
OpenAI下周将发布ChatGPT搜索引擎,挑战谷歌搜索!
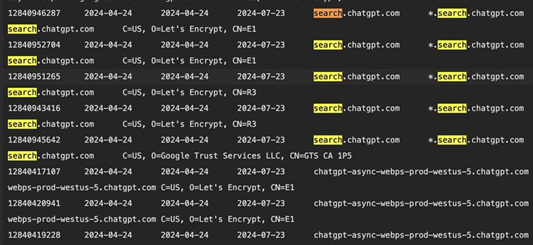
5月3日,前Mila研究员、麻省理工讲师Lior S爆料,根据OpenAI最新的SSL证书日志显示,已经创建了search.chatgpt.com子域名(目前无法访问),将会进军搜索引擎全面挑战该领域的全球霸主谷歌。
比较巧的是,OpenAI已经更新了网站主页,第一个轮番页是一个搜索框上面写着“向ChatGPT问任何事情”。再结合theinformation在今年2月14日的新闻,OpenAI正在秘密研发一款ChatGPT支持的web搜索引擎,这个事情还是挺靠谱的。
目前,多方位消息证实,OpenAI将会在5月9日上午10点公布该消息,大约是北京时间周五的凌晨2点。
OpenAI抢在5月9日发布这个消息也挺有意思,因为5月14日谷歌将举行一年一度的“Google I/O”大会,OpenAI不希望谷歌的技术大会抢了该产品的风头。
早在今年2月14日,著名科技媒体theinformation独家消息显示,OpenAI会联手微软的Bing研发一款网络搜索引擎来挑战谷歌。
目前,全球前五搜索引擎分别是谷歌、Bing、雅虎、百度和Yandex,而谷歌的市场份额占到了90%左右,几乎垄断了整个市场,出道即巅峰至今几十年从未遇到过对手。
但OpenAI进军搜索引擎的消息放出后,不少人认为,谷歌这次是碰到硬茬了。
这是因为谷歌搜索引擎虽然经过几十年的技术积累和迭代,在市场影响力、用户积累方面处于领导地位,但在技术层面和用户使用体验方面仍然有很多问题。
广告太多,这个问题已经被用户抱怨了十几年。用户通过谷歌搜索一些内容,10个链接里大概有5个广告非常影响用户体验,并且很多是虚假广告。
死链、过时链接和数据更新太慢,谷歌搜索结果中存在大量死链和过时的链接,致使用户访问无效的网页浪费时间。
关键字匹配有局限性,无法深度理解上下文搜索,传统搜索引擎主要依赖于关键词匹配来返回搜索结果。
这种方法可能会忽略文本的语义和上下文,导致搜索结果不够精准。例如,当用户搜索"苹果"时,搜索结果可能会包含苹果公司、苹果产品、苹果水果等内容,而用户可能只对其中某一类方面感兴趣。
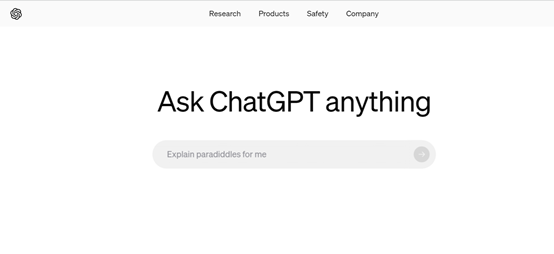 OpenAI最新首页
OpenAI最新首页
个性化搜索,谷歌的个性化搜索可以为用户提供量身定制的搜索服务(有点类似抖音的推荐机制),例如,兴趣、常看的内容等,但也会出现“过滤泡沫”的情况。
就是用户只能看到与自己观点一致的信息,限制了信息的多样性和视野的广阔性,长此以往会形成“信息茧房”,把用户困在自己的世界里。
数据隐私,上面提到的个性化搜索,就是谷歌根据用户的搜索历史和行为数据来完成的,所以,用户的很多私密数据会被搜集或用于商业广告精准投放。
 微软的Copilot搜索
微软的Copilot搜索
那么大模型厂商来搞搜索引擎到底靠不靠谱呢?微软的Bing(现在改名为Copilot)一直是搜索引擎领域的千年老二,但存在感不强。
去年,Bing在OpenAI的GPT-4模型加持下其搜索能力、市场用户、营收等迎来一波井喷式增长。尤其是全球用户突破1亿大关,这充分说明用户对大模型加持的搜索引擎认可。
此外,前不久获得6270万美元,估值10.4亿美元的纯大模型搜索引擎Perplexity AI也证实了很有搞头,并且获得了资本市场的认可。
Perplexity AI提供了一个搜索框,可以像谷歌搜索引擎那样输入我们想搜索的东西。
例如,人感冒的时候如何才能快速恢复?Perplexity 会列出6个文本内容,并附带真实的网站地址。这一点很重要,是在告诉用户它说的内容是真实、可靠的。但如果源地址是错误的,也会影响大模型结果的输出。
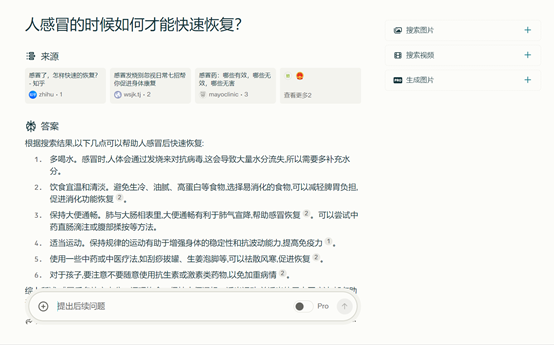
此外,Perplexity还能提供图片、视频搜索以及图片的生成,这些功能与微软的Bing几乎差不多。在OpenAI正式加入搜索引擎赛道后,谷歌要如何回应呢?让我们拭目以待吧。
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2024
05/07
15:04
分享
点赞

