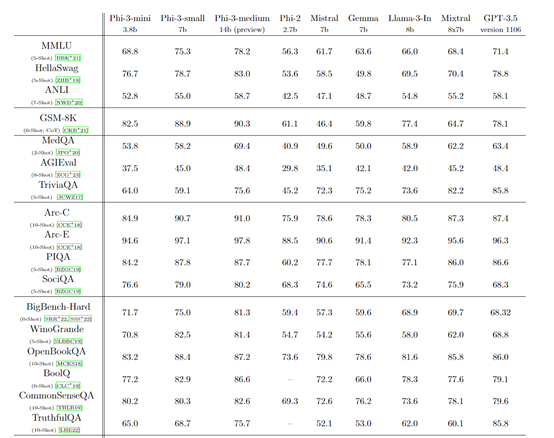
微软表示,在未来几周内还会发布70亿参数的Phi-3-small和140亿参数的Phi-3-medium两款小模型。其中,Phi-3-medium的性能可媲美Mixtral 8x7B 和GPT-3.5,资源消耗却更少。

本文素材来源微软官网、Phi-3论文,如有侵权请联系删除
来源:AIGC开放社区
好文章,需要你的鼓励

英国NHS无人机快递医疗样本服务正式落地伦敦
英国国家医疗服务(NHS)正将无人机纳入常规医疗物流体系。自今年2月起,无人机每天在雷恩斯公园和圣乔治医院之间运送血液等诊断样本,飞行仅需3分钟,比公路运输快约85%,且碳排放减少高达98%。目前已有逾2000名患者受益。NHS计划将该服务扩展至圣赫利尔、克罗伊登等多家医院,最终惠及约180万名患者。该网络由英国医疗初创公司Apian与谷歌旗下Wing合作运营。

Explyt团队打造的代码智能体评测新标准:光靠“通过/失败“根本不够用
AgentLens是Explyt公司联合俄罗斯学术机构开发的AI编程助手评测基准,通过分析完整人机交互轨迹而非仅看最终结果,从五个维度评估代码智能体的真实表现。

Aetina宣布支持英伟达Jetson T3000和T2000 AI模块
边缘AI计算厂商Aetina宣布,将在其DeviceEdge AIE-KT风冷系列和新款AIE-PT无风扇平台上支持英伟达全新Jetson T3000和T2000模块。T3000基于Blackwell GPU,最高提供865 FP4 TFLOPS算力,功耗70W;T2000则提供400 FP4 TFLOPS,面向视觉AI代理和自主移动机器人等场景。两款模块预计2027年第一季度上市,支持Nemotron、Cosmos 3等英伟达AI软件生态。

机器人的“触觉觉醒“:韩国梨花女子大学如何让小型AI模型在不忘记视觉的前提下学会“感受“材质
韩国梨花女子大学提出Splash框架,通过识别AI模型中的"休眠参数"并只在其中训练触觉能力,让小型多模态AI在学会感知材质触感的同时,完整保留原有视觉语言推理能力。
2024
04/24
22:04
分享
点赞

