
阿里云发布通义千问2.5,性能全面赶超GPT-4 Turbo
5月9日消息,阿里云正式发布通义千问2.5,模型性能全面赶超GPT-4 Turbo,成为地表最强中文大模型。同时,通义千问最新开源的1100亿参数模型在多个基准测评收获最佳成绩,超越Meta的Llama-3-70B,成为开源领域最强大模型。

相比通义千问2.1版本,通义千问2.5的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%,中文能力更是持续领先业界。在权威基准OpenCompass上,通义千问2.5得分追平GPT-4 Turbo,是该基准首次录得国产大模型取得如此出色的成绩。

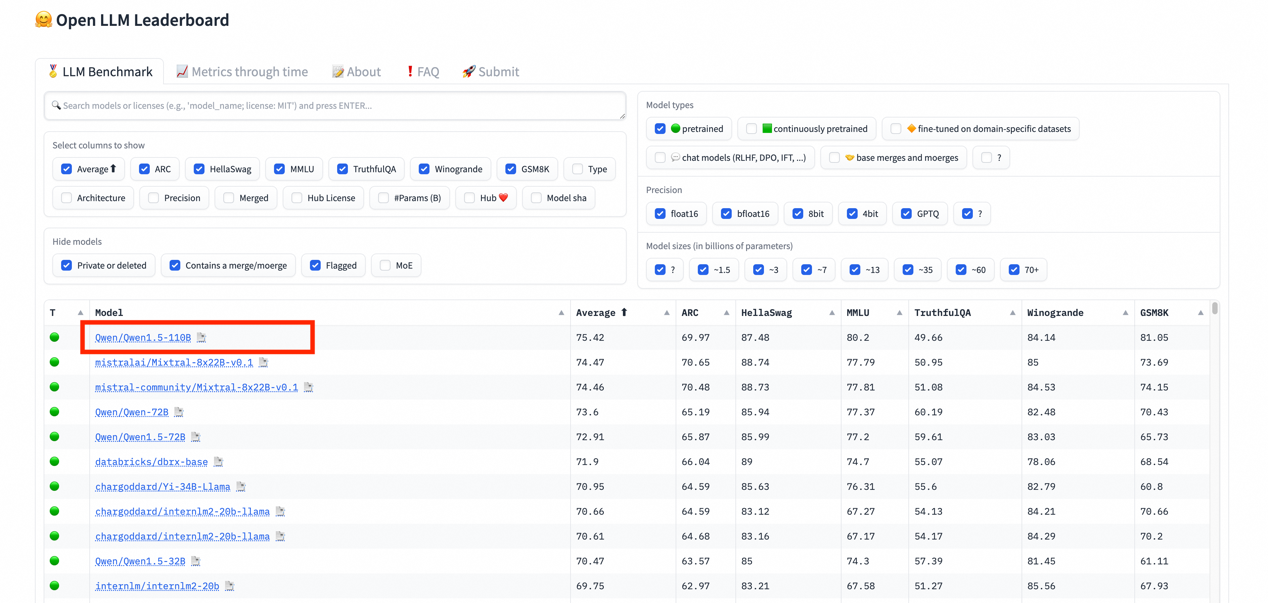
通义还发布了最新款开源模型,1100亿参数的Qwen1.5-110B,该模型在MMLU、TheoremQA、GPQA等基准测评中超越了Meta的Llama-3-70B模型;在HuggingFace推出的开源大模型排行榜Open LLM Leaderboard上,Qwen1.5-110B冲上榜首,再度证明通义开源系列业界最强的竞争力。
通义的多模态模型和专有能力模型也具备业界顶尖影响力。通义千问视觉理解模型Qwen-VL-Max在多个多模态标准测试中超越Gemini Ultra和GPT-4V,目前已在多家企业落地应用;通义千问代码大模型CodeQwen1.5-7B则是HuggingFace代码模型榜单Big Code的头名选手,还是国内用户规模第一的智能编码助手通义灵码的底座。
通义大模型问世一年多来,还发展出了业界领先的文生图、智能编码、文档解析、音视频理解等能力,企业客户和开发者可以通过API调用、模型下载等方式接入通义,个人用户可从通义APP、官网和小程序免费使用通义家族全栈服务。
好文章,需要你的鼓励


“借道”MoP封装,AMD打破“存储墙”与“空间锁”
AMD 最近推出了第二代 AMD Versal Premium MoP(Memory on Package,封装上内存)自适应SoC。

清华&OPPO联合打造的“智能侦探“:当AI学会主动追查证据,视觉问答准确率飙升27%
ProMSA是由清华大学与OPPO联合提出的视觉问答智能体,通过自适应切换图像和文字检索工具、多轮渐进式搜索,在E-VQA和InfoSeek上超越现有方法。


蚂蚁集团打造的AI“安全警卫“:当智能助手学会看图识险,多模态内容审核迎来新突破
蚂蚁集团AI安全实验室开发的SingGuard是一套多模态内容安全审核系统,能同时理解图片与文字的组合意图,并支持运行时动态传入自定义规则,实现策略自适应的安全判断。
2024
05/09
11:34
分享
点赞

“借道”MoP封装,AMD打破“存储墙”与“空间锁”
优必选万台超仿生人形机器人,要在今年进家庭?
Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Origin PC Millennium台式机评测:构建出色但配置并非最优选择
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
